 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Ownership Verification for Pre-trained Masked Models
Jul 16, 2025High-quality open-source datasets have emerged as a pivotal catalyst driving the swift advancement of deep learning, while facing the looming threat of potential exploitation. Protecting these datasets is of paramount importance for the interests of their owners. The verification of dataset ownership has evolved into a crucial approach in this domain; however, existing verification techniques are predominantly tailored to supervised models and contrastive pre-trained models, rendering them ill-suited for direct application to the increasingly prevalent masked models. In this work, we introduce the inaugural methodology addressing this critical, yet unresolved challenge, termed Dataset Ownership Verification for Masked Modeling (DOV4MM). The central objective is to ascertain whether a suspicious black-box model has been pre-trained on a particular unlabeled dataset, thereby assisting dataset owners in safeguarding their rights. DOV4MM is grounded in our empirical observation that when a model is pre-trained on the target dataset, the difficulty of reconstructing masked information within the embedding space exhibits a marked contrast to models not pre-trained on that dataset. We validated the efficacy of DOV4MM through ten masked image models on ImageNet-1K and four masked language models on WikiText-103. The results demonstrate that DOV4MM rejects the null hypothesis, with a $p$-value considerably below 0.05, surpassing all prior approaches. Code is available at https://github.com/xieyc99/DOV4MM.
On the Evaluation Consistency of Attribution-based Explanations
Jul 28, 2024
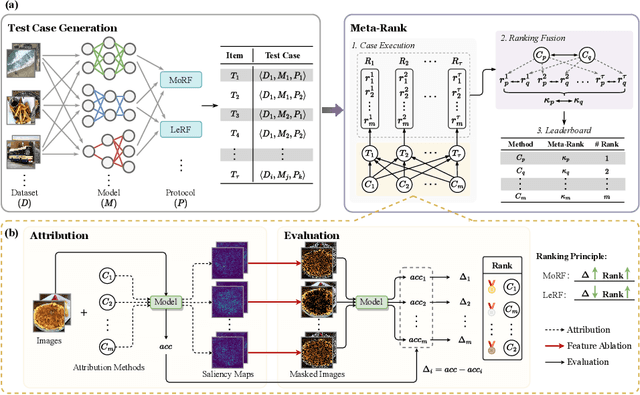
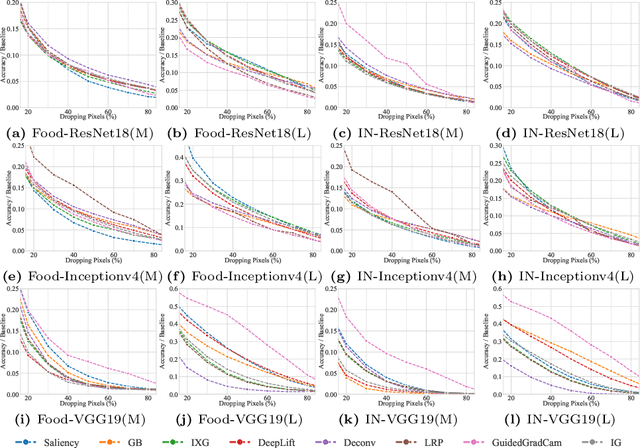
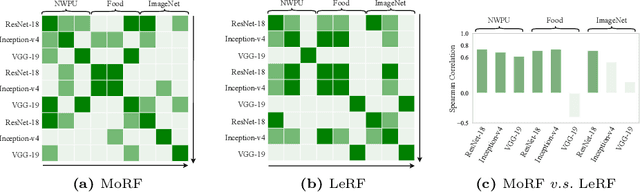
Attribution-based explanations are garnering increasing attention recently and have emerged as the predominant approach towards \textit{eXplanable Artificial Intelligence}~(XAI). However, the absence of consistent configurations and systematic investigations in prior literature impedes comprehensive evaluations of existing methodologies. In this work, we introduce {Meta-Rank}, an open platform for benchmarking attribution methods in the image domain. Presently, Meta-Rank assesses eight exemplary attribution methods using six renowned model architectures on four diverse datasets, employing both the \textit{Most Relevant First} (MoRF) and \textit{Least Relevant First} (LeRF) evaluation protocols. Through extensive experimentation, our benchmark reveals three insights in attribution evaluation endeavors: 1) evaluating attribution methods under disparate settings can yield divergent performance rankings; 2) although inconsistent across numerous cases, the performance rankings exhibit remarkable consistency across distinct checkpoints along the same training trajectory; 3) prior attempts at consistent evaluation fare no better than baselines when extended to more heterogeneous models and datasets. Our findings underscore the necessity for future research in this domain to conduct rigorous evaluations encompassing a broader range of models and datasets, and to reassess the assumptions underlying the empirical success of different attribution methods. Our code is publicly available at \url{https://github.com/TreeThree-R/Meta-Rank}.
Bootstrapping ViTs: Towards Liberating Vision Transformers from Pre-training
Dec 09, 2021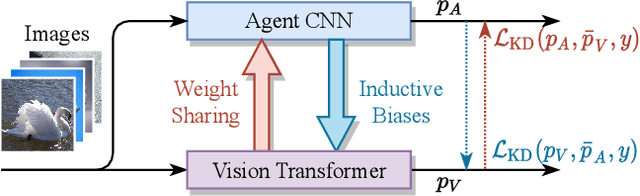
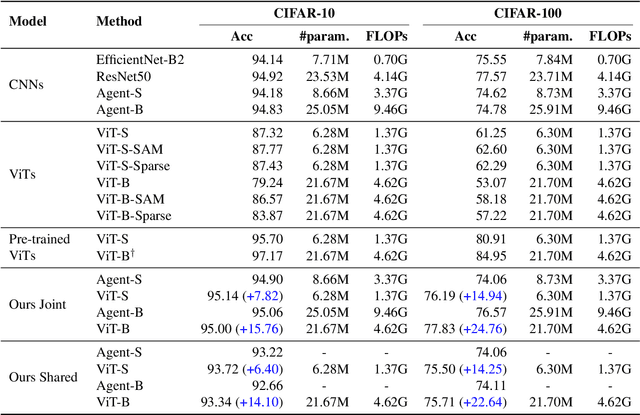

Recently, vision Transformers (ViTs) are developing rapidly and starting to challenge the domination of convolutional neural networks (CNNs) in the realm of computer vision (CV). With the general-purpose Transformer architecture for replacing the hard-coded inductive biases of convolution, ViTs have surpassed CNNs, especially in data-sufficient circumstances. However, ViTs are prone to over-fit on small datasets and thus rely on large-scale pre-training, which expends enormous time. In this paper, we strive to liberate ViTs from pre-training by introducing CNNs' inductive biases back to ViTs while preserving their network architectures for higher upper bound and setting up more suitable optimization objectives. To begin with, an agent CNN is designed based on the given ViT with inductive biases. Then a bootstrapping training algorithm is proposed to jointly optimize the agent and ViT with weight sharing, during which the ViT learns inductive biases from the intermediate features of the agent. Extensive experiments on CIFAR-10/100 and ImageNet-1k with limited training data have shown encouraging results that the inductive biases help ViTs converge significantly faster and outperform conventional CNNs with even fewer parameters.