 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large Scale Open-Source Image and Video Dataset for Robust Wildfire Detection and Classification
Jun 08, 2026Wildfire detection and monitoring are critical for mitigating fire spread and reducing environmental and infrastructural damage. In this work, we introduce GWFP (Global Wildfire Prevention Dataset), a large-scale, open-source dataset of wildfire images and videos designed to support early fire and smoke detection research. GWFP contains geographically diverse wildfire scenes, including flames, smoke, Waterdog/Fog environmental conditions, Near Infrared (NIR) imagery, Ember, and challenging negative samples collected from real-world scenarios worldwide. To evaluate dataset robustness and cross-domain generalization, we benchmark multiple convolutional and transformer-based architectures across both in-domain and cross-dataset settings. Additionally, we explore lightweight frequency--spatial feature interaction using Hadamard-enhanced residual connections (HTE-ResNet) to analyze representation robustness under domain-shift conditions. Experimental results demonstrate strong cross-dataset generalization and practical utility for real-world wildfire monitoring applications. The dataset and source code will be publicly released upon acceptance.
DynGhost: Temporally-Modelled Transformer for Dynamic Ghost Imaging with Quantum Detectors
May 11, 2026Ghost imaging reconstructs spatial information from a single-pixel bucket detector by correlating structured illumination patterns with scalar intensity measurements. While deep learning approaches have achieved promising results on static scenes, two critical limitations remain unaddressed: existing architectures fail to exploit temporal coherence across frames, leaving dynamic ghost imaging largely unsolved, and they assume additive Gaussian noise models that do not reflect the true Poissonian statistics of real single-photon hardware. We present DynGhost (Dynamic Ghost Imaging Transformer), a transformer architecture that addresses both limitations through alternating spatial and temporal attention blocks. Our quantum-aware training framework, based on physically accurate detector simulations (SNSPDs, SPADs, SiPMs) and Anscombe variance-stabilizing normalization, resolves the distribution shift that causes classical models to fail under realistic hardware constraints. Experiments across multiple benchmarks demonstrate that DynGhost outperforms both traditional reconstruction methods and existing deep learning architectures, with particular gains in dynamic and photon-starved settings.
Progressive Deep Learning for Automated Spheno-Occipital Synchondrosis Maturation Assessment
Apr 13, 2026Accurate assessment of spheno-occipital synchondrosis (SOS) maturation is a key indicator of craniofacial growth and a critical determinant for orthodontic and surgical timing. However, SOS staging from cone-beam CT (CBCT) relies on subtle, continuously evolving morphological cues, leading to high inter-observer variability and poor reproducibility, especially at transitional fusion stages. We frame SOS assessment as a fine-grained visual recognition problem and propose a progressive representation-learning framework that explicitly mirrors how expert clinicians reason about synchondral fusion: from coarse anatomical structure to increasingly subtle patterns of closure. Rather than training a full-capacity network end-to-end, we sequentially grow the model by activating deeper blocks over time, allowing early layers to first encode stable cranial base morphology before higher-level layers specialize in discriminating adjacent maturation stages. This yields a curriculum over network depth that aligns deep feature learning with the biological continuum of SOS fusion. Extensive experiments across convolutional and transformer-based architectures show that this expert-inspired training strategy produces more stable optimization and consistently higher accuracy than standard training, particularly for ambiguous intermediate stages. Importantly, these gains are achieved without changing network architectures or loss functions, demonstrating that training dynamics alone can substantially improve anatomical representation learning. The proposed framework establishes a principled link between expert dental intuition and deep visual representations, enabling robust, data-efficient SOS staging from CBCT and offering a general strategy for modeling other continuous biological processes in medical imaging.
WTHaar-Net: a Hybrid Quantum-Classical Approach
Mar 03, 2026Convolutional neural networks rely on linear filtering operations that can be reformulated efficiently in suitable transform domains. At the same time, advances in quantum computing have shown that certain structured linear transforms can be implemented with shallow quantum circuits, opening the door to hybrid quantum-classical approaches for enhancing deep learning models. In this work, we introduce WTHaar-Net, a convolutional neural network that replaces the Hadamard Transform used in prior hybrid architectures with the Haar Wavelet Transform (HWT). Unlike the Hadamard Transform, the Haar transform provides spatially localized, multi-resolution representations that align more closely with the inductive biases of vision tasks. We show that the HWT admits a quantum realization using structured Hadamard gates, enabling its decomposition into unitary operations suitable for quantum circuits. Experiments on CIFAR-10 and Tiny-ImageNet demonstrate that WTHaar-Net achieves substantial parameter reduction while maintaining competitive accuracy. On Tiny-ImageNet, our approach outperforms both ResNet and Hadamard-based baselines. We validate the quantum implementation on IBM Quantum cloud hardware, demonstrating compatibility with near-term quantum devices.
Deep Learning Based Wildfire Detection for Peatland Fires Using Transfer Learning
Mar 02, 2026Machine learning (ML)-based wildfire detection methods have been developed in recent years, primarily using deep learning (DL) models trained on large collections of wildfire images and videos. However, peatland fires exhibit distinct visual and physical characteristics -- such as smoldering combustion, low flame intensity, persistent smoke, and subsurface burning -- that limit the effectiveness of conventional wildfire detectors trained on open-flame forest fires. In this work, we present a transfer learning-based approach for peatland fire detection that leverages knowledge learned from general wildfire imagery and adapts it to the peatland fire domain. We initialize a DL-based peatland fire detector using pretrained weights from a conventional wildfire detection model and subsequently fine-tune the network using a dataset composed of Malaysian peatland images and videos. This strategy enables effective learning despite the limited availability of labeled peatland fire data. Experimental results demonstrate that transfer learning significantly improves detection accuracy and robustness compared to training from scratch, particularly under challenging conditions such as low-contrast smoke, partial occlusions, and variable illumination. The proposed approach provides a practical and scalable solution for early peatland fire detection and has the potential to support real-time monitoring systems for fire prevention and environmental protection.
U-Net with Hadamard Transform and DCT Latent Spaces for Next-day Wildfire Spread Prediction
Feb 12, 2026We developed a lightweight and computationally efficient tool for next-day wildfire spread prediction using multimodal satellite data as input. The deep learning model, which we call Transform Domain Fusion UNet (TD-FusionUNet), incorporates trainable Hadamard Transform and Discrete Cosine Transform layers that apply two-dimensional transforms, enabling the network to capture essential "frequency" components in orthogonalized latent spaces. Additionally, we introduce custom preprocessing techniques, including random margin cropping and a Gaussian mixture model, to enrich the representation of the sparse pre-fire masks and enhance the model's generalization capability. The TD-FusionUNet is evaluated on two datasets which are the Next-Day Wildfire Spread dataset released by Google Research in 2023, and WildfireSpreadTS dataset. Our proposed TD-FusionUNet achieves an F1 score of 0.591 with 370k parameters, outperforming the UNet baseline using ResNet18 as the encoder reported in the WildfireSpreadTS dataset while using substantially fewer parameters. These results show that the proposed latent space fusion model balances accuracy and efficiency under a lightweight setting, making it suitable for real time wildfire prediction applications in resource limited environments.
Intelligent Incident Hypertension Prediction in Obstructive Sleep Apnea
May 27, 2025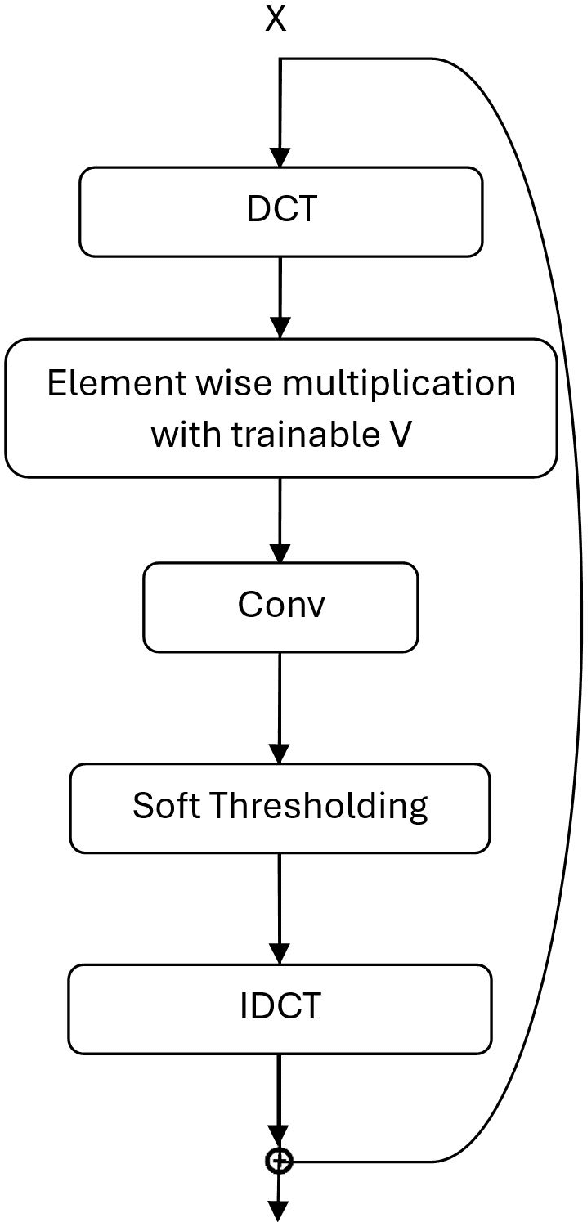



Obstructive sleep apnea (OSA) is a significant risk factor for hypertension, primarily due to intermittent hypoxia and sleep fragmentation. Predicting whether individuals with OSA will develop hypertension within five years remains a complex challenge. This study introduces a novel deep learning approach that integrates Discrete Cosine Transform (DCT)-based transfer learning to enhance prediction accuracy. We are the first to incorporate all polysomnography signals together for hypertension prediction, leveraging their collective information to improve model performance. Features were extracted from these signals and transformed into a 2D representation to utilize pre-trained 2D neural networks such as MobileNet, EfficientNet, and ResNet variants. To further improve feature learning, we introduced a DCT layer, which transforms input features into a frequency-based representation, preserving essential spectral information, decorrelating features, and enhancing robustness to noise. This frequency-domain approach, coupled with transfer learning, is especially beneficial for limited medical datasets, as it leverages rich representations from pre-trained networks to improve generalization. By strategically placing the DCT layer at deeper truncation depths within EfficientNet, our model achieved a best area under the curve (AUC) of 72.88%, demonstrating the effectiveness of frequency-domain feature extraction and transfer learning in predicting hypertension risk in OSA patients over a five-year period.
Knowledge Distillation Approach for SOS Fusion Staging: Towards Fully Automated Skeletal Maturity Assessment
May 27, 2025



We introduce a novel deep learning framework for the automated staging of spheno-occipital synchondrosis (SOS) fusion, a critical diagnostic marker in both orthodontics and forensic anthropology. Our approach leverages a dual-model architecture wherein a teacher model, trained on manually cropped images, transfers its precise spatial understanding to a student model that operates on full, uncropped images. This knowledge distillation is facilitated by a newly formulated loss function that aligns spatial logits as well as incorporates gradient-based attention spatial mapping, ensuring that the student model internalizes the anatomically relevant features without relying on external cropping or YOLO-based segmentation. By leveraging expert-curated data and feedback at each step, our framework attains robust diagnostic accuracy, culminating in a clinically viable end-to-end pipeline. This streamlined approach obviates the need for additional pre-processing tools and accelerates deployment, thereby enhancing both the efficiency and consistency of skeletal maturation assessment in diverse clinical settings.
Gradient Attention Map Based Verification of Deep Convolutional Neural Networks with Application to X-ray Image Datasets
Apr 29, 2025

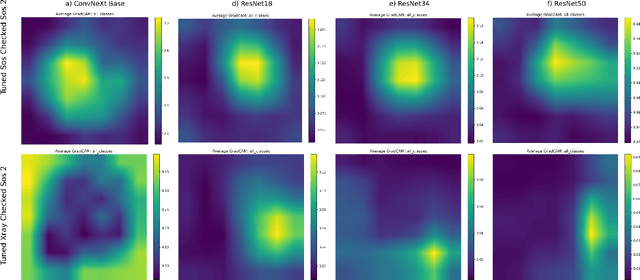

Deep learning models have great potential in medical imaging, including orthodontics and skeletal maturity assessment. However, applying a model to data different from its training set can lead to unreliable predictions that may impact patient care. To address this, we propose a comprehensive verification framework that evaluates model suitability through multiple complementary strategies. First, we introduce a Gradient Attention Map (GAM)-based approach that analyzes attention patterns using Grad-CAM and compares them via similarity metrics such as IoU, Dice Similarity, SSIM, Cosine Similarity, Pearson Correlation, KL Divergence, and Wasserstein Distance. Second, we extend verification to early convolutional feature maps, capturing structural mis-alignments missed by attention alone. Finally, we incorporate an additional garbage class into the classification model to explicitly reject out-of-distribution inputs. Experimental results demonstrate that these combined methods effectively identify unsuitable models and inputs, promoting safer and more reliable deployment of deep learning in medical imaging.
Shifts in Doctors' Eye Movements Between Real and AI-Generated Medical Images
Apr 21, 2025Eye-tracking analysis plays a vital role in medical imaging, providing key insights into how radiologists visually interpret and diagnose clinical cases. In this work, we first analyze radiologists' attention and agreement by measuring the distribution of various eye-movement patterns, including saccades direction, amplitude, and their joint distribution. These metrics help uncover patterns in attention allocation and diagnostic strategies. Furthermore, we investigate whether and how doctors' gaze behavior shifts when viewing authentic (Real) versus deep-learning-generated (Fake) images. To achieve this, we examine fixation bias maps, focusing on first, last, short, and longest fixations independently, along with detailed saccades patterns, to quantify differences in gaze distribution and visual saliency between authentic and synthetic images.