 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Image Colorization with Instance-aware Texts and Masks
May 13, 2025Recently, the application of deep learning in image colorization has received widespread attention. The maturation of diffusion models has further advanced the development of image colorization models. However, current mainstream image colorization models still face issues such as color bleeding and color binding errors, and cannot colorize images at the instance level. In this paper, we propose a diffusion-based colorization method MT-Color to achieve precise instance-aware colorization with use-provided guidance. To tackle color bleeding issue, we design a pixel-level mask attention mechanism that integrates latent features and conditional gray image features through cross-attention. We use segmentation masks to construct cross-attention masks, preventing pixel information from exchanging between different instances. We also introduce an instance mask and text guidance module that extracts instance masks and text representations of each instance, which are then fused with latent features through self-attention, utilizing instance masks to form self-attention masks to prevent instance texts from guiding the colorization of other areas, thus mitigating color binding errors. Furthermore, we apply a multi-instance sampling strategy, which involves sampling each instance region separately and then fusing the results. Additionally, we have created a specialized dataset for instance-level colorization tasks, GPT-color, by leveraging large visual language models on existing image datasets. Qualitative and quantitative experiments show that our model and dataset outperform previous methods and datasets.
FineVQ: Fine-Grained User Generated Content Video Quality Assessment
Dec 26, 2024



The rapid growth of user-generated content (UGC) videos has produced an urgent need for effective video quality assessment (VQA) algorithms to monitor video quality and guide optimization and recommendation procedures. However, current VQA models generally only give an overall rating for a UGC video, which lacks fine-grained labels for serving video processing and recommendation applications. To address the challenges and promote the development of UGC videos, we establish the first large-scale Fine-grained Video quality assessment Database, termed FineVD, which comprises 6104 UGC videos with fine-grained quality scores and descriptions across multiple dimensions. Based on this database, we propose a Fine-grained Video Quality assessment (FineVQ) model to learn the fine-grained quality of UGC videos, with the capabilities of quality rating, quality scoring, and quality attribution. Extensive experimental results demonstrate that our proposed FineVQ can produce fine-grained video-quality results and achieve state-of-the-art performance on FineVD and other commonly used UGC-VQA datasets. Both Both FineVD and FineVQ will be made publicly available.
F-Bench: Rethinking Human Preference Evaluation Metrics for Benchmarking Face Generation, Customization, and Restoration
Dec 17, 2024Artificial intelligence generative models exhibit remarkable capabilities in content creation, particularly in face image generation, customization, and restoration. However, current AI-generated faces (AIGFs) often fall short of human preferences due to unique distortions, unrealistic details, and unexpected identity shifts, underscoring the need for a comprehensive quality evaluation framework for AIGFs. To address this need, we introduce FaceQ, a large-scale, comprehensive database of AI-generated Face images with fine-grained Quality annotations reflecting human preferences. The FaceQ database comprises 12,255 images generated by 29 models across three tasks: (1) face generation, (2) face customization, and (3) face restoration. It includes 32,742 mean opinion scores (MOSs) from 180 annotators, assessed across multiple dimensions: quality, authenticity, identity (ID) fidelity, and text-image correspondence. Using the FaceQ database, we establish F-Bench, a benchmark for comparing and evaluating face generation, customization, and restoration models, highlighting strengths and weaknesses across various prompts and evaluation dimensions. Additionally, we assess the performance of existing image quality assessment (IQA), face quality assessment (FQA), AI-generated content image quality assessment (AIGCIQA), and preference evaluation metrics, manifesting that these standard metrics are relatively ineffective in evaluating authenticity, ID fidelity, and text-image correspondence. The FaceQ database will be publicly available upon publication.
Wildfire Detection Via Transfer Learning: A Survey
Jun 21, 2023This paper surveys different publicly available neural network models used for detecting wildfires using regular visible-range cameras which are placed on hilltops or forest lookout towers. The neural network models are pre-trained on ImageNet-1K and fine-tuned on a custom wildfire dataset. The performance of these models is evaluated on a diverse set of wildfire images, and the survey provides useful information for those interested in using transfer learning for wildfire detection. Swin Transformer-tiny has the highest AUC value but ConvNext-tiny detects all the wildfire events and has the lowest false alarm rate in our dataset.
Quality-Constant Per-Shot Encoding by Two-Pass Learning-based Rate Factor Prediction
Aug 23, 2022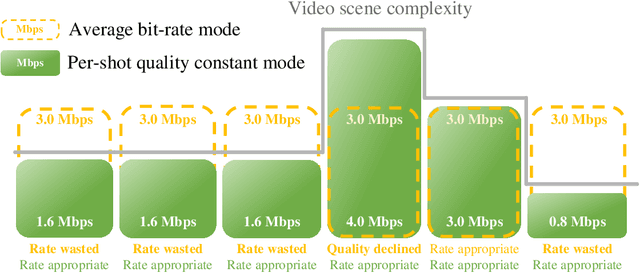

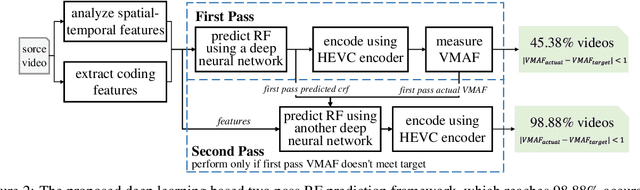
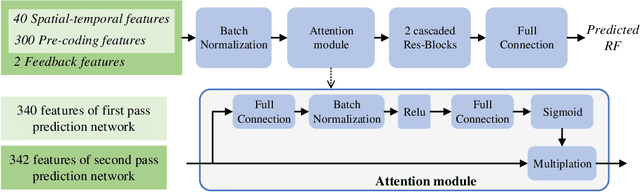
Providing quality-constant streams can simultaneously guarantee user experience and prevent wasting bit-rate. In this paper, we propose a novel deep learning based two-pass encoder parameter prediction framework to decide rate factor (RF), with which encoder can output streams with constant quality. For each one-shot segment in a video, the proposed method firstly extracts spatial, temporal and pre-coding features by an ultra fast pre-process. Based on these features, a RF parameter is predicted by a deep neural network. Video encoder uses the RF to compress segment as the first encoding pass. Then VMAF quality of the first pass encoding is measured. If the quality doesn't meet target, a second pass RF prediction and encoding will be performed. With the help of first pass predicted RF and corresponding actual quality as feedback, the second pass prediction will be highly accurate. Experiments show the proposed method requires only 1.55 times encoding complexity on average, meanwhile the accuracy, that the compressed video's actual VMAF is within $\pm1$ around the target VMAF, reaches 98.88%.