 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Latent Disentangled Diffusion Model for Textile Pattern Generation
Mar 17, 2026Textile pattern generation (TPG) aims to synthesize fine-grained textile pattern images based on given clothing images. Although previous studies have not explicitly investigated TPG, existing image-to-image models appear to be natural candidates for this task. However, when applied directly, these methods often produce unfaithful results, failing to preserve fine-grained details due to feature confusion between complex textile patterns and the inherent non-rigid texture distortions in clothing images. In this paper, we propose a novel method, SLDDM-TPG, for faithful and high-fidelity TPG. Our method consists of two stages: (1) a latent disentangled network (LDN) that resolves feature confusion in clothing representations and constructs a multi-dimensional, independent clothing feature space; and (2) a semi-supervised latent diffusion model (S-LDM), which receives guidance signals from LDN and generates faithful results through semi-supervised diffusion training, combined with our designed fine-grained alignment strategy. Extensive evaluations show that SLDDM-TPG reduces FID by 4.1 and improves SSIM by up to 0.116 on our CTP-HD dataset, and also demonstrate good generalization on the VITON-HD dataset.
Dataset Ownership Verification in Contrastive Pre-trained Models
Feb 11, 2025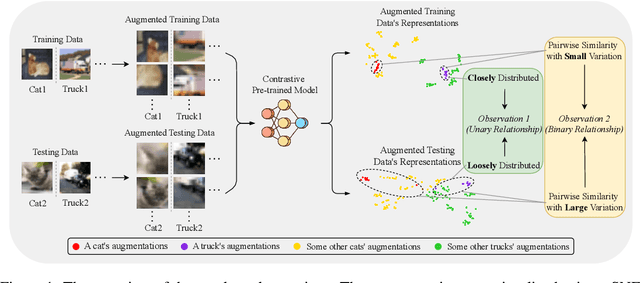
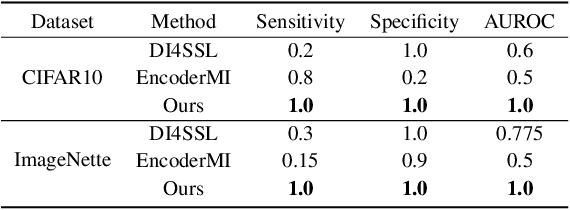
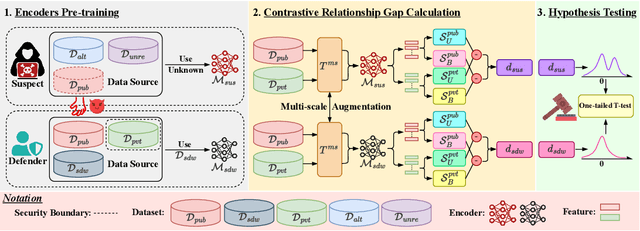
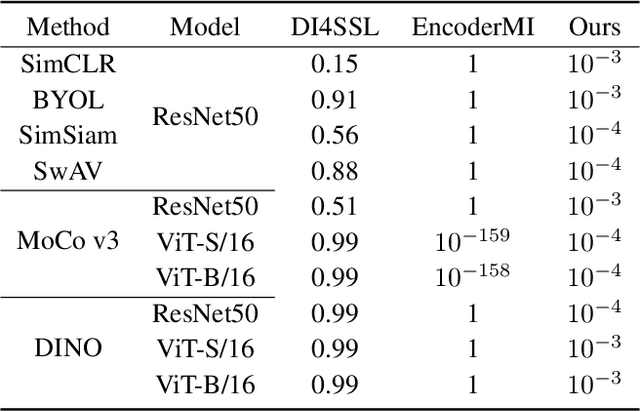
High-quality open-source datasets, which necessitate substantial efforts for curation, has become the primary catalyst for the swift progress of deep learning. Concurrently, protecting these datasets is paramount for the well-being of the data owner. Dataset ownership verification emerges as a crucial method in this domain, but existing approaches are often limited to supervised models and cannot be directly extended to increasingly popular unsupervised pre-trained models. In this work, we propose the first dataset ownership verification method tailored specifically for self-supervised pre-trained models by contrastive learning. Its primary objective is to ascertain whether a suspicious black-box backbone has been pre-trained on a specific unlabeled dataset, aiding dataset owners in upholding their rights. The proposed approach is motivated by our empirical insights that when models are trained with the target dataset, the unary and binary instance relationships within the embedding space exhibit significant variations compared to models trained without the target dataset. We validate the efficacy of this approach across multiple contrastive pre-trained models including SimCLR, BYOL, SimSiam, MOCO v3, and DINO. The results demonstrate that our method rejects the null hypothesis with a $p$-value markedly below $0.05$, surpassing all previous methodologies. Our code is available at https://github.com/xieyc99/DOV4CL.
LG-CAV: Train Any Concept Activation Vector with Language Guidance
Oct 14, 2024



Concept activation vector (CAV) has attracted broad research interest in explainable AI, by elegantly attributing model predictions to specific concepts. However, the training of CAV often necessitates a large number of high-quality images, which are expensive to curate and thus limited to a predefined set of concepts. To address this issue, we propose Language-Guided CAV (LG-CAV) to harness the abundant concept knowledge within the certain pre-trained vision-language models (e.g., CLIP). This method allows training any CAV without labeled data, by utilizing the corresponding concept descriptions as guidance. To bridge the gap between vision-language model and the target model, we calculate the activation values of concept descriptions on a common pool of images (probe images) with vision-language model and utilize them as language guidance to train the LG-CAV. Furthermore, after training high-quality LG-CAVs related to all the predicted classes in the target model, we propose the activation sample reweighting (ASR), serving as a model correction technique, to improve the performance of the target model in return. Experiments on four datasets across nine architectures demonstrate that LG-CAV achieves significantly superior quality to previous CAV methods given any concept, and our model correction method achieves state-of-the-art performance compared to existing concept-based methods. Our code is available at https://github.com/hqhQAQ/LG-CAV.
On the Evaluation Consistency of Attribution-based Explanations
Jul 28, 2024
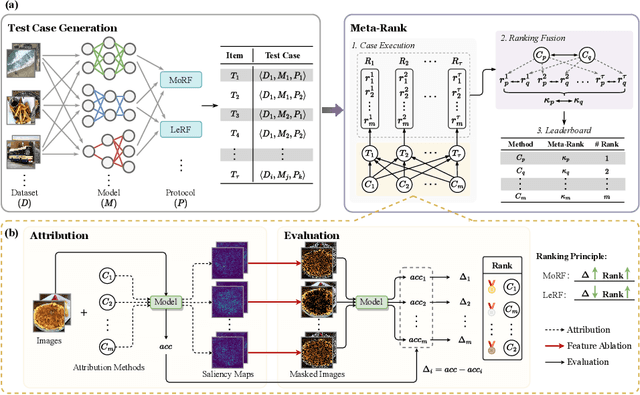
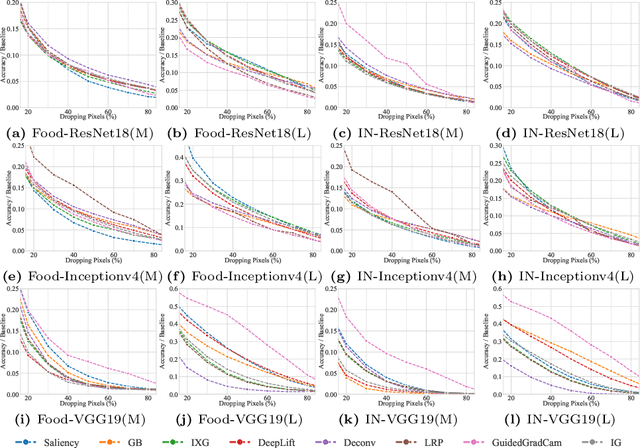
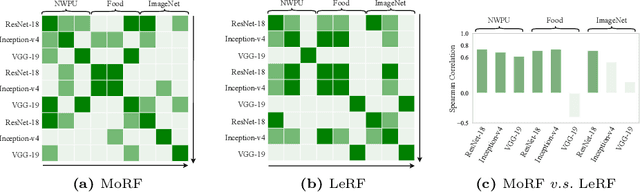
Attribution-based explanations are garnering increasing attention recently and have emerged as the predominant approach towards \textit{eXplanable Artificial Intelligence}~(XAI). However, the absence of consistent configurations and systematic investigations in prior literature impedes comprehensive evaluations of existing methodologies. In this work, we introduce {Meta-Rank}, an open platform for benchmarking attribution methods in the image domain. Presently, Meta-Rank assesses eight exemplary attribution methods using six renowned model architectures on four diverse datasets, employing both the \textit{Most Relevant First} (MoRF) and \textit{Least Relevant First} (LeRF) evaluation protocols. Through extensive experimentation, our benchmark reveals three insights in attribution evaluation endeavors: 1) evaluating attribution methods under disparate settings can yield divergent performance rankings; 2) although inconsistent across numerous cases, the performance rankings exhibit remarkable consistency across distinct checkpoints along the same training trajectory; 3) prior attempts at consistent evaluation fare no better than baselines when extended to more heterogeneous models and datasets. Our findings underscore the necessity for future research in this domain to conduct rigorous evaluations encompassing a broader range of models and datasets, and to reassess the assumptions underlying the empirical success of different attribution methods. Our code is publicly available at \url{https://github.com/TreeThree-R/Meta-Rank}.
PruningBench: A Comprehensive Benchmark of Structural Pruning
Jun 18, 2024



Structural pruning has emerged as a promising approach for producing more efficient models. Nevertheless, the community suffers from a lack of standardized benchmarks and metrics, leaving the progress in this area not fully comprehended. To fill this gap, we present the first comprehensive benchmark, termed \textit{PruningBench}, for structural pruning. PruningBench showcases the following three characteristics: 1) PruningBench employs a unified and consistent framework for evaluating the effectiveness of diverse structural pruning techniques; 2) PruningBench systematically evaluates 16 existing pruning methods, encompassing a wide array of models (e.g., CNNs and ViTs) and tasks (e.g., classification and detection); 3) PruningBench provides easily implementable interfaces to facilitate the implementation of future pruning methods, and enables the subsequent researchers to incorporate their work into our leaderboards. We provide an online pruning platform http://pruning.vipazoo.cn for customizing pruning tasks and reproducing all results in this paper. Codes will be made publicly available.
Generalization Matters: Loss Minima Flattening via Parameter Hybridization for Efficient Online Knowledge Distillation
Mar 26, 2023



Most existing online knowledge distillation(OKD) techniques typically require sophisticated modules to produce diverse knowledge for improving students' generalization ability. In this paper, we strive to fully utilize multi-model settings instead of well-designed modules to achieve a distillation effect with excellent generalization performance. Generally, model generalization can be reflected in the flatness of the loss landscape. Since averaging parameters of multiple models can find flatter minima, we are inspired to extend the process to the sampled convex combinations of multi-student models in OKD. Specifically, by linearly weighting students' parameters in each training batch, we construct a Hybrid-Weight Model(HWM) to represent the parameters surrounding involved students. The supervision loss of HWM can estimate the landscape's curvature of the whole region around students to measure the generalization explicitly. Hence we integrate HWM's loss into students' training and propose a novel OKD framework via parameter hybridization(OKDPH) to promote flatter minima and obtain robust solutions. Considering the redundancy of parameters could lead to the collapse of HWM, we further introduce a fusion operation to keep the high similarity of students. Compared to the state-of-the-art(SOTA) OKD methods and SOTA methods of seeking flat minima, our OKDPH achieves higher performance with fewer parameters, benefiting OKD with lightweight and robust characteristics. Our code is publicly available at https://github.com/tianlizhang/OKDPH.
Schema Inference for Interpretable Image Classification
Mar 12, 2023In this paper, we study a novel inference paradigm, termed as schema inference, that learns to deductively infer the explainable predictions by rebuilding the prior deep neural network (DNN) forwarding scheme, guided by the prevalent philosophical cognitive concept of schema. We strive to reformulate the conventional model inference pipeline into a graph matching policy that associates the extracted visual concepts of an image with the pre-computed scene impression, by analogy with human reasoning mechanism via impression matching. To this end, we devise an elaborated architecture, termed as SchemaNet, as a dedicated instantiation of the proposed schema inference concept, that models both the visual semantics of input instances and the learned abstract imaginations of target categories as topological relational graphs. Meanwhile, to capture and leverage the compositional contributions of visual semantics in a global view, we also introduce a universal Feat2Graph scheme in SchemaNet to establish the relational graphs that contain abundant interaction information. Both the theoretical analysis and the experimental results on several benchmarks demonstrate that the proposed schema inference achieves encouraging performance and meanwhile yields a clear picture of the deductive process leading to the predictions. Our code is available at https://github.com/zhfeing/SchemaNet-PyTorch.
Jointly Complementary&Competitive Influence Maximization with Concurrent Ally-Boosting and Rival-Preventing
Feb 19, 2023



In this paper, we propose a new influence spread model, namely, Complementary\&Competitive Independent Cascade (C$^2$IC) model. C$^2$IC model generalizes three well known influence model, i.e., influence boosting (IB) model, campaign oblivious (CO)IC model and the IC-N (IC model with negative opinions) model. This is the first model that considers both complementary and competitive influence spread comprehensively under multi-agent environment. Correspondingly, we propose the Complementary\&Competitive influence maximization (C$^2$IM) problem. Given an ally seed set and a rival seed set, the C$^2$IM problem aims to select a set of assistant nodes that can boost the ally spread and prevent the rival spread concurrently. We show the problem is NP-hard and can generalize the influence boosting problem and the influence blocking problem. With classifying the different cascade priorities into 4 cases by the monotonicity and submodularity (M\&S) holding conditions, we design 4 algorithms respectively, with theoretical approximation bounds provided. We conduct extensive experiments on real social networks and the experimental results demonstrate the effectiveness of the proposed algorithms. We hope this work can inspire abundant future exploration for constructing more generalized influence models that help streamline the works of this area.
Is ProtoPNet Really Explainable? Evaluating and Improving the Interpretability of Prototypes
Dec 12, 2022ProtoPNet and its follow-up variants (ProtoPNets) have attracted broad research interest for their intrinsic interpretability from prototypes and comparable accuracy to non-interpretable counterparts. However, it has been recently found that the interpretability of prototypes can be corrupted due to the semantic gap between similarity in latent space and that in input space. In this work, we make the first attempt to quantitatively evaluate the interpretability of prototype-based explanations, rather than solely qualitative evaluations by some visualization examples, which can be easily misled by cherry picks. To this end, we propose two evaluation metrics, termed consistency score and stability score, to evaluate the explanation consistency cross images and the explanation robustness against perturbations, both of which are essential for explanations taken into practice. Furthermore, we propose a shallow-deep feature alignment (SDFA) module and a score aggregation (SA) module to improve the interpretability of prototypes. We conduct systematical evaluation experiments and substantial discussions to uncover the interpretability of existing ProtoPNets. Experiments demonstrate that our method achieves significantly superior performance to the state-of-the-arts, under both the conventional qualitative evaluations and the proposed quantitative evaluations, in both accuracy and interpretability. Codes are available at https://github.com/hqhQAQ/EvalProtoPNet.
A Survey of Neural Trees
Sep 07, 2022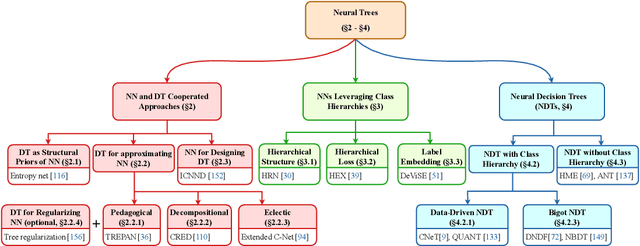
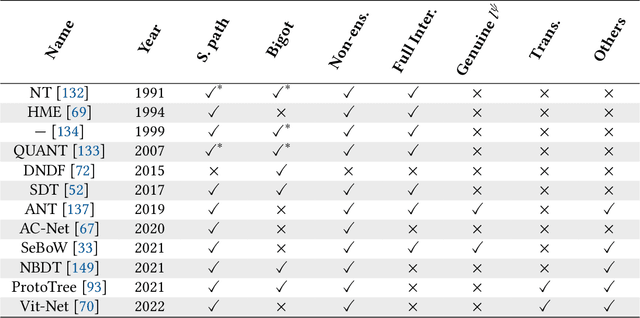
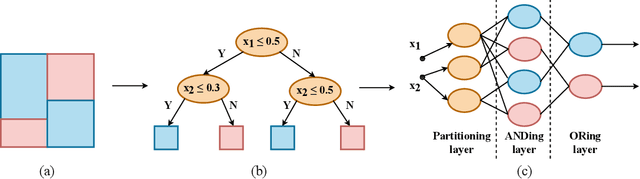
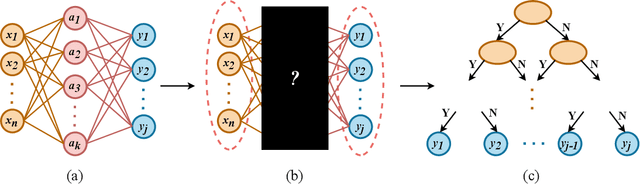
Neural networks (NNs) and decision trees (DTs) are both popular models of machine learning, yet coming with mutually exclusive advantages and limitations. To bring the best of the two worlds, a variety of approaches are proposed to integrate NNs and DTs explicitly or implicitly. In this survey, these approaches are organized in a school which we term as neural trees (NTs). This survey aims to present a comprehensive review of NTs and attempts to identify how they enhance the model interpretability. We first propose a thorough taxonomy of NTs that expresses the gradual integration and co-evolution of NNs and DTs. Afterward, we analyze NTs in terms of their interpretability and performance, and suggest possible solutions to the remaining challenges. Finally, this survey concludes with a discussion about other considerations like conditional computation and promising directions towards this field. A list of papers reviewed in this survey, along with their corresponding codes, is available at: https://github.com/zju-vipa/awesome-neural-trees