 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware Prototype Learning with Variational Inference for Few-shot Point Cloud Segmentation
Mar 20, 2026Few-shot 3D semantic segmentation aims to generate accurate semantic masks for query point clouds with only a few annotated support examples. Existing prototype-based methods typically construct compact and deterministic prototypes from the support set to guide query segmentation. However, such rigid representations are unable to capture the intrinsic uncertainty introduced by scarce supervision, which often results in degraded robustness and limited generalization. In this work, we propose UPL (Uncertainty-aware Prototype Learning), a probabilistic approach designed to incorporate uncertainty modeling into prototype learning for few-shot 3D segmentation. Our framework introduces two key components. First, UPL introduces a dual-stream prototype refinement module that enriches prototype representations by jointly leveraging limited information from both support and query samples. Second, we formulate prototype learning as a variational inference problem, regarding class prototypes as latent variables. This probabilistic formulation enables explicit uncertainty modeling, providing robust and interpretable mask predictions. Extensive experiments on the widely used ScanNet and S3DIS benchmarks show that our UPL achieves consistent state-of-the-art performance under different settings while providing reliable uncertainty estimation. The code is available at https://fdueblab-upl.github.io/.
Learning Hierarchical Orthogonal Prototypes for Generalized Few-Shot 3D Point Cloud Segmentation
Mar 20, 2026Generalized few-shot 3D point cloud segmentation aims to adapt to novel classes from only a few annotations while maintaining strong performance on base classes, but this remains challenging due to the inherent stability-plasticity trade-off: adapting to novel classes can interfere with shared representations and cause base-class forgetting. We present HOP3D, a unified framework that learns hierarchical orthogonal prototypes with an entropy-based few-shot regularizer to enable robust novel-class adaptation without degrading base-class performance. HOP3D introduces hierarchical orthogonalization that decouples base and novel learning at both the gradient and representation levels, effectively mitigating base-novel interference. To further enhance adaptation under sparse supervision, we incorporate an entropy-based regularizer that leverages predictive uncertainty to refine prototype learning and promote balanced predictions. Extensive experiments on ScanNet200 and ScanNet++ demonstrate that HOP3D consistently outperforms state-of-the-art baselines under both 1-shot and 5-shot settings. The code is available at https://fdueblab-hop3d.github.io/.
Dual-Horizon Hybrid Internal Model for Low-Gravity Quadrupedal Jumping with Hardware-in-the-Loop Validation
Mar 09, 2026Locomotion under reduced gravity is commonly realized through jumping, yet continuous pronking in lunar gravity remains challenging due to prolonged flight phases and sparse ground contact. The extended aerial duration increases landing impact sensitivity and makes stable attitude regulation over rough planetary terrain difficult. Existing approaches primarily address single jumps on flat surfaces and lack both continuous-terrain solutions and realistic hardware validation. This work presents a Dual-Horizon Hybrid Internal Model for continuous quadrupedal jumping under lunar gravity using proprioceptive sensing only. Two temporal encoders capture complementary time scales: a short-horizon branch models rapid vertical dynamics with explicit vertical velocity estimation, while a long-horizon branch models horizontal motion trends and center-of-mass height evolution across the jump cycle. The fused representation enables stable and continuous jumping under extended aerial phases characteristic of lunar gravity. To provide hardware-in-the-loop validation, we develop the MATRIX (Mixed-reality Adaptive Testbed for Robotic Integrated eXploration) platform, a digital-twin-driven system that offloads gravity through a pulley-counterweight mechanism and maps Unreal Engine lunar terrain to a motion platform and treadmill in real time. Using MATRIX, we demonstrate continuous jumping of a quadruped robot under lunar-gravity emulation across cratered lunar-like terrain.
Morphogenetic Assembly and Adaptive Control for Heterogeneous Modular Robots
Feb 11, 2026This paper presents a closed-loop automation framework for heterogeneous modular robots, covering the full pipeline from morphological construction to adaptive control. In this framework, a mobile manipulator handles heterogeneous functional modules including structural, joint, and wheeled modules to dynamically assemble diverse robot configurations and provide them with immediate locomotion capability. To address the state-space explosion in large-scale heterogeneous reconfiguration, we propose a hierarchical planner: the high-level planner uses a bidirectional heuristic search with type-penalty terms to generate module-handling sequences, while the low level planner employs A* search to compute optimal execution trajectories. This design effectively decouples discrete configuration planning from continuous motion execution. For adaptive motion generation of unknown assembled configurations, we introduce a GPU accelerated Annealing-Variance Model Predictive Path Integral (MPPI) controller. By incorporating a multi stage variance annealing strategy to balance global exploration and local convergence, the controller enables configuration-agnostic, real-time motion control. Large scale simulations show that the type-penalty term is critical for planning robustness in heterogeneous scenarios. Moreover, the greedy heuristic produces plans with lower physical execution costs than the Hungarian heuristic. The proposed annealing-variance MPPI significantly outperforms standard MPPI in both velocity tracking accuracy and control frequency, achieving real time control at 50 Hz. The framework validates the full-cycle process, including module assembly, robot merging and splitting, and dynamic motion generation.
Distribution Preference Optimization: A Fine-grained Perspective for LLM Unlearning
Oct 06, 2025As Large Language Models (LLMs) demonstrate remarkable capabilities learned from vast corpora, concerns regarding data privacy and safety are receiving increasing attention. LLM unlearning, which aims to remove the influence of specific data while preserving overall model utility, is becoming an important research area. One of the mainstream unlearning classes is optimization-based methods, which achieve forgetting directly through fine-tuning, exemplified by Negative Preference Optimization (NPO). However, NPO's effectiveness is limited by its inherent lack of explicit positive preference signals. Attempts to introduce such signals by constructing preferred responses often necessitate domain-specific knowledge or well-designed prompts, fundamentally restricting their generalizability. In this paper, we shift the focus to the distribution-level, directly targeting the next-token probability distribution instead of entire responses, and derive a novel unlearning algorithm termed \textbf{Di}stribution \textbf{P}reference \textbf{O}ptimization (DiPO). We show that the requisite preference distribution pairs for DiPO, which are distributions over the model's output tokens, can be constructed by selectively amplifying or suppressing the model's high-confidence output logits, thereby effectively overcoming NPO's limitations. We theoretically prove the consistency of DiPO's loss function with the desired unlearning direction. Extensive experiments demonstrate that DiPO achieves a strong trade-off between model utility and forget quality. Notably, DiPO attains the highest forget quality on the TOFU benchmark, and maintains leading scalability and sustainability in utility preservation on the MUSE benchmark.
Lifelong Safety Alignment for Language Models
May 26, 2025



LLMs have made impressive progress, but their growing capabilities also expose them to highly flexible jailbreaking attacks designed to bypass safety alignment. While many existing defenses focus on known types of attacks, it is more critical to prepare LLMs for unseen attacks that may arise during deployment. To address this, we propose a lifelong safety alignment framework that enables LLMs to continuously adapt to new and evolving jailbreaking strategies. Our framework introduces a competitive setup between two components: a Meta-Attacker, trained to actively discover novel jailbreaking strategies, and a Defender, trained to resist them. To effectively warm up the Meta-Attacker, we first leverage the GPT-4o API to extract key insights from a large collection of jailbreak-related research papers. Through iterative training, the first iteration Meta-Attacker achieves a 73% attack success rate (ASR) on RR and a 57% transfer ASR on LAT using only single-turn attacks. Meanwhile, the Defender progressively improves its robustness and ultimately reduces the Meta-Attacker's success rate to just 7%, enabling safer and more reliable deployment of LLMs in open-ended environments. The code is available at https://github.com/sail-sg/LifelongSafetyAlignment.
Reinforcement Fine-Tuning Powers Reasoning Capability of Multimodal Large Language Models
May 24, 2025Standing in 2025, at a critical juncture in the pursuit of Artificial General Intelligence (AGI), reinforcement fine-tuning (RFT) has demonstrated significant potential in enhancing the reasoning capability of large language models (LLMs) and has led to the development of cutting-edge AI models such as OpenAI-o1 and DeepSeek-R1. Moreover, the efficient application of RFT to enhance the reasoning capability of multimodal large language models (MLLMs) has attracted widespread attention from the community. In this position paper, we argue that reinforcement fine-tuning powers the reasoning capability of multimodal large language models. To begin with, we provide a detailed introduction to the fundamental background knowledge that researchers interested in this field should be familiar with. Furthermore, we meticulously summarize the improvements of RFT in powering reasoning capability of MLLMs into five key points: diverse modalities, diverse tasks and domains, better training algorithms, abundant benchmarks and thriving engineering frameworks. Finally, we propose five promising directions for future research that the community might consider. We hope that this position paper will provide valuable insights to the community at this pivotal stage in the advancement toward AGI. Summary of works done on RFT for MLLMs is available at https://github.com/Sun-Haoyuan23/Awesome-RL-based-Reasoning-MLLMs.
PSDiffusion: Harmonized Multi-Layer Image Generation via Layout and Appearance Alignment
May 16, 2025



Diffusion models have made remarkable advancements in generating high-quality images from textual descriptions. Recent works like LayerDiffuse have extended the previous single-layer, unified image generation paradigm to transparent image layer generation. However, existing multi-layer generation methods fail to handle the interactions among multiple layers such as rational global layout, physics-plausible contacts and visual effects like shadows and reflections while maintaining high alpha quality. To solve this problem, we propose PSDiffusion, a unified diffusion framework for simultaneous multi-layer text-to-image generation. Our model can automatically generate multi-layer images with one RGB background and multiple RGBA foregrounds through a single feed-forward process. Unlike existing methods that combine multiple tools for post-decomposition or generate layers sequentially and separately, our method introduces a global-layer interactive mechanism that generates layered-images concurrently and collaboratively, ensuring not only high quality and completeness for each layer, but also spatial and visual interactions among layers for global coherence.
LPGen: Enhancing High-Fidelity Landscape Painting Generation through Diffusion Model
Jul 25, 2024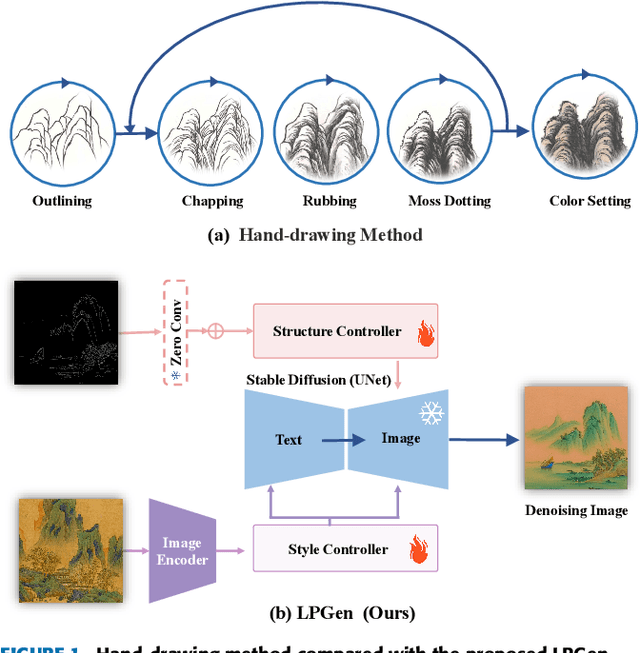

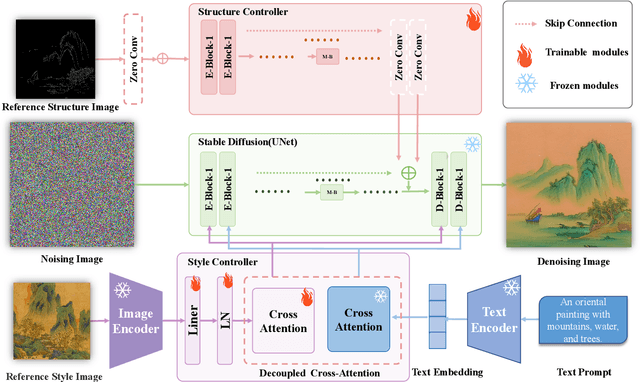
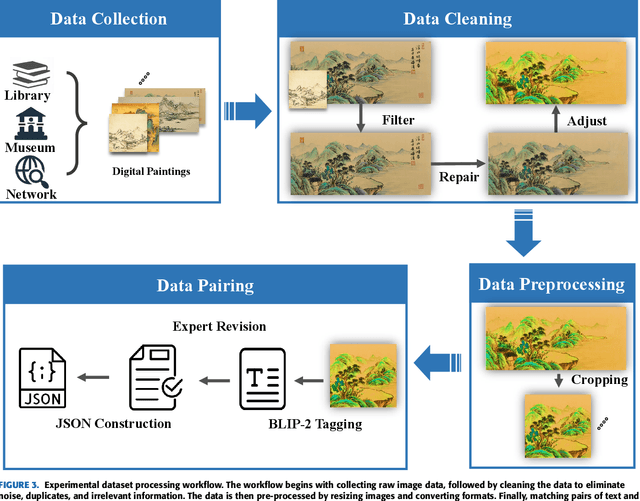
Generating landscape paintings expands the possibilities of artistic creativity and imagination. Traditional landscape painting methods involve using ink or colored ink on rice paper, which requires substantial time and effort. These methods are susceptible to errors and inconsistencies and lack precise control over lines and colors. This paper presents LPGen, a high-fidelity, controllable model for landscape painting generation, introducing a novel multi-modal framework that integrates image prompts into the diffusion model. We extract its edges and contours by computing canny edges from the target landscape image. These, along with natural language text prompts and drawing style references, are fed into the latent diffusion model as conditions. We implement a decoupled cross-attention strategy to ensure compatibility between image and text prompts, facilitating multi-modal image generation. A decoder generates the final image. Quantitative and qualitative analyses demonstrate that our method outperforms existing approaches in landscape painting generation and exceeds the current state-of-the-art. The LPGen network effectively controls the composition and color of landscape paintings, generates more accurate images, and supports further research in deep learning-based landscape painting generation.
OAKINK2: A Dataset of Bimanual Hands-Object Manipulation in Complex Task Completion
Mar 28, 2024



We present OAKINK2, a dataset of bimanual object manipulation tasks for complex daily activities. In pursuit of constructing the complex tasks into a structured representation, OAKINK2 introduces three level of abstraction to organize the manipulation tasks: Affordance, Primitive Task, and Complex Task. OAKINK2 features on an object-centric perspective for decoding the complex tasks, treating them as a sequence of object affordance fulfillment. The first level, Affordance, outlines the functionalities that objects in the scene can afford, the second level, Primitive Task, describes the minimal interaction units that humans interact with the object to achieve its affordance, and the third level, Complex Task, illustrates how Primitive Tasks are composed and interdependent. OAKINK2 dataset provides multi-view image streams and precise pose annotations for the human body, hands and various interacting objects. This extensive collection supports applications such as interaction reconstruction and motion synthesis. Based on the 3-level abstraction of OAKINK2, we explore a task-oriented framework for Complex Task Completion (CTC). CTC aims to generate a sequence of bimanual manipulation to achieve task objectives. Within the CTC framework, we employ Large Language Models (LLMs) to decompose the complex task objectives into sequences of Primitive Tasks and have developed a Motion Fulfillment Model that generates bimanual hand motion for each Primitive Task. OAKINK2 datasets and models are available at https://oakink.net/v2.