 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVGeoQA: Benchmarking LLMs on Dynamic, Multi-Objective Geo-Spatial Exploration
Apr 08, 2026While Large Language Models (LLMs) demonstrate remarkable reasoning capabilities, their potential for purpose-driven exploration in dynamic geo-spatial environments remains under-investigated. Existing Geo-Spatial Question Answering (GSQA) benchmarks predominantly focus on static retrieval, failing to capture the complexity of real-world planning that involves dynamic user locations and compound constraints. To bridge this gap, we introduce EVGeoQA, a novel benchmark built upon Electric Vehicle (EV) charging scenarios that features a distinct location-anchored and dual-objective design. Specifically, each query in EVGeoQA is explicitly bound to a user's real-time coordinate and integrates the dual objectives of a charging necessity and a co-located activity preference. To systematically assess models in such complex settings, we further propose GeoRover, a general evaluation framework based on a tool-augmented agent architecture to evaluate the LLMs' capacity for dynamic, multi-objective exploration. Our experiments reveal that while LLMs successfully utilize tools to address sub-tasks, they struggle with long-range spatial exploration. Notably, we observe an emergent capability: LLMs can summarize historical exploration trajectories to enhance exploration efficiency. These findings establish EVGeoQA as a challenging testbed for future geo-spatial intelligence. The dataset and prompts are available at https://github.com/Hapluckyy/EVGeoQA/.
Infinite Retrieval: Attention Enhanced LLMs in Long-Context Processing
Feb 18, 2025Limited by the context window size of Large Language Models(LLMs), handling various tasks with input tokens exceeding the upper limit has been challenging, whether it is a simple direct retrieval task or a complex multi-hop reasoning task. Although various methods have been proposed to enhance the long-context processing capabilities of LLMs, they either incur substantial post-training costs, or require additional tool modules(e.g.,RAG), or have not shown significant improvement in realistic tasks. Our work observes the correlation between the attention distribution and generated answers across each layer, and establishes the attention allocation aligns with retrieval-augmented capabilities through experiments. Drawing on the above insights, we propose a novel method InfiniRetri that leverages the LLMs's own attention information to enable accurate retrieval across inputs of infinitely length. Our evaluations indicate that InfiniRetri achieves 100% accuracy in the Needle-In-a-Haystack(NIH) test over 1M tokens using a 0.5B parameter model, surpassing other method or larger models and setting a new state-of-the-art(SOTA). Moreover, our method achieves significant performance improvements on real-world benchmarks, with a maximum 288% improvement. In addition, InfiniRetri can be applied to any Transformer-based LLMs without additional training and substantially reduces inference latency and compute overhead in long texts. In summary, our comprehensive studies show InfiniRetri's potential for practical applications and creates a paradigm for retrievaling information using LLMs own capabilities under infinite-length tokens. Code will be released in link.
LLM-Align: Utilizing Large Language Models for Entity Alignment in Knowledge Graphs
Dec 06, 2024



Entity Alignment (EA) seeks to identify and match corresponding entities across different Knowledge Graphs (KGs), playing a crucial role in knowledge fusion and integration. Embedding-based entity alignment (EA) has recently gained considerable attention, resulting in the emergence of many innovative approaches. Initially, these approaches concentrated on learning entity embeddings based on the structural features of knowledge graphs (KGs) as defined by relation triples. Subsequent methods have integrated entities' names and attributes as supplementary information to improve the embeddings used for EA. However, existing methods lack a deep semantic understanding of entity attributes and relations. In this paper, we propose a Large Language Model (LLM) based Entity Alignment method, LLM-Align, which explores the instruction-following and zero-shot capabilities of Large Language Models to infer alignments of entities. LLM-Align uses heuristic methods to select important attributes and relations of entities, and then feeds the selected triples of entities to an LLM to infer the alignment results. To guarantee the quality of alignment results, we design a multi-round voting mechanism to mitigate the hallucination and positional bias issues that occur with LLMs. Experiments on three EA datasets, demonstrating that our approach achieves state-of-the-art performance compared to existing EA methods.
DERA: Dense Entity Retrieval for Entity Alignment in Knowledge Graphs
Aug 02, 2024



Entity Alignment (EA) aims to match equivalent entities in different Knowledge Graphs (KGs), which is essential for knowledge fusion and integration. Recently, embedding-based EA has attracted significant attention and many approaches have been proposed. Early approaches primarily focus on learning entity embeddings from the structural features of KGs, defined by relation triples. Later methods incorporated entities' names and attributes as auxiliary information to enhance embeddings for EA. However, these approaches often used different techniques to encode structural and attribute information, limiting their interaction and mutual enhancement. In this work, we propose a dense entity retrieval framework for EA, leveraging language models to uniformly encode various features of entities and facilitate nearest entity search across KGs. Alignment candidates are first generated through entity retrieval, which are subsequently reranked to determine the final alignments. We conduct comprehensive experiments on both cross-lingual and monolingual EA datasets, demonstrating that our approach achieves state-of-the-art performance compared to existing EA methods.
Overview of the CCKS 2019 Knowledge Graph Evaluation Track: Entity, Relation, Event and QA
Mar 09, 2020Knowledge graph models world knowledge as concepts, entities, and the relationships between them, which has been widely used in many real-world tasks. CCKS 2019 held an evaluation track with 6 tasks and attracted more than 1,600 teams. In this paper, we give an overview of the knowledge graph evaluation tract at CCKS 2019. By reviewing the task definition, successful methods, useful resources, good strategies and research challenges associated with each task in CCKS 2019, this paper can provide a helpful reference for developing knowledge graph applications and conducting future knowledge graph researches.
RDF2Rules: Learning Rules from RDF Knowledge Bases by Mining Frequent Predicate Cycles
Dec 24, 2015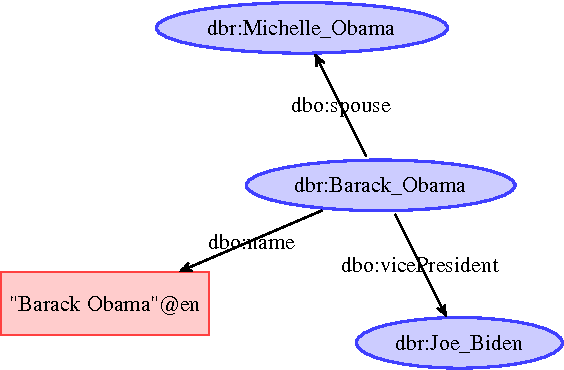
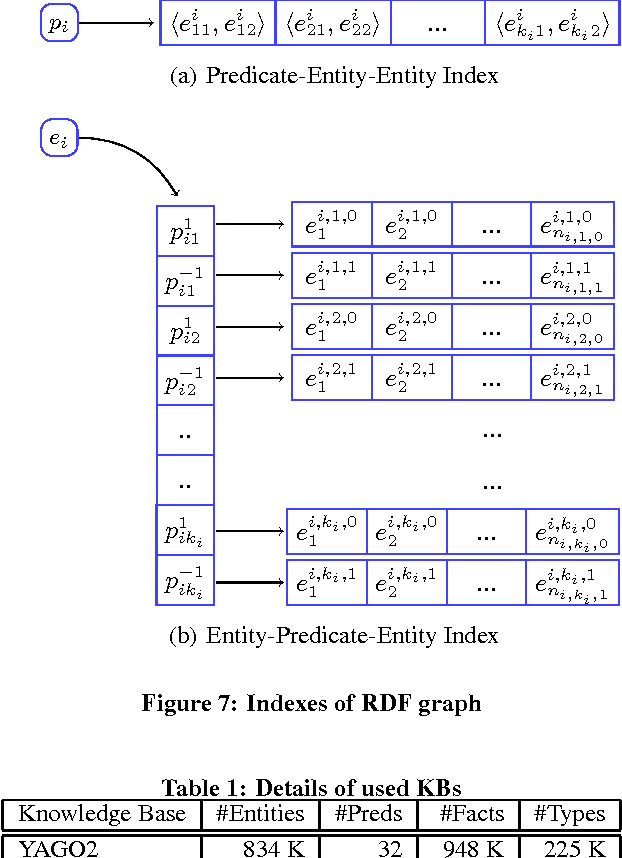


Recently, several large-scale RDF knowledge bases have been built and applied in many knowledge-based applications. To further increase the number of facts in RDF knowledge bases, logic rules can be used to predict new facts based on the existing ones. Therefore, how to automatically learn reliable rules from large-scale knowledge bases becomes increasingly important. In this paper, we propose a novel rule learning approach named RDF2Rules for RDF knowledge bases. RDF2Rules first mines frequent predicate cycles (FPCs), a kind of interesting frequent patterns in knowledge bases, and then generates rules from the mined FPCs. Because each FPC can produce multiple rules, and effective pruning strategy is used in the process of mining FPCs, RDF2Rules works very efficiently. Another advantage of RDF2Rules is that it uses the entity type information when generates and evaluates rules, which makes the learned rules more accurate. Experiments show that our approach outperforms the compared approach in terms of both efficiency and accuracy.