 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Proactive Multi-Agent Dialogue Framework for Assessing Social Language Disorder Traits in Autism
May 21, 2026Characteristic linguistic behaviors associated with Social Language Disorder (SLD) in autism spectrum disorder, including echoic repetition, pronoun displacement, and stereotyped media quoting, are largely absent from spontaneous conversation and only emerge under specific conversational conditions. In structured clinical assessments, this latency means that questioning strategy selection is a critical yet underappreciated determinant of how much diagnostic information a conversation yields. Whether large language models (LLMs) can be guided to proactively select questioning strategies that systematically surface these latent traits remains largely unexplored. Here we present TPA (Think, Plan, Ask), a proactive multi-agent dialogue framework applied to the language assessment component of the Autism Diagnostic Observation Schedule Module 4 (ADOS-2), in which a doctor agent explicitly reasons about which traits remain unobserved before selecting a clinically grounded strategy and generating a targeted question. A patient agent grounded in real ADOS-2 clinical data enables reproducible evaluation without real patient participation, validated across three independent experiments confirming adequate fidelity to real patient language. Evaluated on 484 episodes from 35 patients, TPA outperforms six competitive dialogue planning baselines across all primary metrics, achieving 82.1% SLD trait coverage, 16.6% higher than automated replay of real clinical dialogues conducted by trained clinicians (65.5%), with substantially greater per-turn diagnostic efficiency (AUCC: 0.628 vs. 0.458, absolute gain +0.170). These results demonstrate that proactive questioning strategy selection substantially improves the efficiency of automated SLD trait assessment, with direct implications for scalable AI-assisted clinical screening.
Ability Transfer and Recovery via Modularized Parameters Localization
Jan 14, 2026Large language models can be continually pre-trained or fine-tuned to improve performance in specific domains, languages, or skills, but this specialization often degrades other capabilities and may cause catastrophic forgetting. We investigate how abilities are distributed within LLM parameters by analyzing module activations under domain- and language-specific inputs for closely related models. Across layers and modules, we find that ability-related activations are highly concentrated in a small set of channels (typically <5\%), and these channels are largely disentangled with good sufficiency and stability. Building on these observations, we propose ACT (Activation-Guided Channel-wise Ability Transfer), which localizes ability-relevant channels via activation differences and selectively transfers only the corresponding parameters, followed by lightweight fine-tuning for compatibility. Experiments on multilingual mathematical and scientific reasoning show that ACT can recover forgotten abilities while preserving retained skills. It can also merge multiple specialized models to integrate several abilities into a single model with minimal interference. Our code and data will be publicly released.
Improving Data Reusability in Interactive Information Retrieval: Insights from the Community
Dec 20, 2025In this study, we conducted semi-structured interviews with 21 IIR researchers to investigate their data reuse practices. This study aims to expand upon current findings by exploring IIR researchers' information-obtaining behaviors regarding data reuse. We identified the information about shared data characteristics that IIR researchers need when evaluating data reusability, as well as the sources they typically consult to obtain this information. We consider this work to be an initial step toward revealing IIR researchers' data reuse practices and identifying what the community needs to do to promote data reuse. We hope that this study, as well as future research, will inspire more individuals to contribute to ongoing efforts aimed at designing standards, infrastructures, and policies, as well as fostering a sustainable culture of data sharing and reuse in this field.
An Exceptional Dataset For Rare Pancreatic Tumor Segmentation
Jan 29, 2025Pancreatic NEuroendocrine Tumors (pNETs) are very rare endocrine neoplasms that account for less than 5% of all pancreatic malignancies, with an incidence of only 1-1.5 cases per 100,000. Early detection of pNETs is critical for improving patient survival, but the rarity of pNETs makes segmenting them from CT a very challenging problem. So far, there has not been a dataset specifically for pNETs available to researchers. To address this issue, we propose a pNETs dataset, a well-annotated Contrast-Enhanced Computed Tomography (CECT) dataset focused exclusively on Pancreatic Neuroendocrine Tumors, containing data from 469 patients. This is the first dataset solely dedicated to pNETs, distinguishing it from previous collections. Additionally, we provide the baseline detection networks with a new slice-wise weight loss function designed for the UNet-based model, improving the overall pNET segmentation performance. We hope that our dataset can enhance the understanding and diagnosis of pNET Tumors within the medical community, facilitate the development of more accurate diagnostic tools, and ultimately improve patient outcomes and advance the field of oncology.
The Landscape of Data Reuse in Interactive Information Retrieval: Motivations, Sources, and Evaluation of Reusability
Nov 23, 2024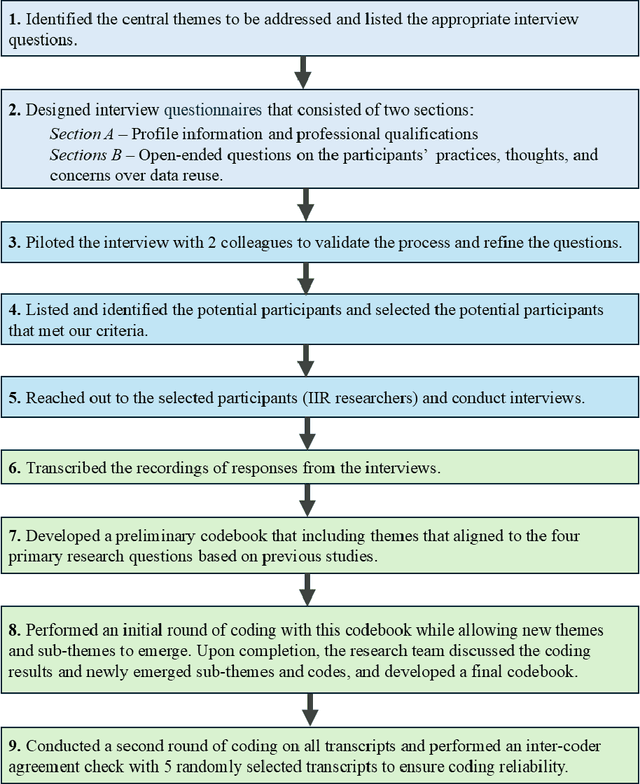


Sharing and reusing research data can effectively reduce redundant efforts in data collection and curation, especially for small labs and research teams conducting human-centered system research, and enhance the replicability of evaluation experiments. Building a sustainable data reuse process and culture relies on frameworks that encompass policies, standards, roles, and responsibilities, all of which must address the diverse needs of data providers, curators, and reusers. To advance the knowledge and accumulate empirical understandings on data reuse, this study investigated the data reuse practices of experienced researchers from the area of Interactive Information Retrieval (IIR) studies, where data reuse has been strongly advocated but still remains a challenge. To enhance the knowledge on data reuse behavior and reusability assessment strategies within IIR community, we conducted 21 semi-structured in-depth interviews with IIR researchers from varying demographic backgrounds, institutions, and stages of careers on their motivations, experiences, and concerns over data reuse. We uncovered the reasons, strategies of reusability assessments, and challenges faced by data reusers within the field of IIR as they attempt to reuse researcher data in their studies. The empirical finding improves our understanding of researchers' motivations for reusing data, their approaches to discovering reusable research data, as well as their concerns and criteria for assessing data reusability, and also enriches the on-going discussions on evaluating user-generated data and research resources and promoting community-level data reuse culture and standards.
VILA-M3: Enhancing Vision-Language Models with Medical Expert Knowledge
Nov 19, 2024



Generalist vision language models (VLMs) have made significant strides in computer vision, but they fall short in specialized fields like healthcare, where expert knowledge is essential. In traditional computer vision tasks, creative or approximate answers may be acceptable, but in healthcare, precision is paramount.Current large multimodal models like Gemini and GPT-4o are insufficient for medical tasks due to their reliance on memorized internet knowledge rather than the nuanced expertise required in healthcare. VLMs are usually trained in three stages: vision pre-training, vision-language pre-training, and instruction fine-tuning (IFT). IFT has been typically applied using a mixture of generic and healthcare data. In contrast, we propose that for medical VLMs, a fourth stage of specialized IFT is necessary, which focuses on medical data and includes information from domain expert models. Domain expert models developed for medical use are crucial because they are specifically trained for certain clinical tasks, e.g. to detect tumors and classify abnormalities through segmentation and classification, which learn fine-grained features of medical data$-$features that are often too intricate for a VLM to capture effectively especially in radiology. This paper introduces a new framework, VILA-M3, for medical VLMs that utilizes domain knowledge via expert models. Through our experiments, we show an improved state-of-the-art (SOTA) performance with an average improvement of ~9% over the prior SOTA model Med-Gemini and ~6% over models trained on the specific tasks. Our approach emphasizes the importance of domain expertise in creating precise, reliable VLMs for medical applications.
Video-based Analysis Reveals Atypical Social Gaze in People with Autism Spectrum Disorder
Sep 01, 2024

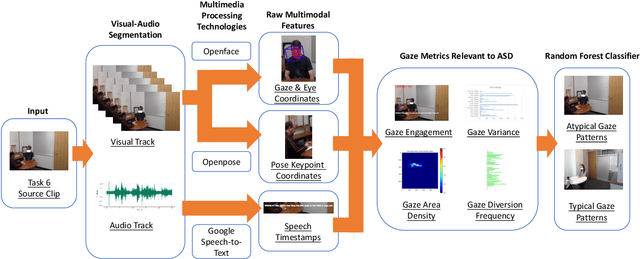

In this study, we present a quantitative and comprehensive analysis of social gaze in people with autism spectrum disorder (ASD). Diverging from traditional first-person camera perspectives based on eye-tracking technologies, this study utilizes a third-person perspective database from the Autism Diagnostic Observation Schedule, 2nd Edition (ADOS-2) interview videos, encompassing ASD participants and neurotypical individuals as a reference group. Employing computational models, we extracted and processed gaze-related features from the videos of both participants and examiners. The experimental samples were divided into three groups based on the presence of social gaze abnormalities and ASD diagnosis. This study quantitatively analyzed four gaze features: gaze engagement, gaze variance, gaze density map, and gaze diversion frequency. Furthermore, we developed a classifier trained on these features to identify gaze abnormalities in ASD participants. Together, we demonstrated the effectiveness of analyzing social gaze in people with ASD in naturalistic settings, showcasing the potential of third-person video perspectives in enhancing ASD diagnosis through gaze analysis.
A Short Review and Evaluation of SAM2's Performance in 3D CT Image Segmentation
Aug 20, 2024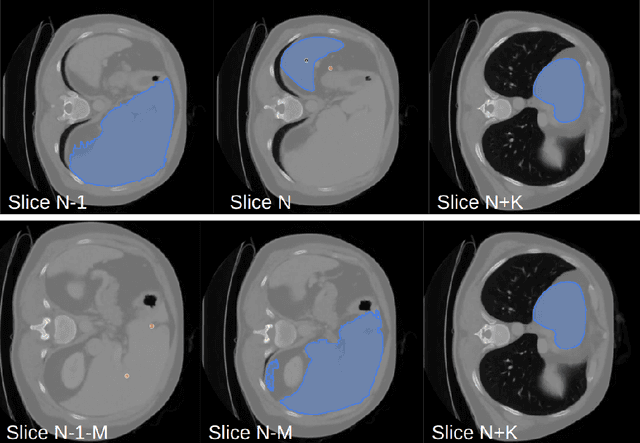
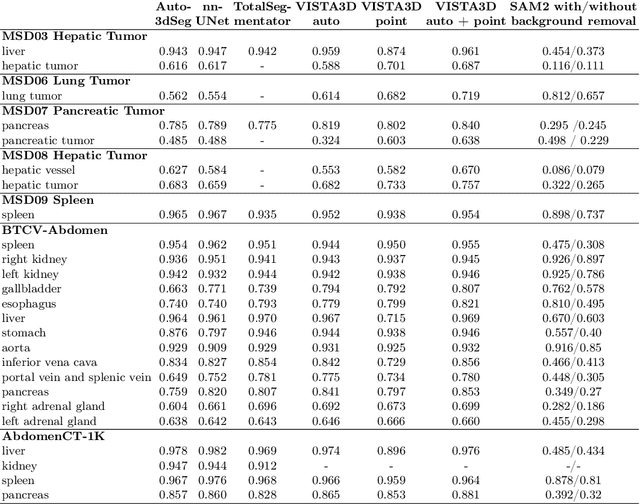
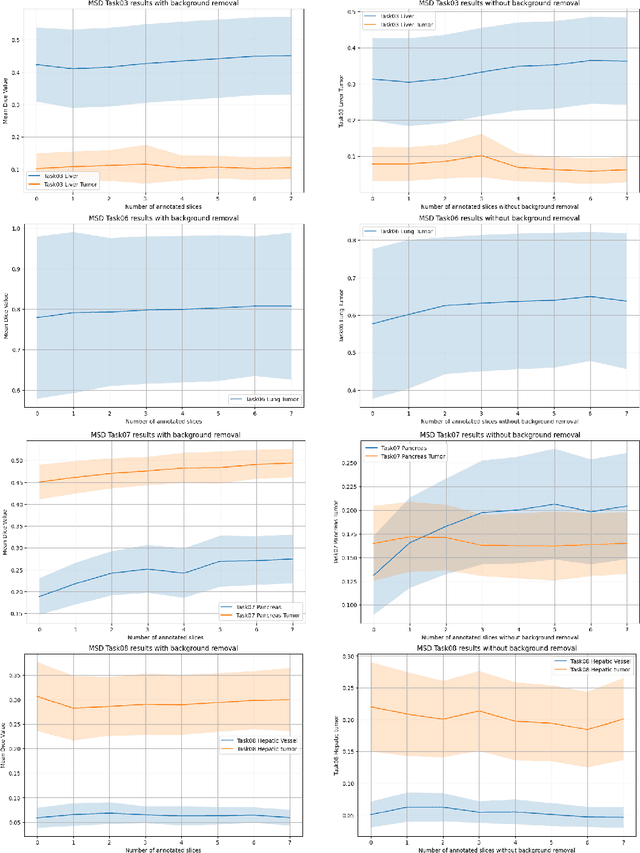
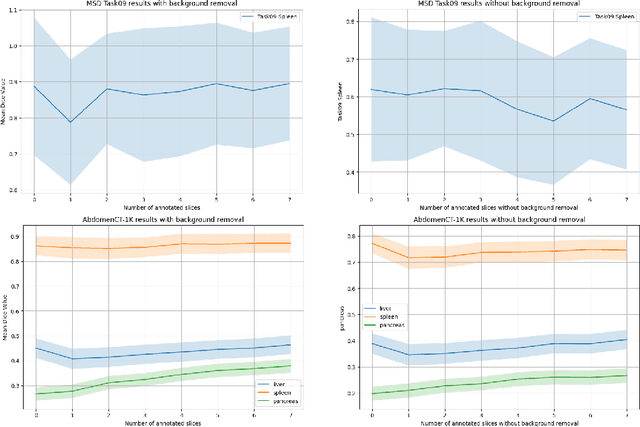
Since the release of Segment Anything 2 (SAM2), the medical imaging community has been actively evaluating its performance for 3D medical image segmentation. However, different studies have employed varying evaluation pipelines, resulting in conflicting outcomes that obscure a clear understanding of SAM2's capabilities and potential applications. We shortly review existing benchmarks and point out that the SAM2 paper clearly outlines a zero-shot evaluation pipeline, which simulates user clicks iteratively for up to eight iterations. We reproduced this interactive annotation simulation on 3D CT datasets and provided the results and code~\url{https://github.com/Project-MONAI/VISTA}. Our findings reveal that directly applying SAM2 on 3D medical imaging in a zero-shot manner is far from satisfactory. It is prone to generating false positives when foreground objects disappear, and annotating more slices cannot fully offset this tendency. For smaller single-connected objects like kidney and aorta, SAM2 performs reasonably well but for most organs it is still far behind state-of-the-art 3D annotation methods. More research and innovation are needed for 3D medical imaging community to use SAM2 correctly.
VISTA3D: Versatile Imaging SegmenTation and Annotation model for 3D Computed Tomography
Jun 07, 2024Segmentation foundation models have attracted great interest, however, none of them are adequate enough for the use cases in 3D computed tomography scans (CT) images. Existing works finetune on medical images with 2D foundation models trained on natural images, but interactive segmentation, especially in 2D, is too time-consuming for 3D scans and less useful for large cohort analysis. Models that can perform out-of-the-box automatic segmentation are more desirable. However, the model trained in this way lacks the ability to perform segmentation on unseen objects like novel tumors. Thus for 3D medical image analysis, an ideal segmentation solution might expect two features: accurate out-of-the-box performance covering major organ classes, and effective adaptation or zero-shot ability to novel structures. In this paper, we discuss what features a 3D CT segmentation foundation model should have, and introduce VISTA3D, Versatile Imaging SegmenTation and Annotation model. The model is trained systematically on 11454 volumes encompassing 127 types of human anatomical structures and various lesions and provides accurate out-of-the-box segmentation. The model's design also achieves state-of-the-art zero-shot interactive segmentation in 3D. The novel model design and training recipe represent a promising step toward developing a versatile medical image foundation model. Code and model weights will be released shortly. The early version of online demo can be tried on https://build.nvidia.com/nvidia/vista-3d.
From Sora What We Can See: A Survey of Text-to-Video Generation
May 17, 2024
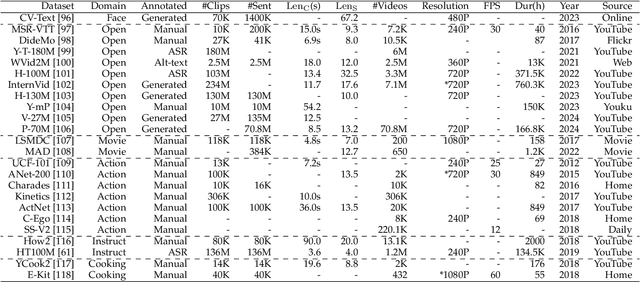
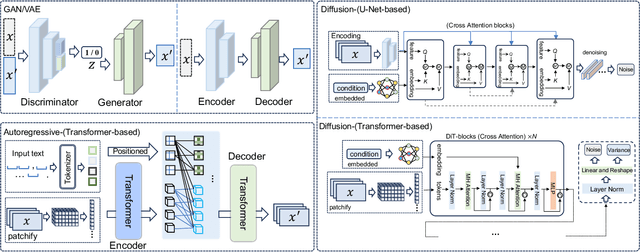

With impressive achievements made, artificial intelligence is on the path forward to artificial general intelligence. Sora, developed by OpenAI, which is capable of minute-level world-simulative abilities can be considered as a milestone on this developmental path. However, despite its notable successes, Sora still encounters various obstacles that need to be resolved. In this survey, we embark from the perspective of disassembling Sora in text-to-video generation, and conducting a comprehensive review of literature, trying to answer the question, \textit{From Sora What We Can See}. Specifically, after basic preliminaries regarding the general algorithms are introduced, the literature is categorized from three mutually perpendicular dimensions: evolutionary generators, excellent pursuit, and realistic panorama. Subsequently, the widely used datasets and metrics are organized in detail. Last but more importantly, we identify several challenges and open problems in this domain and propose potential future directions for research and development.