 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Based Wildfire Detection for Peatland Fires Using Transfer Learning
Mar 02, 2026Machine learning (ML)-based wildfire detection methods have been developed in recent years, primarily using deep learning (DL) models trained on large collections of wildfire images and videos. However, peatland fires exhibit distinct visual and physical characteristics -- such as smoldering combustion, low flame intensity, persistent smoke, and subsurface burning -- that limit the effectiveness of conventional wildfire detectors trained on open-flame forest fires. In this work, we present a transfer learning-based approach for peatland fire detection that leverages knowledge learned from general wildfire imagery and adapts it to the peatland fire domain. We initialize a DL-based peatland fire detector using pretrained weights from a conventional wildfire detection model and subsequently fine-tune the network using a dataset composed of Malaysian peatland images and videos. This strategy enables effective learning despite the limited availability of labeled peatland fire data. Experimental results demonstrate that transfer learning significantly improves detection accuracy and robustness compared to training from scratch, particularly under challenging conditions such as low-contrast smoke, partial occlusions, and variable illumination. The proposed approach provides a practical and scalable solution for early peatland fire detection and has the potential to support real-time monitoring systems for fire prevention and environmental protection.
Sparse Mamba: Reinforcing Controllability In Structural State Space Models
Aug 31, 2024

In this article, we introduce the concept of controllability and observability to the M amba architecture in our Sparse-Mamba (S-Mamba) for natural language processing (NLP) applications. The structured state space model (SSM) development in recent studies, such as Mamba and Mamba2, outperformed and solved the computational inefficiency of transformers and large language models (LLMs) on longer sequences in small to medium NLP tasks. The Mamba SSMs architecture drops the need for attention layer or MLB blocks in transformers. However, the current Mamba models do not reinforce the controllability on state space equations in the calculation of A, B, C, and D matrices at each time step, which increase the complexity and the computational cost needed. In this article we show that the number of parameters can be significantly decreased by reinforcing controllability in the state space equations in the proposed Sparse-Mamba (S-Mamba), while maintaining the performance. The controllable n x n state matrix A is sparse and it has only n free parameters. Our novel approach will ensure a controllable system and could be the gate key for Mamba 3.
DCT-Based Decorrelated Attention for Vision Transformers
May 22, 2024



Central to the Transformer architectures' effectiveness is the self-attention mechanism, a function that maps queries, keys, and values into a high-dimensional vector space. However, training the attention weights of queries, keys, and values is non-trivial from a state of random initialization. In this paper, we propose two methods. (i) We first address the initialization problem of Vision Transformers by introducing a simple, yet highly innovative, initialization approach utilizing Discrete Cosine Transform (DCT) coefficients. Our proposed DCT-based attention initialization marks a significant gain compared to traditional initialization strategies; offering a robust foundation for the attention mechanism. Our experiments reveal that the DCT-based initialization enhances the accuracy of Vision Transformers in classification tasks. (ii) We also recognize that since DCT effectively decorrelates image information in the frequency domain, this decorrelation is useful for compression because it allows the quantization step to discard many of the higher-frequency components. Based on this observation, we propose a novel DCT-based compression technique for the attention function of Vision Transformers. Since high-frequency DCT coefficients usually correspond to noise, we truncate the high-frequency DCT components of the input patches. Our DCT-based compression reduces the size of weight matrices for queries, keys, and values. While maintaining the same level of accuracy, our DCT compressed Swin Transformers obtain a considerable decrease in the computational overhead.
Wildfire Detection Via Transfer Learning: A Survey
Jun 21, 2023


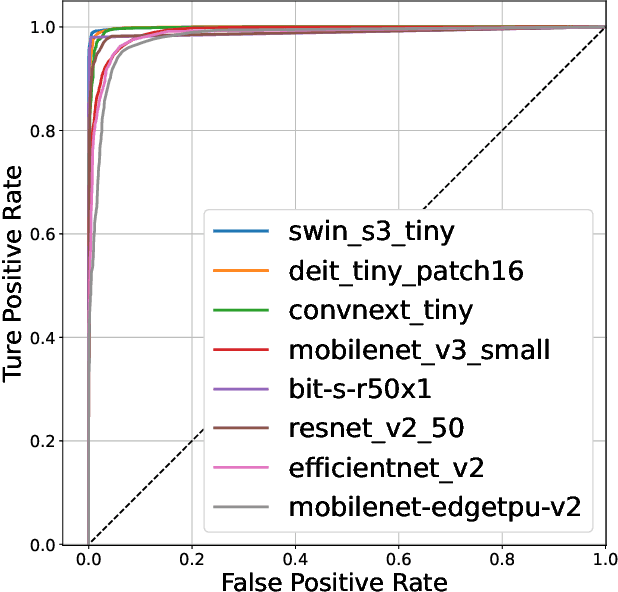
This paper surveys different publicly available neural network models used for detecting wildfires using regular visible-range cameras which are placed on hilltops or forest lookout towers. The neural network models are pre-trained on ImageNet-1K and fine-tuned on a custom wildfire dataset. The performance of these models is evaluated on a diverse set of wildfire images, and the survey provides useful information for those interested in using transfer learning for wildfire detection. Swin Transformer-tiny has the highest AUC value but ConvNext-tiny detects all the wildfire events and has the lowest false alarm rate in our dataset.