 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogics-Parsing-Omni Technical Report
Mar 12, 2026Addressing the challenges of fragmented task definitions and the heterogeneity of unstructured data in multimodal parsing, this paper proposes the Omni Parsing framework. This framework establishes a Unified Taxonomy covering documents, images, and audio-visual streams, introducing a progressive parsing paradigm that bridges perception and cognition. Specifically, the framework integrates three hierarchical levels: 1) Holistic Detection, which achieves precise spatial-temporal grounding of objects or events to establish a geometric baseline for perception; 2) Fine-grained Recognition, which performs symbolization (e.g., OCR/ASR) and attribute extraction on localized objects to complete structured entity parsing; and 3) Multi-level Interpreting, which constructs a reasoning chain from local semantics to global logic. A pivotal advantage of this framework is its evidence anchoring mechanism, which enforces a strict alignment between high-level semantic descriptions and low-level facts. This enables ``evidence-based'' logical induction, transforming unstructured signals into standardized knowledge that is locatable, enumerable, and traceable. Building on this foundation, we constructed a standardized dataset and released the Logics-Parsing-Omni model, which successfully converts complex audio-visual signals into machine-readable structured knowledge. Experiments demonstrate that fine-grained perception and high-level cognition are synergistic, effectively enhancing model reliability. Furthermore, to quantitatively evaluate these capabilities, we introduce OmniParsingBench. Code, models and the benchmark are released at https://github.com/alibaba/Logics-Parsing/tree/master/Logics-Parsing-Omni.
Blind Image Deconvolution by Generative-based Kernel Prior and Initializer via Latent Encoding
Jul 20, 2024



Blind image deconvolution (BID) is a classic yet challenging problem in the field of image processing. Recent advances in deep image prior (DIP) have motivated a series of DIP-based approaches, demonstrating remarkable success in BID. However, due to the high non-convexity of the inherent optimization process, these methods are notorious for their sensitivity to the initialized kernel. To alleviate this issue and further improve their performance, we propose a new framework for BID that better considers the prior modeling and the initialization for blur kernels, leveraging a deep generative model. The proposed approach pre-trains a generative adversarial network-based kernel generator that aptly characterizes the kernel priors and a kernel initializer that facilitates a well-informed initialization for the blur kernel through latent space encoding. With the pre-trained kernel generator and initializer, one can obtain a high-quality initialization of the blur kernel, and enable optimization within a compact latent kernel manifold. Such a framework results in an evident performance improvement over existing DIP-based BID methods. Extensive experiments on different datasets demonstrate the effectiveness of the proposed method.
Curricular Subgoals for Inverse Reinforcement Learning
Jun 14, 2023



Inverse Reinforcement Learning (IRL) aims to reconstruct the reward function from expert demonstrations to facilitate policy learning, and has demonstrated its remarkable success in imitation learning. To promote expert-like behavior, existing IRL methods mainly focus on learning global reward functions to minimize the trajectory difference between the imitator and the expert. However, these global designs are still limited by the redundant noise and error propagation problems, leading to the unsuitable reward assignment and thus downgrading the agent capability in complex multi-stage tasks. In this paper, we propose a novel Curricular Subgoal-based Inverse Reinforcement Learning (CSIRL) framework, that explicitly disentangles one task with several local subgoals to guide agent imitation. Specifically, CSIRL firstly introduces decision uncertainty of the trained agent over expert trajectories to dynamically select subgoals, which directly determines the exploration boundary of different task stages. To further acquire local reward functions for each stage, we customize a meta-imitation objective based on these curricular subgoals to train an intrinsic reward generator. Experiments on the D4RL and autonomous driving benchmarks demonstrate that the proposed methods yields results superior to the state-of-the-art counterparts, as well as better interpretability. Our code is available at https://github.com/Plankson/CSIRL.
Lookaround Optimizer: $k$ steps around, 1 step average
Jun 13, 2023Weight Average (WA) is an active research topic due to its simplicity in ensembling deep networks and the effectiveness in promoting generalization. Existing weight average approaches, however, are often carried out along only one training trajectory in a post-hoc manner (i.e., the weights are averaged after the entire training process is finished), which significantly degrades the diversity between networks and thus impairs the effectiveness in ensembling. In this paper, inspired by weight average, we propose Lookaround, a straightforward yet effective SGD-based optimizer leading to flatter minima with better generalization. Specifically, Lookaround iterates two steps during the whole training period: the around step and the average step. In each iteration, 1) the around step starts from a common point and trains multiple networks simultaneously, each on transformed data by a different data augmentation, and 2) the average step averages these trained networks to get the averaged network, which serves as the starting point for the next iteration. The around step improves the functionality diversity while the average step guarantees the weight locality of these networks during the whole training, which is essential for WA to work. We theoretically explain the superiority of Lookaround by convergence analysis, and make extensive experiments to evaluate Lookaround on popular benchmarks including CIFAR and ImageNet with both CNNs and ViTs, demonstrating clear superiority over state-of-the-arts. Our code is available at https://github.com/Ardcy/Lookaround.
Generalization Matters: Loss Minima Flattening via Parameter Hybridization for Efficient Online Knowledge Distillation
Mar 26, 2023



Most existing online knowledge distillation(OKD) techniques typically require sophisticated modules to produce diverse knowledge for improving students' generalization ability. In this paper, we strive to fully utilize multi-model settings instead of well-designed modules to achieve a distillation effect with excellent generalization performance. Generally, model generalization can be reflected in the flatness of the loss landscape. Since averaging parameters of multiple models can find flatter minima, we are inspired to extend the process to the sampled convex combinations of multi-student models in OKD. Specifically, by linearly weighting students' parameters in each training batch, we construct a Hybrid-Weight Model(HWM) to represent the parameters surrounding involved students. The supervision loss of HWM can estimate the landscape's curvature of the whole region around students to measure the generalization explicitly. Hence we integrate HWM's loss into students' training and propose a novel OKD framework via parameter hybridization(OKDPH) to promote flatter minima and obtain robust solutions. Considering the redundancy of parameters could lead to the collapse of HWM, we further introduce a fusion operation to keep the high similarity of students. Compared to the state-of-the-art(SOTA) OKD methods and SOTA methods of seeking flat minima, our OKDPH achieves higher performance with fewer parameters, benefiting OKD with lightweight and robust characteristics. Our code is publicly available at https://github.com/tianlizhang/OKDPH.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020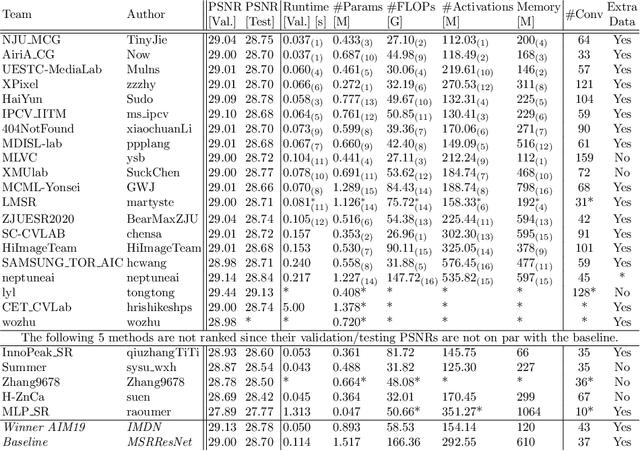
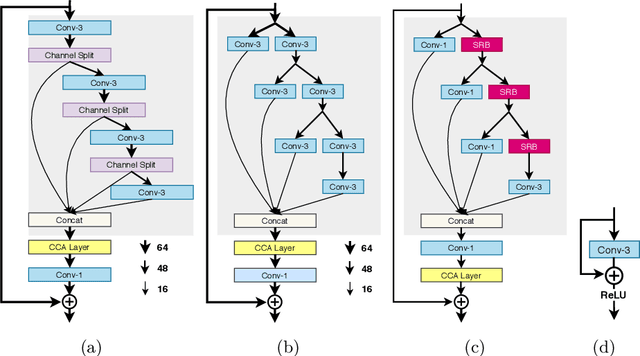
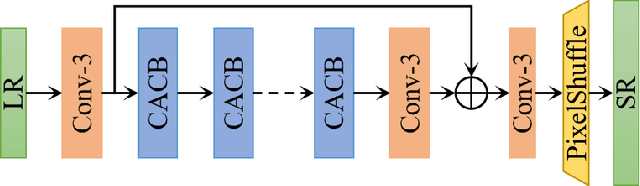
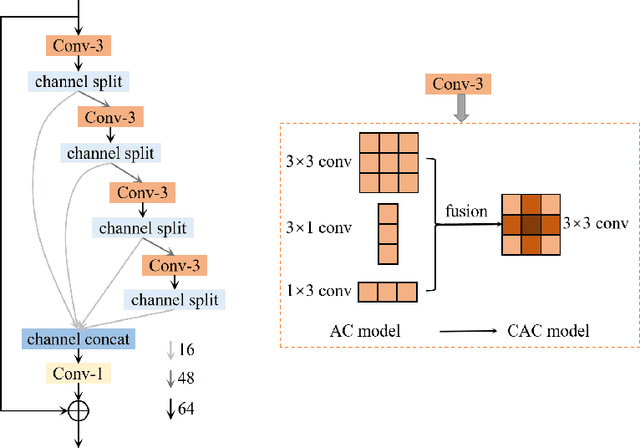
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.
NTIRE 2020 Challenge on Image Demoireing: Methods and Results
May 06, 2020



This paper reviews the Challenge on Image Demoireing that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2020. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. The challenge was divided into two tracks. Track 1 targeted the single image demoireing problem, which seeks to remove moire patterns from a single image. Track 2 focused on the burst demoireing problem, where a set of degraded moire images of the same scene were provided as input, with the goal of producing a single demoired image as output. The methods were ranked in terms of their fidelity, measured using the peak signal-to-noise ratio (PSNR) between the ground truth clean images and the restored images produced by the participants' methods. The tracks had 142 and 99 registered participants, respectively, with a total of 14 and 6 submissions in the final testing stage. The entries span the current state-of-the-art in image and burst image demoireing problems.
Overview of the CCKS 2019 Knowledge Graph Evaluation Track: Entity, Relation, Event and QA
Mar 09, 2020Knowledge graph models world knowledge as concepts, entities, and the relationships between them, which has been widely used in many real-world tasks. CCKS 2019 held an evaluation track with 6 tasks and attracted more than 1,600 teams. In this paper, we give an overview of the knowledge graph evaluation tract at CCKS 2019. By reviewing the task definition, successful methods, useful resources, good strategies and research challenges associated with each task in CCKS 2019, this paper can provide a helpful reference for developing knowledge graph applications and conducting future knowledge graph researches.