 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging VLM and KMP: Enabling Fine-grained robotic manipulation via Semantic Keypoints Representation
Mar 04, 2025
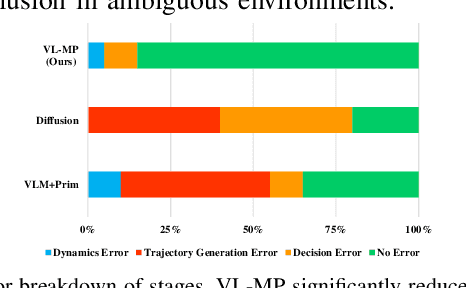
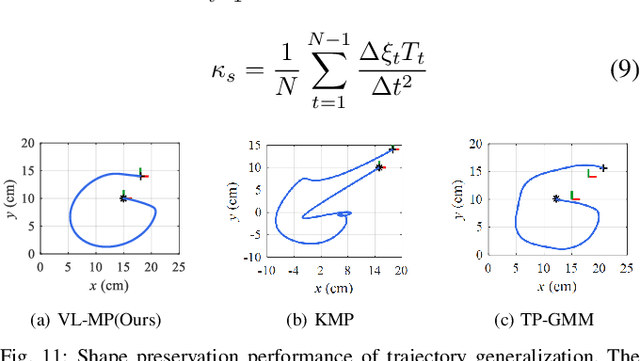
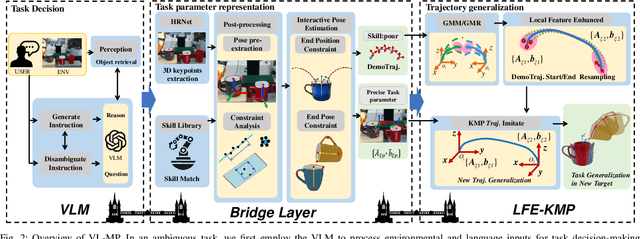
From early Movement Primitive (MP) techniques to modern Vision-Language Models (VLMs), autonomous manipulation has remained a pivotal topic in robotics. As two extremes, VLM-based methods emphasize zero-shot and adaptive manipulation but struggle with fine-grained planning. In contrast, MP-based approaches excel in precise trajectory generalization but lack decision-making ability. To leverage the strengths of the two frameworks, we propose VL-MP, which integrates VLM with Kernelized Movement Primitives (KMP) via a low-distortion decision information transfer bridge, enabling fine-grained robotic manipulation under ambiguous situations. One key of VL-MP is the accurate representation of task decision parameters through semantic keypoints constraints, leading to more precise task parameter generation. Additionally, we introduce a local trajectory feature-enhanced KMP to support VL-MP, thereby achieving shape preservation for complex trajectories. Extensive experiments conducted in complex real-world environments validate the effectiveness of VL-MP for adaptive and fine-grained manipulation.
F-Bench: Rethinking Human Preference Evaluation Metrics for Benchmarking Face Generation, Customization, and Restoration
Dec 17, 2024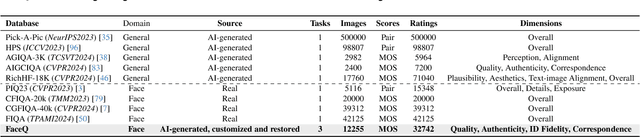



Artificial intelligence generative models exhibit remarkable capabilities in content creation, particularly in face image generation, customization, and restoration. However, current AI-generated faces (AIGFs) often fall short of human preferences due to unique distortions, unrealistic details, and unexpected identity shifts, underscoring the need for a comprehensive quality evaluation framework for AIGFs. To address this need, we introduce FaceQ, a large-scale, comprehensive database of AI-generated Face images with fine-grained Quality annotations reflecting human preferences. The FaceQ database comprises 12,255 images generated by 29 models across three tasks: (1) face generation, (2) face customization, and (3) face restoration. It includes 32,742 mean opinion scores (MOSs) from 180 annotators, assessed across multiple dimensions: quality, authenticity, identity (ID) fidelity, and text-image correspondence. Using the FaceQ database, we establish F-Bench, a benchmark for comparing and evaluating face generation, customization, and restoration models, highlighting strengths and weaknesses across various prompts and evaluation dimensions. Additionally, we assess the performance of existing image quality assessment (IQA), face quality assessment (FQA), AI-generated content image quality assessment (AIGCIQA), and preference evaluation metrics, manifesting that these standard metrics are relatively ineffective in evaluating authenticity, ID fidelity, and text-image correspondence. The FaceQ database will be publicly available upon publication.