 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Token Reduction for Large Vision-Language Models
Mar 23, 2026Large Vision-Language Models (LVLMs) excel in visual understanding and reasoning, but the excessive visual tokens lead to high inference costs. Although recent token reduction methods mitigate this issue, they mainly target single-turn Visual Question Answering (VQA), leaving the more practical multi-turn VQA (MT-VQA) scenario largely unexplored. MT-VQA introduces additional challenges, as subsequent questions are unknown beforehand and may refer to arbitrary image regions, making existing reduction strategies ineffective. Specifically, current approaches fall into two categories: prompt-dependent methods, which bias toward the initial text prompt and discard information useful for subsequent turns; prompt-agnostic ones, which, though technically applicable to multi-turn settings, rely on heuristic reduction metrics such as attention scores, leading to suboptimal performance. In this paper, we propose a learning-based prompt-agnostic method, termed MetaCompress, overcoming the limitations of heuristic designs. We begin by formulating token reduction as a learnable compression mapping, unifying existing formats such as pruning and merging into a single learning objective. Upon this formulation, we introduce a data-efficient training paradigm capable of learning optimal compression mappings with limited computational costs. Extensive experiments on MT-VQA benchmarks and across multiple LVLM architectures demonstrate that MetaCompress achieves superior efficiency-accuracy trade-offs while maintaining strong generalization across dialogue turns. Our code is available at https://github.com/MArSha1147/MetaCompress.
Beyond Matching to Tiles: Bridging Unaligned Aerial and Satellite Views for Vision-Only UAV Navigation
Mar 23, 2026Recent advances in cross-view geo-localization (CVGL) methods have shown strong potential for supporting unmanned aerial vehicle (UAV) navigation in GNSS-denied environments. However, existing work predominantly focuses on matching UAV views to onboard map tiles, which introduces an inherent trade-off between accuracy and storage overhead, and overlooks the importance of the UAV's heading during navigation. Moreover, the substantial discrepancies and varying overlaps in cross-view scenarios have been insufficiently considered, limiting their generalization to real-world scenarios. In this paper, we present Bearing-UAV, a purely vision-driven cross-view navigation method that jointly predicts UAV absolute location and heading from neighboring features, enabling accurate, lightweight, and robust navigation in the wild. Our method leverages global and local structural features and explicitly encodes relative spatial relationships, making it robust to cross-view variations, misalignment, and feature-sparse conditions. We also present Bearing-UAV-90k, a multi-city benchmark for evaluating cross-view localization and navigation. Extensive experiments show encouraging results that Bearing-UAV yields lower localization error than previous matching/retrieval paradigm across diverse terrains. Our code and dataset will be made publicly available.
$D^3$-RSMDE: 40$\times$ Faster and High-Fidelity Remote Sensing Monocular Depth Estimation
Mar 17, 2026Real-time, high-fidelity monocular depth estimation from remote sensing imagery is crucial for numerous applications, yet existing methods face a stark trade-off between accuracy and efficiency. Although using Vision Transformer (ViT) backbones for dense prediction is fast, they often exhibit poor perceptual quality. Conversely, diffusion models offer high fidelity but at a prohibitive computational cost. To overcome these limitations, we propose Depth Detail Diffusion for Remote Sensing Monocular Depth Estimation ($D^3$-RSMDE), an efficient framework designed to achieve an optimal balance between speed and quality. Our framework first leverages a ViT-based module to rapidly generate a high-quality preliminary depth map construction, which serves as a structural prior, effectively replacing the time-consuming initial structure generation stage of diffusion models. Based on this prior, we propose a Progressive Linear Blending Refinement (PLBR) strategy, which uses a lightweight U-Net to refine the details in only a few iterations. The entire refinement step operates efficiently in a compact latent space supported by a Variational Autoencoder (VAE). Extensive experiments demonstrate that $D^3$-RSMDE achieves a notable 11.85% reduction in the Learned Perceptual Image Patch Similarity (LPIPS) perceptual metric over leading models like Marigold, while also achieving over a 40x speedup in inference and maintaining VRAM usage comparable to lightweight ViT models.
Semi-supervised Latent Disentangled Diffusion Model for Textile Pattern Generation
Mar 17, 2026Textile pattern generation (TPG) aims to synthesize fine-grained textile pattern images based on given clothing images. Although previous studies have not explicitly investigated TPG, existing image-to-image models appear to be natural candidates for this task. However, when applied directly, these methods often produce unfaithful results, failing to preserve fine-grained details due to feature confusion between complex textile patterns and the inherent non-rigid texture distortions in clothing images. In this paper, we propose a novel method, SLDDM-TPG, for faithful and high-fidelity TPG. Our method consists of two stages: (1) a latent disentangled network (LDN) that resolves feature confusion in clothing representations and constructs a multi-dimensional, independent clothing feature space; and (2) a semi-supervised latent diffusion model (S-LDM), which receives guidance signals from LDN and generates faithful results through semi-supervised diffusion training, combined with our designed fine-grained alignment strategy. Extensive evaluations show that SLDDM-TPG reduces FID by 4.1 and improves SSIM by up to 0.116 on our CTP-HD dataset, and also demonstrate good generalization on the VITON-HD dataset.
Reinforced Model Merging
Mar 27, 2025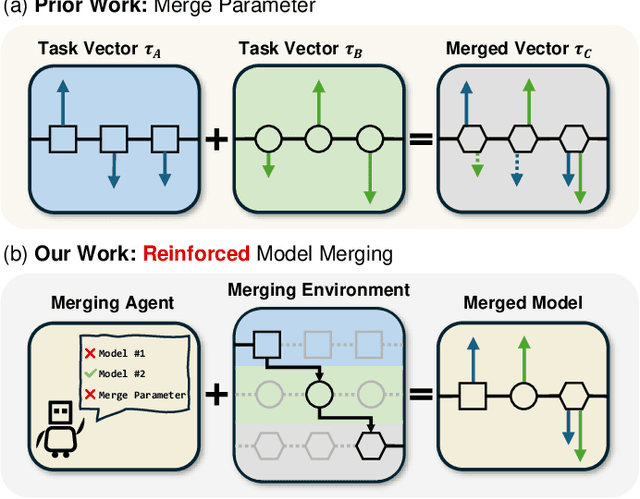
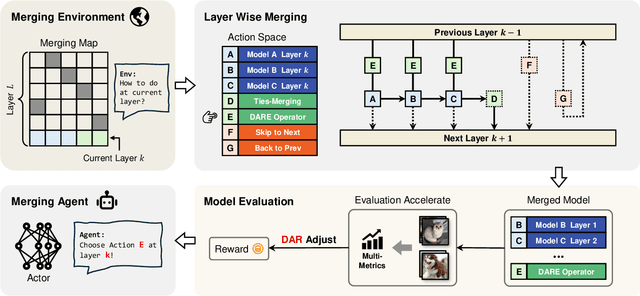
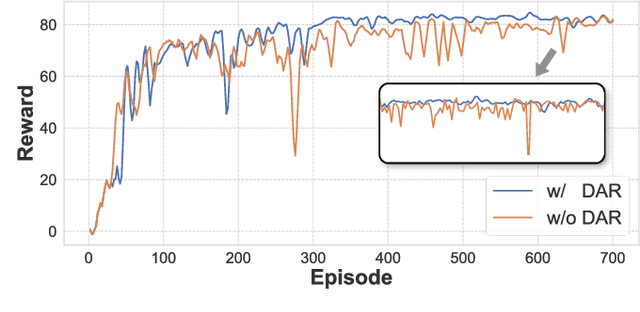
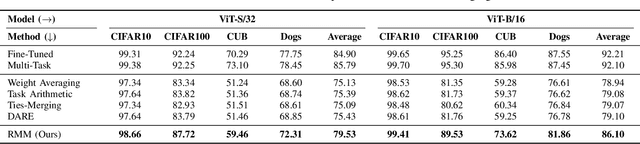
The success of large language models has garnered widespread attention for model merging techniques, especially training-free methods which combine model capabilities within the parameter space. However, two challenges remain: (1) uniform treatment of all parameters leads to performance degradation; (2) search-based algorithms are often inefficient. In this paper, we present an innovative framework termed Reinforced Model Merging (RMM), which encompasses an environment and agent tailored for merging tasks. These components interact to execute layer-wise merging actions, aiming to search the optimal merging architecture. Notably, RMM operates without any gradient computations on the original models, rendering it feasible for edge devices. Furthermore, by utilizing data subsets during the evaluation process, we addressed the bottleneck in the reward feedback phase, thereby accelerating RMM by up to 100 times. Extensive experiments demonstrate that RMM achieves state-of-the-art performance across various vision and NLP datasets and effectively overcomes the limitations of the existing baseline methods. Our code is available at https://github.com/WuDiHJQ/Reinforced-Model-Merging.
Dataset Ownership Verification in Contrastive Pre-trained Models
Feb 11, 2025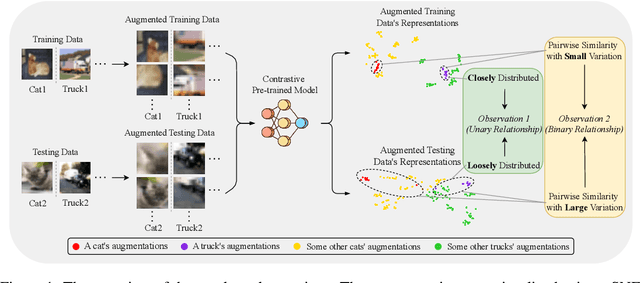
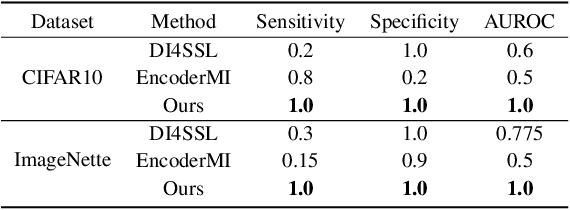
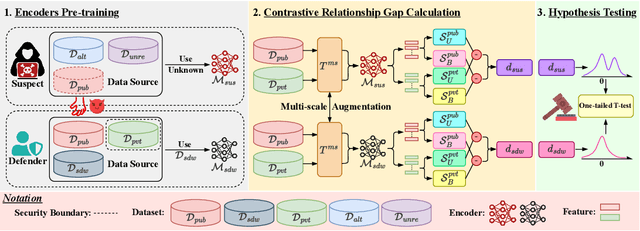
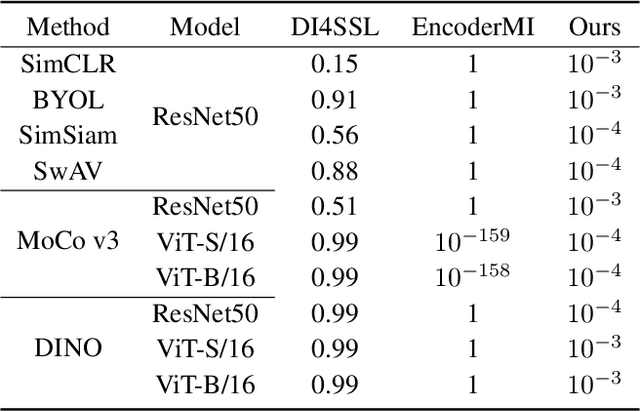
High-quality open-source datasets, which necessitate substantial efforts for curation, has become the primary catalyst for the swift progress of deep learning. Concurrently, protecting these datasets is paramount for the well-being of the data owner. Dataset ownership verification emerges as a crucial method in this domain, but existing approaches are often limited to supervised models and cannot be directly extended to increasingly popular unsupervised pre-trained models. In this work, we propose the first dataset ownership verification method tailored specifically for self-supervised pre-trained models by contrastive learning. Its primary objective is to ascertain whether a suspicious black-box backbone has been pre-trained on a specific unlabeled dataset, aiding dataset owners in upholding their rights. The proposed approach is motivated by our empirical insights that when models are trained with the target dataset, the unary and binary instance relationships within the embedding space exhibit significant variations compared to models trained without the target dataset. We validate the efficacy of this approach across multiple contrastive pre-trained models including SimCLR, BYOL, SimSiam, MOCO v3, and DINO. The results demonstrate that our method rejects the null hypothesis with a $p$-value markedly below $0.05$, surpassing all previous methodologies. Our code is available at https://github.com/xieyc99/DOV4CL.
LG-CAV: Train Any Concept Activation Vector with Language Guidance
Oct 14, 2024



Concept activation vector (CAV) has attracted broad research interest in explainable AI, by elegantly attributing model predictions to specific concepts. However, the training of CAV often necessitates a large number of high-quality images, which are expensive to curate and thus limited to a predefined set of concepts. To address this issue, we propose Language-Guided CAV (LG-CAV) to harness the abundant concept knowledge within the certain pre-trained vision-language models (e.g., CLIP). This method allows training any CAV without labeled data, by utilizing the corresponding concept descriptions as guidance. To bridge the gap between vision-language model and the target model, we calculate the activation values of concept descriptions on a common pool of images (probe images) with vision-language model and utilize them as language guidance to train the LG-CAV. Furthermore, after training high-quality LG-CAVs related to all the predicted classes in the target model, we propose the activation sample reweighting (ASR), serving as a model correction technique, to improve the performance of the target model in return. Experiments on four datasets across nine architectures demonstrate that LG-CAV achieves significantly superior quality to previous CAV methods given any concept, and our model correction method achieves state-of-the-art performance compared to existing concept-based methods. Our code is available at https://github.com/hqhQAQ/LG-CAV.
On the Evaluation Consistency of Attribution-based Explanations
Jul 28, 2024
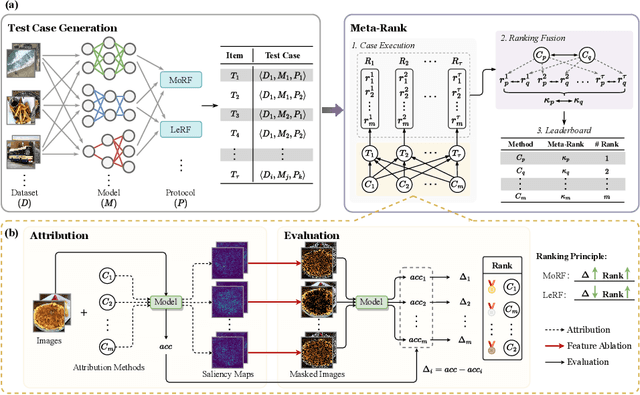
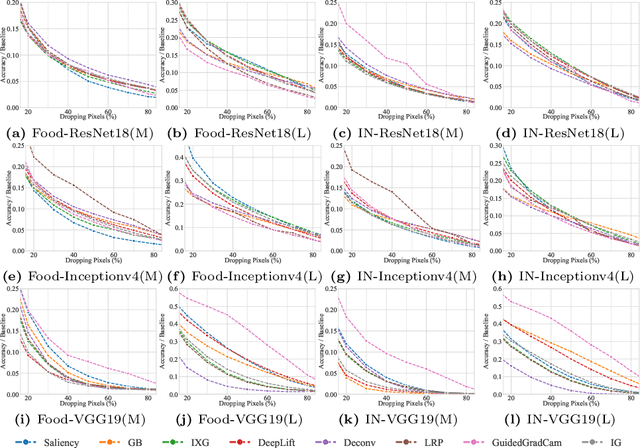
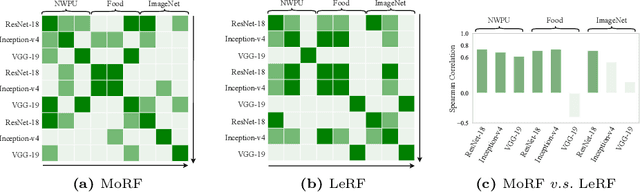
Attribution-based explanations are garnering increasing attention recently and have emerged as the predominant approach towards \textit{eXplanable Artificial Intelligence}~(XAI). However, the absence of consistent configurations and systematic investigations in prior literature impedes comprehensive evaluations of existing methodologies. In this work, we introduce {Meta-Rank}, an open platform for benchmarking attribution methods in the image domain. Presently, Meta-Rank assesses eight exemplary attribution methods using six renowned model architectures on four diverse datasets, employing both the \textit{Most Relevant First} (MoRF) and \textit{Least Relevant First} (LeRF) evaluation protocols. Through extensive experimentation, our benchmark reveals three insights in attribution evaluation endeavors: 1) evaluating attribution methods under disparate settings can yield divergent performance rankings; 2) although inconsistent across numerous cases, the performance rankings exhibit remarkable consistency across distinct checkpoints along the same training trajectory; 3) prior attempts at consistent evaluation fare no better than baselines when extended to more heterogeneous models and datasets. Our findings underscore the necessity for future research in this domain to conduct rigorous evaluations encompassing a broader range of models and datasets, and to reassess the assumptions underlying the empirical success of different attribution methods. Our code is publicly available at \url{https://github.com/TreeThree-R/Meta-Rank}.
Enhancing Thermal Infrared Tracking with Natural Language Modeling and Coordinate Sequence Generation
Jul 11, 2024



Thermal infrared tracking is an essential topic in computer vision tasks because of its advantage of all-weather imaging. However, most conventional methods utilize only hand-crafted features, while deep learning-based correlation filtering methods are limited by simple correlation operations. Transformer-based methods ignore temporal and coordinate information, which is critical for TIR tracking that lacks texture and color information. In this paper, to address these issues, we apply natural language modeling to TIR tracking and propose a novel model called NLMTrack, which enhances the utilization of coordinate and temporal information. NLMTrack applies an encoder that unifies feature extraction and feature fusion, which simplifies the TIR tracking pipeline. To address the challenge of low detail and low contrast in TIR images, on the one hand, we design a multi-level progressive fusion module that enhances the semantic representation and incorporates multi-scale features. On the other hand, the decoder combines the TIR features and the coordinate sequence features using a causal transformer to generate the target sequence step by step. Moreover, we explore an adaptive loss aimed at elevating tracking accuracy and a simple template update strategy to accommodate the target's appearance variations. Experiments show that NLMTrack achieves state-of-the-art performance on multiple benchmarks. The Code is publicly available at \url{https://github.com/ELOESZHANG/NLMTrack}.
On the Concept Trustworthiness in Concept Bottleneck Models
Mar 21, 2024



Concept Bottleneck Models (CBMs), which break down the reasoning process into the input-to-concept mapping and the concept-to-label prediction, have garnered significant attention due to their remarkable interpretability achieved by the interpretable concept bottleneck. However, despite the transparency of the concept-to-label prediction, the mapping from the input to the intermediate concept remains a black box, giving rise to concerns about the trustworthiness of the learned concepts (i.e., these concepts may be predicted based on spurious cues). The issue of concept untrustworthiness greatly hampers the interpretability of CBMs, thereby hindering their further advancement. To conduct a comprehensive analysis on this issue, in this study we establish a benchmark to assess the trustworthiness of concepts in CBMs. A pioneering metric, referred to as concept trustworthiness score, is proposed to gauge whether the concepts are derived from relevant regions. Additionally, an enhanced CBM is introduced, enabling concept predictions to be made specifically from distinct parts of the feature map, thereby facilitating the exploration of their related regions. Besides, we introduce three modules, namely the cross-layer alignment (CLA) module, the cross-image alignment (CIA) module, and the prediction alignment (PA) module, to further enhance the concept trustworthiness within the elaborated CBM. The experiments on five datasets across ten architectures demonstrate that without using any concept localization annotations during training, our model improves the concept trustworthiness by a large margin, meanwhile achieving superior accuracy to the state-of-the-arts. Our code is available at https://github.com/hqhQAQ/ProtoCBM.