 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedVG: Gradient-Guided Aggregation for Enhanced Federated Learning
Feb 24, 2026Federated Learning (FL) enables collaborative model training across multiple clients without sharing their private data. However, data heterogeneity across clients leads to client drift, which degrades the overall generalization performance of the model. This effect is further compounded by overemphasis on poorly performing clients. To address this problem, we propose FedVG, a novel gradient-based federated aggregation framework that leverages a global validation set to guide the optimization process. Such a global validation set can be established using readily available public datasets, ensuring accessibility and consistency across clients without compromising privacy. In contrast to conventional approaches that prioritize client dataset volume, FedVG assesses the generalization ability of client models by measuring the magnitude of validation gradients across layers. Specifically, we compute layerwise gradient norms to derive a client-specific score that reflects how much each client needs to adjust for improved generalization on the global validation set, thereby enabling more informed and adaptive federated aggregation. Extensive experiments on both natural and medical image benchmarking datasets, across diverse model architectures, demonstrate that FedVG consistently improves performance, particularly in highly heterogeneous settings. Moreover, FedVG is modular and can be seamlessly integrated with various state-of-the-art FL algorithms, often further improving their results. Our code is available at https://github.com/alinadevkota/FedVG.
Enhancing Retinal Disease Classification from OCTA Images via Active Learning Techniques
Jul 21, 2024Eye diseases are common in older Americans and can lead to decreased vision and blindness. Recent advancements in imaging technologies allow clinicians to capture high-quality images of the retinal blood vessels via Optical Coherence Tomography Angiography (OCTA), which contain vital information for diagnosing these diseases and expediting preventative measures. OCTA provides detailed vascular imaging as compared to the solely structural information obtained by common OCT imaging. Although there have been considerable studies on OCT imaging, there have been limited to no studies exploring the role of artificial intelligence (AI) and machine learning (ML) approaches for predictive modeling with OCTA images. In this paper, we explore the use of deep learning to identify eye disease in OCTA images. However, due to the lack of labeled data, the straightforward application of deep learning doesn't necessarily yield good generalization. To this end, we utilize active learning to select the most valuable subset of data to train our model. We demonstrate that active learning subset selection greatly outperforms other strategies, such as inverse frequency class weighting, random undersampling, and oversampling, by up to 49% in F1 evaluation.
TE-SSL: Time and Event-aware Self Supervised Learning for Alzheimer's Disease Progression Analysis
Jul 09, 2024


Alzheimer's Dementia (AD) represents one of the most pressing challenges in the field of neurodegenerative disorders, with its progression analysis being crucial for understanding disease dynamics and developing targeted interventions. Recent advancements in deep learning and various representation learning strategies, including self-supervised learning (SSL), have shown significant promise in enhancing medical image analysis, providing innovative ways to extract meaningful patterns from complex data. Notably, the computer vision literature has demonstrated that incorporating supervisory signals into SSL can further augment model performance by guiding the learning process with additional relevant information. However, the application of such supervisory signals in the context of disease progression analysis remains largely unexplored. This gap is particularly pronounced given the inherent challenges of incorporating both event and time-to-event information into the learning paradigm. Addressing this, we propose a novel framework, Time and Even-aware SSL (TE-SSL), which integrates time-to-event and event data as supervisory signals to refine the learning process. Our comparative analysis with existing SSL-based methods in the downstream task of survival analysis shows superior performance across standard metrics.
Segmentation of Maya hieroglyphs through fine-tuned foundation models
May 26, 2024



The study of Maya hieroglyphic writing unlocks the rich history of cultural and societal knowledge embedded within this ancient civilization's visual narrative. Artificial Intelligence (AI) offers a novel lens through which we can translate these inscriptions, with the potential to allow non-specialists access to reading these texts and to aid in the decipherment of those hieroglyphs which continue to elude comprehensive interpretation. Toward this, we leverage a foundational model to segment Maya hieroglyphs from an open-source digital library dedicated to Maya artifacts. Despite the initial promise of publicly available foundational segmentation models, their effectiveness in accurately segmenting Maya hieroglyphs was initially limited. Addressing this challenge, our study involved the meticulous curation of image and label pairs with the assistance of experts in Maya art and history, enabling the fine-tuning of these foundational models. This process significantly enhanced model performance, illustrating the potential of fine-tuning approaches and the value of our expanding dataset. We plan to open-source this dataset for encouraging future research, and eventually to help make the hieroglyphic texts legible to a broader community, particularly for Maya heritage community members.
Exploring Speech Pattern Disorders in Autism using Machine Learning
May 03, 2024
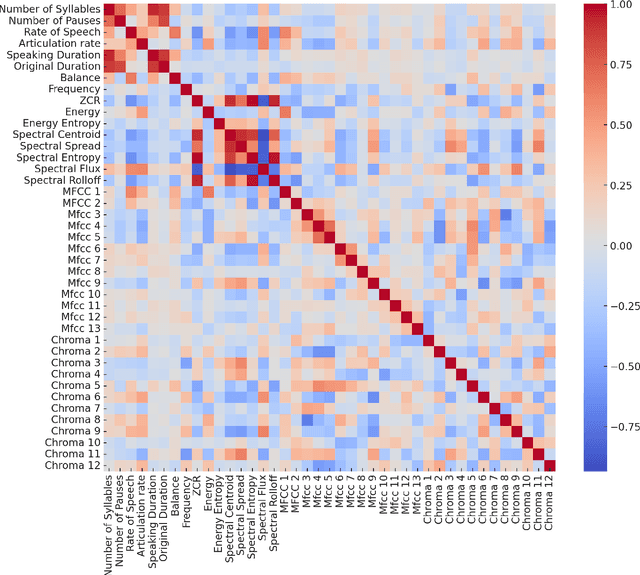
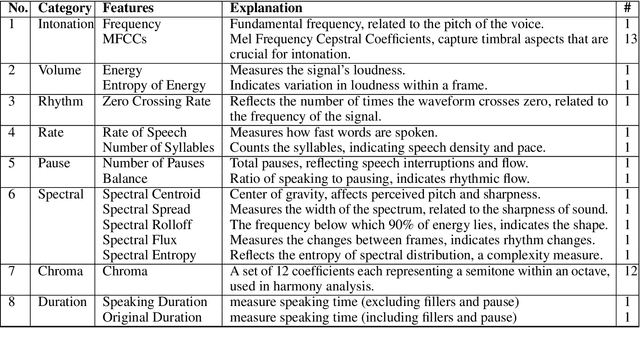
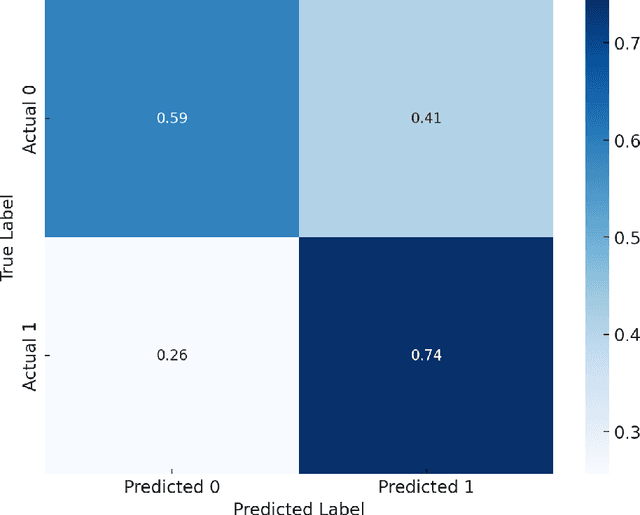
Diagnosing autism spectrum disorder (ASD) by identifying abnormal speech patterns from examiner-patient dialogues presents significant challenges due to the subtle and diverse manifestations of speech-related symptoms in affected individuals. This study presents a comprehensive approach to identify distinctive speech patterns through the analysis of examiner-patient dialogues. Utilizing a dataset of recorded dialogues, we extracted 40 speech-related features, categorized into frequency, zero-crossing rate, energy, spectral characteristics, Mel Frequency Cepstral Coefficients (MFCCs), and balance. These features encompass various aspects of speech such as intonation, volume, rhythm, and speech rate, reflecting the complex nature of communicative behaviors in ASD. We employed machine learning for both classification and regression tasks to analyze these speech features. The classification model aimed to differentiate between ASD and non-ASD cases, achieving an accuracy of 87.75%. Regression models were developed to predict speech pattern related variables and a composite score from all variables, facilitating a deeper understanding of the speech dynamics associated with ASD. The effectiveness of machine learning in interpreting intricate speech patterns and the high classification accuracy underscore the potential of computational methods in supporting the diagnostic processes for ASD. This approach not only aids in early detection but also contributes to personalized treatment planning by providing insights into the speech and communication profiles of individuals with ASD.
Multimodal Federated Learning in Healthcare: a review
Oct 14, 2023



Recent advancements in multimodal machine learning have empowered the development of accurate and robust AI systems in the medical domain, especially within centralized database systems. Simultaneously, Federated Learning (FL) has progressed, providing a decentralized mechanism where data need not be consolidated, thereby enhancing the privacy and security of sensitive healthcare data. The integration of these two concepts supports the ongoing progress of multimodal learning in healthcare while ensuring the security and privacy of patient records within local data-holding agencies. This paper offers a concise overview of the significance of FL in healthcare and outlines the current state-of-the-art approaches to Multimodal Federated Learning (MMFL) within the healthcare domain. It comprehensively examines the existing challenges in the field, shedding light on the limitations of present models. Finally, the paper outlines potential directions for future advancements in the field, aiming to bridge the gap between cutting-edge AI technology and the imperative need for patient data privacy in healthcare applications.
UPDExplainer: an Interpretable Transformer-based Framework for Urban Physical Disorder Detection Using Street View Imagery
May 04, 2023Urban Physical Disorder (UPD), such as old or abandoned buildings, broken sidewalks, litter, and graffiti, has a negative impact on residents' quality of life. They can also increase crime rates, cause social disorder, and pose a public health risk. Currently, there is a lack of efficient and reliable methods for detecting and understanding UPD. To bridge this gap, we propose UPDExplainer, an interpretable transformer-based framework for UPD detection. We first develop a UPD detection model based on the Swin Transformer architecture, which leverages readily accessible street view images to learn discriminative representations. In order to provide clear and comprehensible evidence and analysis, we subsequently introduce a UPD factor identification and ranking module that combines visual explanation maps with semantic segmentation maps. This novel integrated approach enables us to identify the exact objects within street view images that are responsible for physical disorders and gain insights into the underlying causes. Experimental results on the re-annotated Place Pulse 2.0 dataset demonstrate promising detection performance of the proposed method, with an accuracy of 79.9%. For a comprehensive evaluation of the method's ranking performance, we report the mean Average Precision (mAP), R-Precision (RPrec), and Normalized Discounted Cumulative Gain (NDCG), with success rates of 75.51%, 80.61%, and 82.58%, respectively. We also present a case study of detecting and ranking physical disorders in the southern region of downtown Los Angeles, California, to demonstrate the practicality and effectiveness of our framework.