 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exceptional Dataset For Rare Pancreatic Tumor Segmentation
Jan 29, 2025Pancreatic NEuroendocrine Tumors (pNETs) are very rare endocrine neoplasms that account for less than 5% of all pancreatic malignancies, with an incidence of only 1-1.5 cases per 100,000. Early detection of pNETs is critical for improving patient survival, but the rarity of pNETs makes segmenting them from CT a very challenging problem. So far, there has not been a dataset specifically for pNETs available to researchers. To address this issue, we propose a pNETs dataset, a well-annotated Contrast-Enhanced Computed Tomography (CECT) dataset focused exclusively on Pancreatic Neuroendocrine Tumors, containing data from 469 patients. This is the first dataset solely dedicated to pNETs, distinguishing it from previous collections. Additionally, we provide the baseline detection networks with a new slice-wise weight loss function designed for the UNet-based model, improving the overall pNET segmentation performance. We hope that our dataset can enhance the understanding and diagnosis of pNET Tumors within the medical community, facilitate the development of more accurate diagnostic tools, and ultimately improve patient outcomes and advance the field of oncology.
GEARS: Local Geometry-aware Hand-object Interaction Synthesis
Apr 04, 2024Generating realistic hand motion sequences in interaction with objects has gained increasing attention with the growing interest in digital humans. Prior work has illustrated the effectiveness of employing occupancy-based or distance-based virtual sensors to extract hand-object interaction features. Nonetheless, these methods show limited generalizability across object categories, shapes and sizes. We hypothesize that this is due to two reasons: 1) the limited expressiveness of employed virtual sensors, and 2) scarcity of available training data. To tackle this challenge, we introduce a novel joint-centered sensor designed to reason about local object geometry near potential interaction regions. The sensor queries for object surface points in the neighbourhood of each hand joint. As an important step towards mitigating the learning complexity, we transform the points from global frame to hand template frame and use a shared module to process sensor features of each individual joint. This is followed by a spatio-temporal transformer network aimed at capturing correlation among the joints in different dimensions. Moreover, we devise simple heuristic rules to augment the limited training sequences with vast static hand grasping samples. This leads to a broader spectrum of grasping types observed during training, in turn enhancing our model's generalization capability. We evaluate on two public datasets, GRAB and InterCap, where our method shows superiority over baselines both quantitatively and perceptually.
TOCH: Spatio-Temporal Object Correspondence to Hand for Motion Refinement
May 16, 2022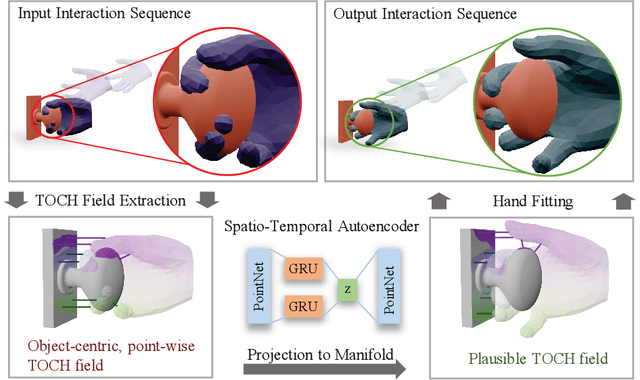

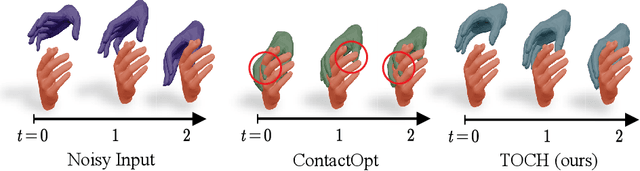
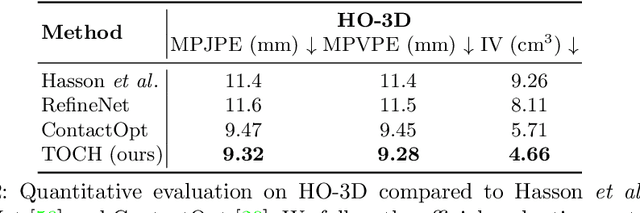
We present TOCH, a method for refining incorrect 3D hand-object interaction sequences using a data prior. Existing hand trackers, especially those that rely on very few cameras, often produce visually unrealistic results with hand-object intersection or missing contacts. Although correcting such errors requires reasoning about temporal aspects of interaction, most previous work focus on static grasps and contacts. The core of our method are TOCH fields, a novel spatio-temporal representation for modeling correspondences between hands and objects during interaction. The key component is a point-wise object-centric representation which encodes the hand position relative to the object. Leveraging this novel representation, we learn a latent manifold of plausible TOCH fields with a temporal denoising auto-encoder. Experiments demonstrate that TOCH outperforms state-of-the-art (SOTA) 3D hand-object interaction models, which are limited to static grasps and contacts. More importantly, our method produces smooth interactions even before and after contact. Using a single trained TOCH model, we quantitatively and qualitatively demonstrate its usefulness for 1) correcting erroneous reconstruction results from off-the-shelf RGB/RGB-D hand-object reconstruction methods, 2) de-noising, and 3) grasp transfer across objects. We will release our code and trained model on our project page at http://virtualhumans.mpi-inf.mpg.de/toch/
Panoramic Depth Estimation via Supervised and Unsupervised Learning in Indoor Scenes
Aug 18, 2021


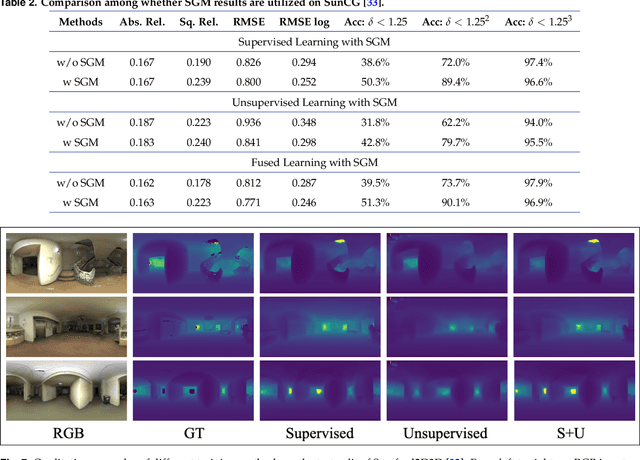
Depth estimation, as a necessary clue to convert 2D images into the 3D space, has been applied in many machine vision areas. However, to achieve an entire surrounding 360-degree geometric sensing, traditional stereo matching algorithms for depth estimation are limited due to large noise, low accuracy, and strict requirements for multi-camera calibration. In this work, for a unified surrounding perception, we introduce panoramic images to obtain larger field of view. We extend PADENet first appeared in our previous conference work for outdoor scene understanding, to perform panoramic monocular depth estimation with a focus for indoor scenes. At the same time, we improve the training process of the neural network adapted to the characteristics of panoramic images. In addition, we fuse traditional stereo matching algorithm with deep learning methods and further improve the accuracy of depth predictions. With a comprehensive variety of experiments, this research demonstrates the effectiveness of our schemes aiming for indoor scene perception.
Adjoint Rigid Transform Network: Self-supervised Alignment of 3D Shapes
Feb 01, 2021
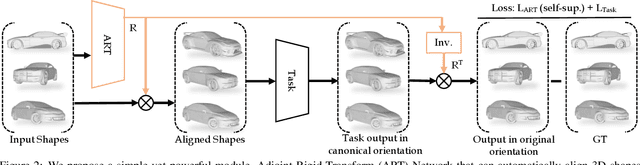
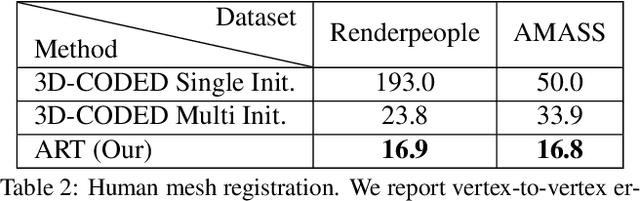
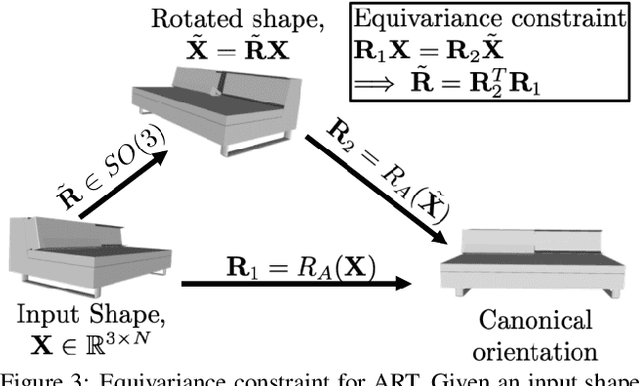
Most learning methods for 3D data (point clouds, meshes) suffer significant performance drops when the data is not carefully aligned to a canonical orientation. Aligning real world 3D data collected from different sources is non-trivial and requires manual intervention. In this paper, we propose the Adjoint Rigid Transform (ART) Network, a neural module which can be integrated with existing 3D networks to significantly boost their performance in tasks such as shape reconstruction, non-rigid registration, and latent disentanglement. ART learns to rotate input shapes to a canonical orientation that is crucial for a lot of tasks. ART achieves this by imposing rotation equivariance constraint on input shapes. The remarkable result is that with only self-supervision, ART can discover a unique canonical orientation for both rigid and nonrigid objects, which leads to a notable boost in downstream task performance. We will release our code and pre-trained models for further research.
Unsupervised Shape and Pose Disentanglement for 3D Meshes
Jul 22, 2020

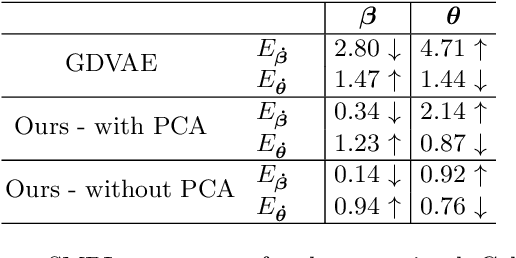
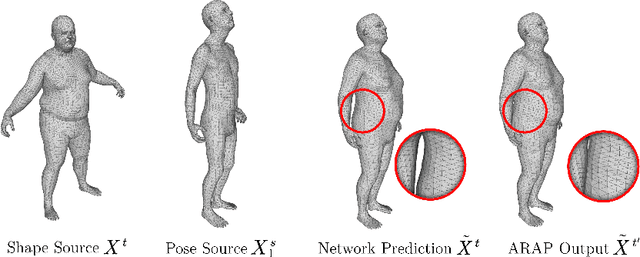
Parametric models of humans, faces, hands and animals have been widely used for a range of tasks such as image-based reconstruction, shape correspondence estimation, and animation. Their key strength is the ability to factor surface variations into shape and pose dependent components. Learning such models requires lots of expert knowledge and hand-defined object-specific constraints, making the learning approach unscalable to novel objects. In this paper, we present a simple yet effective approach to learn disentangled shape and pose representations in an unsupervised setting. We use a combination of self-consistency and cross-consistency constraints to learn pose and shape space from registered meshes. We additionally incorporate as-rigid-as-possible deformation(ARAP) into the training loop to avoid degenerate solutions. We demonstrate the usefulness of learned representations through a number of tasks including pose transfer and shape retrieval. The experiments on datasets of 3D humans, faces, hands and animals demonstrate the generality of our approach. Code is made available at https://virtualhumans.mpi-inf.mpg.de/unsup_shape_pose/.
Efficient Image Evidence Analysis of CNN Classification Results
Jan 05, 2018
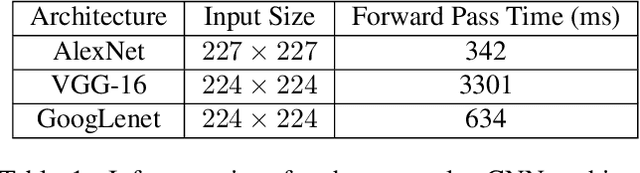


Convolutional neural networks (CNNs) define the current state-of-the-art for image recognition. With their emerging popularity, especially for critical applications like medical image analysis or self-driving cars, confirmability is becoming an issue. The black-box nature of trained predictors make it difficult to trace failure cases or to understand the internal reasoning processes leading to results. In this paper we introduce a novel efficient method to visualise evidence that lead to decisions in CNNs. In contrast to network fixation or saliency map methods, our method is able to illustrate the evidence for or against a classifier's decision in input pixel space approximately 10 times faster than previous methods. We also show that our approach is less prone to noise and can focus on the most relevant input regions, thus making it more accurate and interpretable. Moreover, by making simplifications we link our method with other visualisation methods, providing a general explanation for gradient-based visualisation techniques. We believe that our work makes network introspection more feasible for debugging and understanding deep convolutional networks. This will increase trust between humans and deep learning models.