 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAISI: Medical AI for Synthetic Imaging
Sep 13, 2024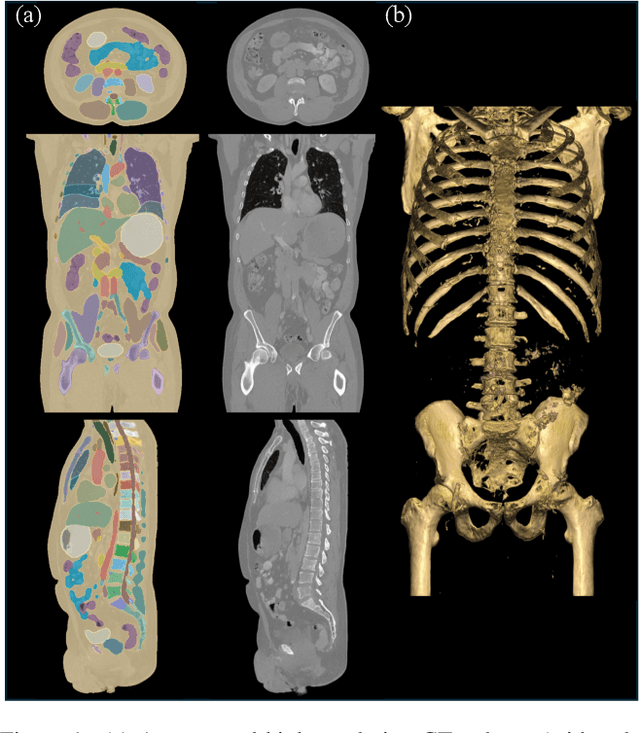
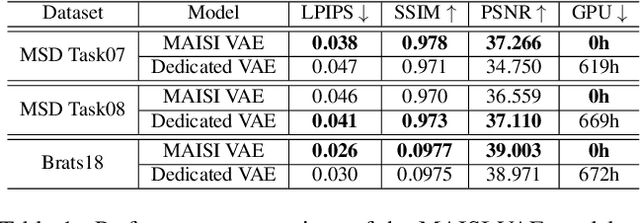
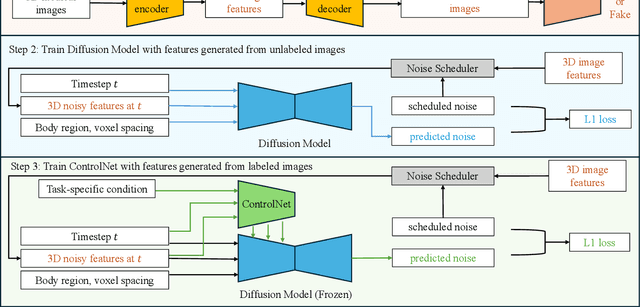
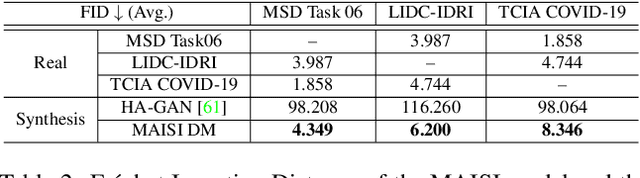
Medical imaging analysis faces challenges such as data scarcity, high annotation costs, and privacy concerns. This paper introduces the Medical AI for Synthetic Imaging (MAISI), an innovative approach using the diffusion model to generate synthetic 3D computed tomography (CT) images to address those challenges. MAISI leverages the foundation volume compression network and the latent diffusion model to produce high-resolution CT images (up to a landmark volume dimension of 512 x 512 x 768 ) with flexible volume dimensions and voxel spacing. By incorporating ControlNet, MAISI can process organ segmentation, including 127 anatomical structures, as additional conditions and enables the generation of accurately annotated synthetic images that can be used for various downstream tasks. Our experiment results show that MAISI's capabilities in generating realistic, anatomically accurate images for diverse regions and conditions reveal its promising potential to mitigate challenges using synthetic data.
VISTA3D: Versatile Imaging SegmenTation and Annotation model for 3D Computed Tomography
Jun 07, 2024Segmentation foundation models have attracted great interest, however, none of them are adequate enough for the use cases in 3D computed tomography scans (CT) images. Existing works finetune on medical images with 2D foundation models trained on natural images, but interactive segmentation, especially in 2D, is too time-consuming for 3D scans and less useful for large cohort analysis. Models that can perform out-of-the-box automatic segmentation are more desirable. However, the model trained in this way lacks the ability to perform segmentation on unseen objects like novel tumors. Thus for 3D medical image analysis, an ideal segmentation solution might expect two features: accurate out-of-the-box performance covering major organ classes, and effective adaptation or zero-shot ability to novel structures. In this paper, we discuss what features a 3D CT segmentation foundation model should have, and introduce VISTA3D, Versatile Imaging SegmenTation and Annotation model. The model is trained systematically on 11454 volumes encompassing 127 types of human anatomical structures and various lesions and provides accurate out-of-the-box segmentation. The model's design also achieves state-of-the-art zero-shot interactive segmentation in 3D. The novel model design and training recipe represent a promising step toward developing a versatile medical image foundation model. Code and model weights will be released shortly. The early version of online demo can be tried on https://build.nvidia.com/nvidia/vista-3d.