 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign then Refine: Text-Guided 3D Prostate Lesion Segmentation
Apr 20, 2026Automated 3D segmentation of prostate lesions from biparametric MRI (bp-MRI) is essential for reliable algorithmic analysis, but achieving high precision remains challenging. Volumetric methods must combine multiple modalities while ensuring anatomical consistency, but current models struggle to integrate cross-modal information reliably. While vision-language models (VLMs) are replacing the currently used architectural designs, they still lack the fine-grained, lesion-level semantics required for effective localized guidance. To address these limitations, we propose a new multi-encoder U-Net architecture incorporating three key innovations: (1) an alignment loss that enhances foreground text-image similarity to inject lesion semantics; (2) a heatmap loss that calibrates the similarity map and suppresses spurious background activations; and (3) a final-stage, confidence-gated multi-head cross-attention refiner that performs localized boundary edits in high-confidence regions. A phase-scheduled training regime stabilizes the optimization of these components. Our method consistently outperforms prior approaches, establishing a new state-of-the-art on the PI-CAI dataset through enhanced multi-modal fusion and localized text guidance. Our code is available at https://github.com/NUBagciLab/Prostate-Lesion-Segmentation.
OpenPros: A Large-Scale Dataset for Limited View Prostate Ultrasound Computed Tomography
May 18, 2025Prostate cancer is one of the most common and lethal cancers among men, making its early detection critically important. Although ultrasound imaging offers greater accessibility and cost-effectiveness compared to MRI, traditional transrectal ultrasound methods suffer from low sensitivity, especially in detecting anteriorly located tumors. Ultrasound computed tomography provides quantitative tissue characterization, but its clinical implementation faces significant challenges, particularly under anatomically constrained limited-angle acquisition conditions specific to prostate imaging. To address these unmet needs, we introduce OpenPros, the first large-scale benchmark dataset explicitly developed for limited-view prostate USCT. Our dataset includes over 280,000 paired samples of realistic 2D speed-of-sound (SOS) phantoms and corresponding ultrasound full-waveform data, generated from anatomically accurate 3D digital prostate models derived from real clinical MRI/CT scans and ex vivo ultrasound measurements, annotated by medical experts. Simulations are conducted under clinically realistic configurations using advanced finite-difference time-domain and Runge-Kutta acoustic wave solvers, both provided as open-source components. Through comprehensive baseline experiments, we demonstrate that state-of-the-art deep learning methods surpass traditional physics-based approaches in both inference efficiency and reconstruction accuracy. Nevertheless, current deep learning models still fall short of delivering clinically acceptable high-resolution images with sufficient accuracy. By publicly releasing OpenPros, we aim to encourage the development of advanced machine learning algorithms capable of bridging this performance gap and producing clinically usable, high-resolution, and highly accurate prostate ultrasound images. The dataset is publicly accessible at https://open-pros.github.io/.
Text2CT: Towards 3D CT Volume Generation from Free-text Descriptions Using Diffusion Model
May 07, 2025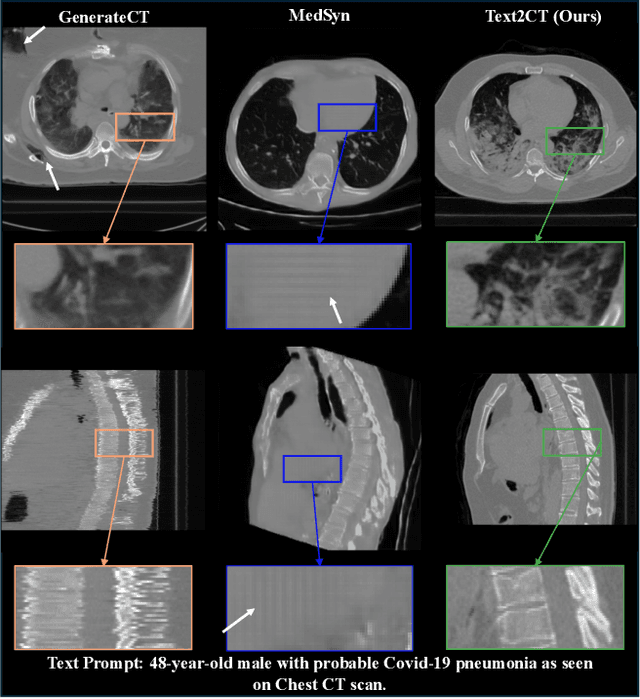
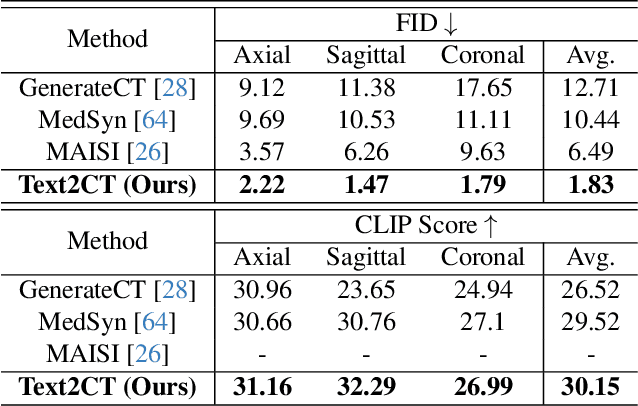
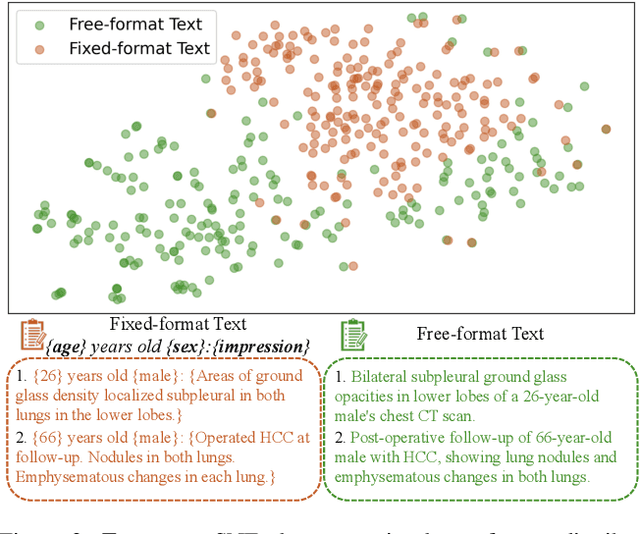
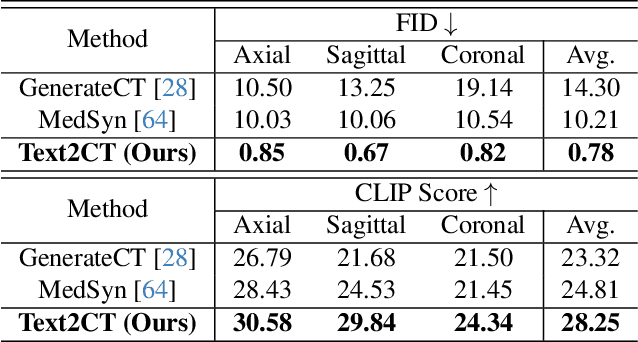
Generating 3D CT volumes from descriptive free-text inputs presents a transformative opportunity in diagnostics and research. In this paper, we introduce Text2CT, a novel approach for synthesizing 3D CT volumes from textual descriptions using the diffusion model. Unlike previous methods that rely on fixed-format text input, Text2CT employs a novel prompt formulation that enables generation from diverse, free-text descriptions. The proposed framework encodes medical text into latent representations and decodes them into high-resolution 3D CT scans, effectively bridging the gap between semantic text inputs and detailed volumetric representations in a unified 3D framework. Our method demonstrates superior performance in preserving anatomical fidelity and capturing intricate structures as described in the input text. Extensive evaluations show that our approach achieves state-of-the-art results, offering promising potential applications in diagnostics, and data augmentation.
VILA-M3: Enhancing Vision-Language Models with Medical Expert Knowledge
Nov 19, 2024



Generalist vision language models (VLMs) have made significant strides in computer vision, but they fall short in specialized fields like healthcare, where expert knowledge is essential. In traditional computer vision tasks, creative or approximate answers may be acceptable, but in healthcare, precision is paramount.Current large multimodal models like Gemini and GPT-4o are insufficient for medical tasks due to their reliance on memorized internet knowledge rather than the nuanced expertise required in healthcare. VLMs are usually trained in three stages: vision pre-training, vision-language pre-training, and instruction fine-tuning (IFT). IFT has been typically applied using a mixture of generic and healthcare data. In contrast, we propose that for medical VLMs, a fourth stage of specialized IFT is necessary, which focuses on medical data and includes information from domain expert models. Domain expert models developed for medical use are crucial because they are specifically trained for certain clinical tasks, e.g. to detect tumors and classify abnormalities through segmentation and classification, which learn fine-grained features of medical data$-$features that are often too intricate for a VLM to capture effectively especially in radiology. This paper introduces a new framework, VILA-M3, for medical VLMs that utilizes domain knowledge via expert models. Through our experiments, we show an improved state-of-the-art (SOTA) performance with an average improvement of ~9% over the prior SOTA model Med-Gemini and ~6% over models trained on the specific tasks. Our approach emphasizes the importance of domain expertise in creating precise, reliable VLMs for medical applications.
MAISI: Medical AI for Synthetic Imaging
Sep 13, 2024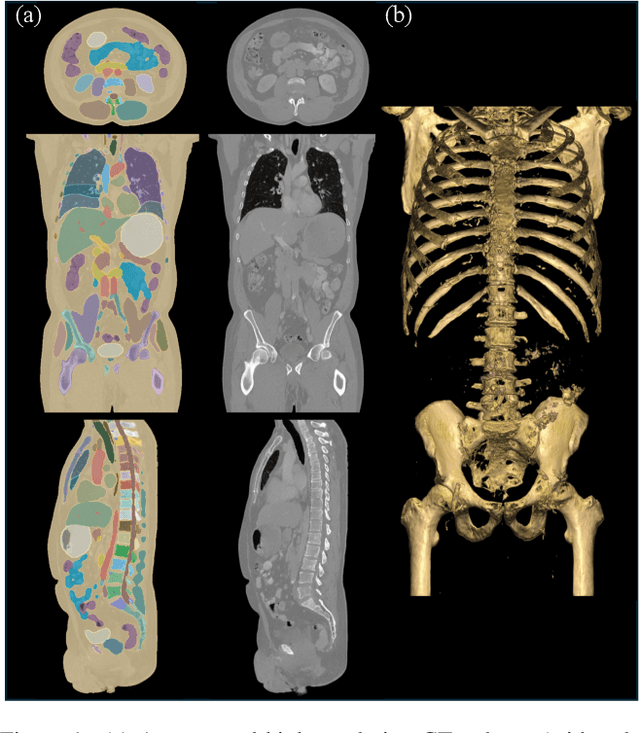
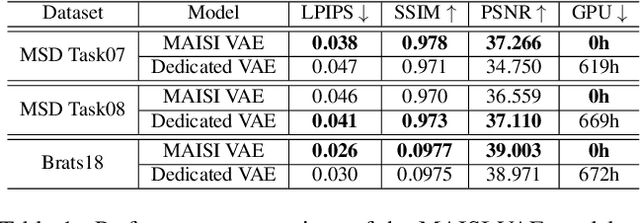
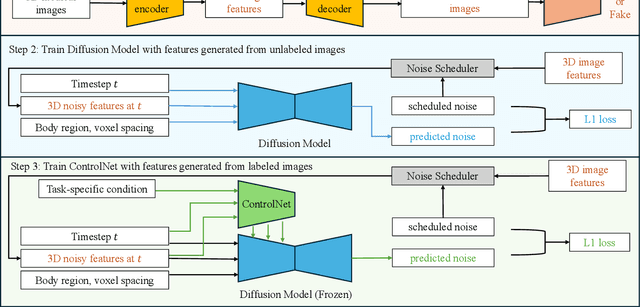
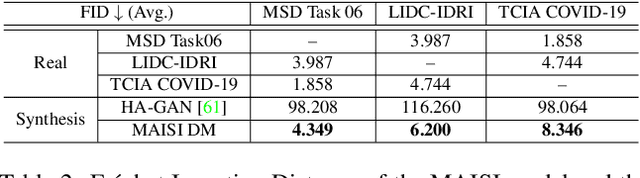
Medical imaging analysis faces challenges such as data scarcity, high annotation costs, and privacy concerns. This paper introduces the Medical AI for Synthetic Imaging (MAISI), an innovative approach using the diffusion model to generate synthetic 3D computed tomography (CT) images to address those challenges. MAISI leverages the foundation volume compression network and the latent diffusion model to produce high-resolution CT images (up to a landmark volume dimension of 512 x 512 x 768 ) with flexible volume dimensions and voxel spacing. By incorporating ControlNet, MAISI can process organ segmentation, including 127 anatomical structures, as additional conditions and enables the generation of accurately annotated synthetic images that can be used for various downstream tasks. Our experiment results show that MAISI's capabilities in generating realistic, anatomically accurate images for diverse regions and conditions reveal its promising potential to mitigate challenges using synthetic data.
Location-based Radiology Report-Guided Semi-supervised Learning for Prostate Cancer Detection
Jun 18, 2024Prostate cancer is one of the most prevalent malignancies in the world. While deep learning has potential to further improve computer-aided prostate cancer detection on MRI, its efficacy hinges on the exhaustive curation of manually annotated images. We propose a novel methodology of semisupervised learning (SSL) guided by automatically extracted clinical information, specifically the lesion locations in radiology reports, allowing for use of unannotated images to reduce the annotation burden. By leveraging lesion locations, we refined pseudo labels, which were then used to train our location-based SSL model. We show that our SSL method can improve prostate lesion detection by utilizing unannotated images, with more substantial impacts being observed when larger proportions of unannotated images are used.
VISTA3D: Versatile Imaging SegmenTation and Annotation model for 3D Computed Tomography
Jun 07, 2024Segmentation foundation models have attracted great interest, however, none of them are adequate enough for the use cases in 3D computed tomography scans (CT) images. Existing works finetune on medical images with 2D foundation models trained on natural images, but interactive segmentation, especially in 2D, is too time-consuming for 3D scans and less useful for large cohort analysis. Models that can perform out-of-the-box automatic segmentation are more desirable. However, the model trained in this way lacks the ability to perform segmentation on unseen objects like novel tumors. Thus for 3D medical image analysis, an ideal segmentation solution might expect two features: accurate out-of-the-box performance covering major organ classes, and effective adaptation or zero-shot ability to novel structures. In this paper, we discuss what features a 3D CT segmentation foundation model should have, and introduce VISTA3D, Versatile Imaging SegmenTation and Annotation model. The model is trained systematically on 11454 volumes encompassing 127 types of human anatomical structures and various lesions and provides accurate out-of-the-box segmentation. The model's design also achieves state-of-the-art zero-shot interactive segmentation in 3D. The novel model design and training recipe represent a promising step toward developing a versatile medical image foundation model. Code and model weights will be released shortly. The early version of online demo can be tried on https://build.nvidia.com/nvidia/vista-3d.
Large-Scale Multi-Center CT and MRI Segmentation of Pancreas with Deep Learning
May 20, 2024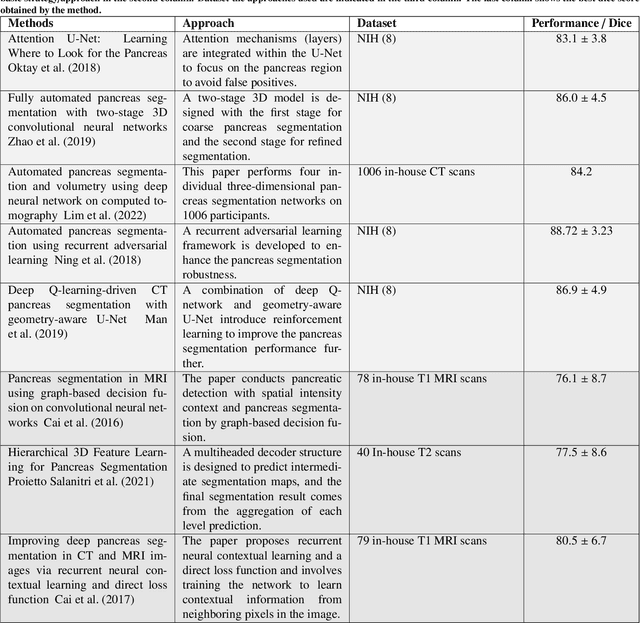
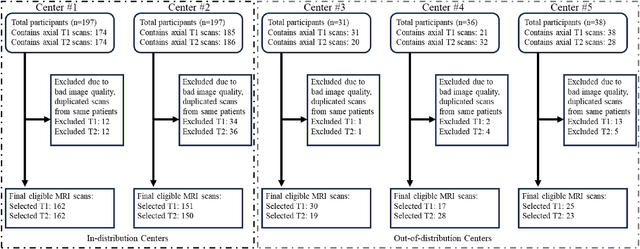
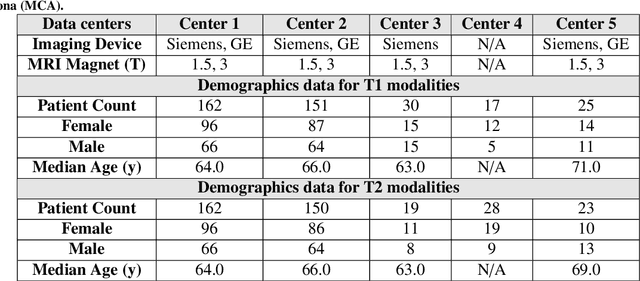
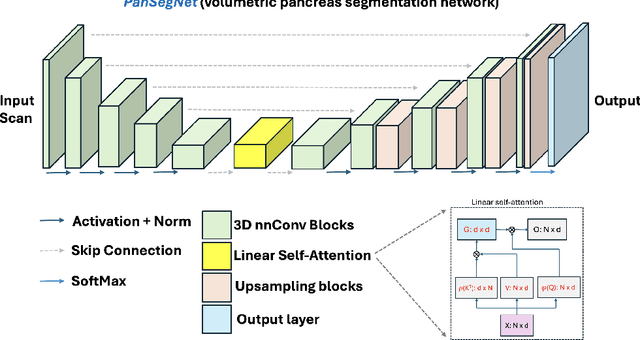
Automated volumetric segmentation of the pancreas on cross-sectional imaging is needed for diagnosis and follow-up of pancreatic diseases. While CT-based pancreatic segmentation is more established, MRI-based segmentation methods are understudied, largely due to a lack of publicly available datasets, benchmarking research efforts, and domain-specific deep learning methods. In this retrospective study, we collected a large dataset (767 scans from 499 participants) of T1-weighted (T1W) and T2-weighted (T2W) abdominal MRI series from five centers between March 2004 and November 2022. We also collected CT scans of 1,350 patients from publicly available sources for benchmarking purposes. We developed a new pancreas segmentation method, called PanSegNet, combining the strengths of nnUNet and a Transformer network with a new linear attention module enabling volumetric computation. We tested PanSegNet's accuracy in cross-modality (a total of 2,117 scans) and cross-center settings with Dice and Hausdorff distance (HD95) evaluation metrics. We used Cohen's kappa statistics for intra and inter-rater agreement evaluation and paired t-tests for volume and Dice comparisons, respectively. For segmentation accuracy, we achieved Dice coefficients of 88.3% (std: 7.2%, at case level) with CT, 85.0% (std: 7.9%) with T1W MRI, and 86.3% (std: 6.4%) with T2W MRI. There was a high correlation for pancreas volume prediction with R^2 of 0.91, 0.84, and 0.85 for CT, T1W, and T2W, respectively. We found moderate inter-observer (0.624 and 0.638 for T1W and T2W MRI, respectively) and high intra-observer agreement scores. All MRI data is made available at https://osf.io/kysnj/. Our source code is available at https://github.com/NUBagciLab/PaNSegNet.
Detection of Peri-Pancreatic Edema using Deep Learning and Radiomics Techniques
Apr 25, 2024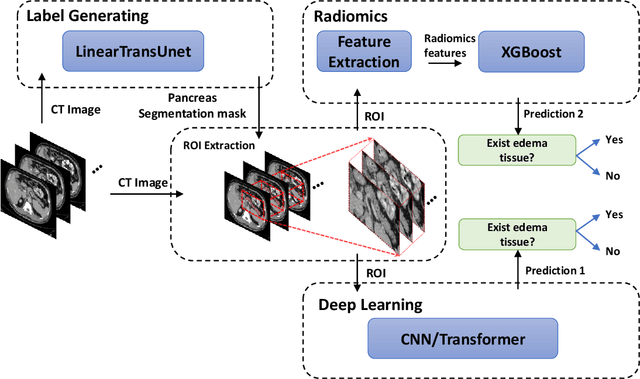
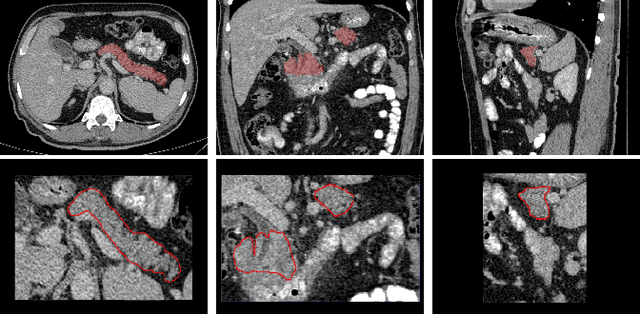
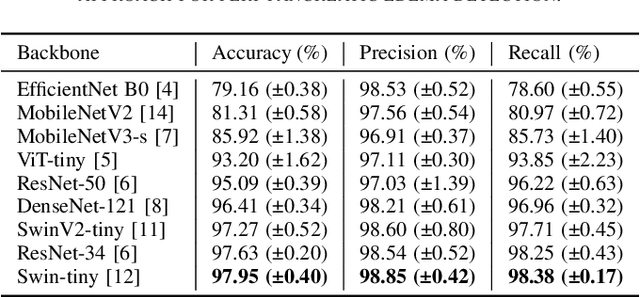
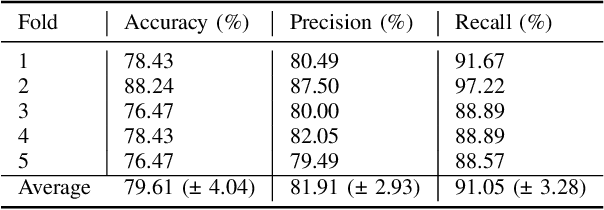
Identifying peri-pancreatic edema is a pivotal indicator for identifying disease progression and prognosis, emphasizing the critical need for accurate detection and assessment in pancreatitis diagnosis and management. This study \textit{introduces a novel CT dataset sourced from 255 patients with pancreatic diseases, featuring annotated pancreas segmentation masks and corresponding diagnostic labels for peri-pancreatic edema condition}. With the novel dataset, we first evaluate the efficacy of the \textit{LinTransUNet} model, a linear Transformer based segmentation algorithm, to segment the pancreas accurately from CT imaging data. Then, we use segmented pancreas regions with two distinctive machine learning classifiers to identify existence of peri-pancreatic edema: deep learning-based models and a radiomics-based eXtreme Gradient Boosting (XGBoost). The LinTransUNet achieved promising results, with a dice coefficient of 80.85\%, and mIoU of 68.73\%. Among the nine benchmarked classification models for peri-pancreatic edema detection, \textit{Swin-Tiny} transformer model demonstrated the highest recall of $98.85 \pm 0.42$ and precision of $98.38\pm 0.17$. Comparatively, the radiomics-based XGBoost model achieved an accuracy of $79.61\pm4.04$ and recall of $91.05\pm3.28$, showcasing its potential as a supplementary diagnostic tool given its rapid processing speed and reduced training time. Our code is available \url{https://github.com/NUBagciLab/Peri-Pancreatic-Edema-Detection}.
A Probabilistic Hadamard U-Net for MRI Bias Field Correction
Mar 08, 2024Magnetic field inhomogeneity correction remains a challenging task in MRI analysis. Most established techniques are designed for brain MRI by supposing that image intensities in the identical tissue follow a uniform distribution. Such an assumption cannot be easily applied to other organs, especially those that are small in size and heterogeneous in texture (large variations in intensity), such as the prostate. To address this problem, this paper proposes a probabilistic Hadamard U-Net (PHU-Net) for prostate MRI bias field correction. First, a novel Hadamard U-Net (HU-Net) is introduced to extract the low-frequency scalar field, multiplied by the original input to obtain the prototypical corrected image. HU-Net converts the input image from the time domain into the frequency domain via Hadamard transform. In the frequency domain, high-frequency components are eliminated using the trainable filter (scaling layer), hard-thresholding layer, and sparsity penalty. Next, a conditional variational autoencoder is used to encode possible bias field-corrected variants into a low-dimensional latent space. Random samples drawn from latent space are then incorporated with a prototypical corrected image to generate multiple plausible images. Experimental results demonstrate the effectiveness of PHU-Net in correcting bias-field in prostate MRI with a fast inference speed. It has also been shown that prostate MRI segmentation accuracy improves with the high-quality corrected images from PHU-Net. The code will be available in the final version of this manuscript.