 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^2$: Dual-Memory Augmentation for Long-Horizon Web Agents via Trajectory Summarization and Insight Retrieval
Feb 28, 2026Multimodal Large Language Models (MLLMs) based agents have demonstrated remarkable potential in autonomous web navigation. However, handling long-horizon tasks remains a critical bottleneck. Prevailing strategies often rely heavily on extensive data collection and model training, yet still struggle with high computational costs and insufficient reasoning capabilities when facing complex, long-horizon scenarios. To address this, we propose M$^2$, a training-free, memory-augmented framework designed to optimize context efficiency and decision-making robustness. Our approach incorporates a dual-tier memory mechanism that synergizes Dynamic Trajectory Summarization (Internal Memory) to compress verbose interaction history into concise state updates, and Insight Retrieval Augmentation (External Memory) to guide the agent with actionable guidelines retrieved from an offline insight bank. Extensive evaluations across WebVoyager and OnlineMind2Web demonstrate that M$^2$ consistently surpasses baselines, yielding up to a 19.6% success rate increase and 58.7% token reduction for Qwen3-VL-32B, while proprietary models like Claude achieve accuracy gains up to 12.5% alongside significantly lower computational overhead.
Building Autonomous GUI Navigation via Agentic-Q Estimation and Step-Wise Policy Optimization
Feb 14, 2026Recent advances in Multimodal Large Language Models (MLLMs) have substantially driven the progress of autonomous agents for Graphical User Interface (GUI). Nevertheless, in real-world applications, GUI agents are often faced with non-stationary environments, leading to high computational costs for data curation and policy optimization. In this report, we introduce a novel MLLM-centered framework for GUI agents, which consists of two components: agentic-Q estimation and step-wise policy optimization. The former one aims to optimize a Q-model that can generate step-wise values to evaluate the contribution of a given action to task completion. The latter one takes step-wise samples from the state-action trajectory as inputs, and optimizes the policy via reinforcement learning with our agentic-Q model. It should be noticed that (i) all state-action trajectories are produced by the policy itself, so that the data collection costs are manageable; (ii) the policy update is decoupled from the environment, ensuring stable and efficient optimization. Empirical evaluations show that our framework endows Ovis2.5-9B with powerful GUI interaction capabilities, achieving remarkable performances on GUI navigation and grounding benchmarks and even surpassing contenders with larger scales.
Optimal Transport-Based Token Weighting scheme for Enhanced Preference Optimization
May 24, 2025Direct Preference Optimization (DPO) has emerged as a promising framework for aligning Large Language Models (LLMs) with human preferences by directly optimizing the log-likelihood difference between chosen and rejected responses. However, existing methods assign equal importance to all tokens in the response, while humans focus on more meaningful parts. This leads to suboptimal preference optimization, as irrelevant or noisy tokens disproportionately influence DPO loss. To address this limitation, we propose \textbf{O}ptimal \textbf{T}ransport-based token weighting scheme for enhancing direct \textbf{P}reference \textbf{O}ptimization (OTPO). By emphasizing semantically meaningful token pairs and de-emphasizing less relevant ones, our method introduces a context-aware token weighting scheme that yields a more contrastive reward difference estimate. This adaptive weighting enhances reward stability, improves interpretability, and ensures that preference optimization focuses on meaningful differences between responses. Extensive experiments have validated OTPO's effectiveness in improving instruction-following ability across various settings\footnote{Code is available at https://github.com/Mimasss2/OTPO.}.
Establishing Reliability Metrics for Reward Models in Large Language Models
Apr 21, 2025The reward model (RM) that represents human preferences plays a crucial role in optimizing the outputs of large language models (LLMs), e.g., through reinforcement learning from human feedback (RLHF) or rejection sampling. However, a long challenge for RM is its uncertain reliability, i.e., LLM outputs with higher rewards may not align with actual human preferences. Currently, there is a lack of a convincing metric to quantify the reliability of RMs. To bridge this gap, we propose the \textit{\underline{R}eliable at \underline{$\eta$}} (RETA) metric, which directly measures the reliability of an RM by evaluating the average quality (scored by an oracle) of the top $\eta$ quantile responses assessed by an RM. On top of RETA, we present an integrated benchmarking pipeline that allows anyone to evaluate their own RM without incurring additional Oracle labeling costs. Extensive experimental studies demonstrate the superior stability of RETA metric, providing solid evaluations of the reliability of various publicly available and proprietary RMs. When dealing with an unreliable RM, we can use the RETA metric to identify the optimal quantile from which to select the responses.
Recurrent Temporal Revision Graph Networks
Sep 26, 2023Temporal graphs offer more accurate modeling of many real-world scenarios than static graphs. However, neighbor aggregation, a critical building block of graph networks, for temporal graphs, is currently straightforwardly extended from that of static graphs. It can be computationally expensive when involving all historical neighbors during such aggregation. In practice, typically only a subset of the most recent neighbors are involved. However, such subsampling leads to incomplete and biased neighbor information. To address this limitation, we propose a novel framework for temporal neighbor aggregation that uses the recurrent neural network with node-wise hidden states to integrate information from all historical neighbors for each node to acquire the complete neighbor information. We demonstrate the superior theoretical expressiveness of the proposed framework as well as its state-of-the-art performance in real-world applications. Notably, it achieves a significant +9.6% improvement on averaged precision in a real-world Ecommerce dataset over existing methods on 2-layer models.
Clustered Embedding Learning for Recommender Systems
Feb 10, 2023In recent years, recommender systems have advanced rapidly, where embedding learning for users and items plays a critical role. A standard method learns a unique embedding vector for each user and item. However, such a method has two important limitations in real-world applications: 1) it is hard to learn embeddings that generalize well for users and items with rare interactions on their own; and 2) it may incur unbearably high memory costs when the number of users and items scales up. Existing approaches either can only address one of the limitations or have flawed overall performances. In this paper, we propose Clustered Embedding Learning (CEL) as an integrated solution to these two problems. CEL is a plug-and-play embedding learning framework that can be combined with any differentiable feature interaction model. It is capable of achieving improved performance, especially for cold users and items, with reduced memory cost. CEL enables automatic and dynamic clustering of users and items in a top-down fashion, where clustered entities jointly learn a shared embedding. The accelerated version of CEL has an optimal time complexity, which supports efficient online updates. Theoretically, we prove the identifiability and the existence of a unique optimal number of clusters for CEL in the context of nonnegative matrix factorization. Empirically, we validate the effectiveness of CEL on three public datasets and one business dataset, showing its consistently superior performance against current state-of-the-art methods. In particular, when incorporating CEL into the business model, it brings an improvement of $+0.6\%$ in AUC, which translates into a significant revenue gain; meanwhile, the size of the embedding table gets $2650$ times smaller.
Exploit Customer Life-time Value with Memoryless Experiments
Jan 17, 2022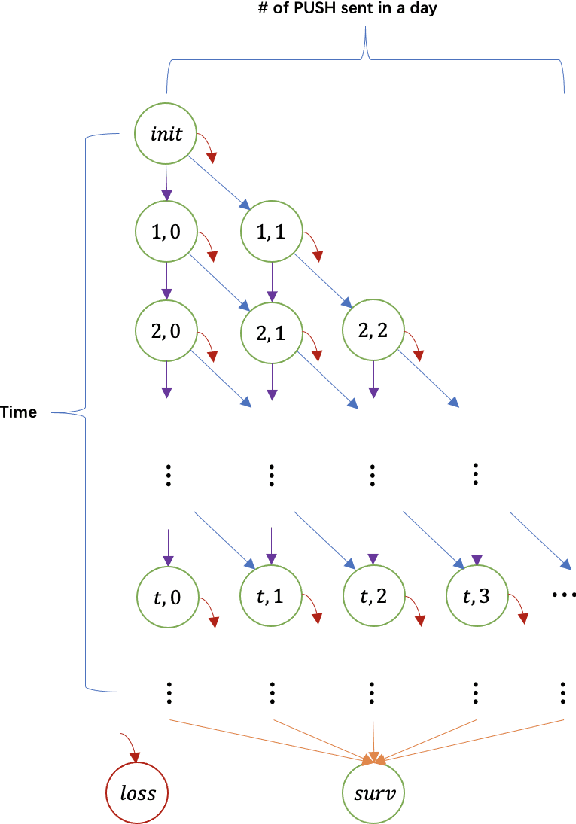
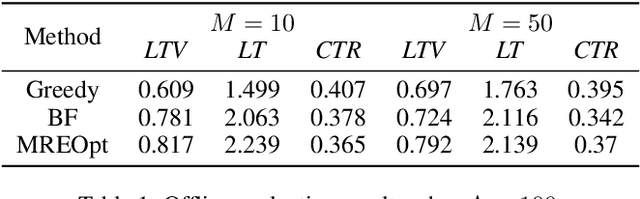
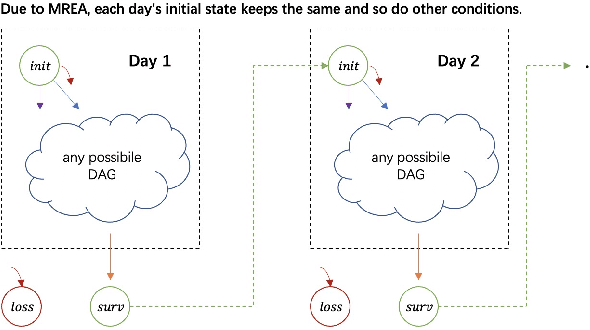

As a measure of the long-term contribution produced by customers in a service or product relationship, life-time value, or LTV, can more comprehensively find the optimal strategy for service delivery. However, it is challenging to accurately abstract the LTV scene, model it reasonably, and find the optimal solution. The current theories either cannot precisely express LTV because of the single modeling structure, or there is no efficient solution. We propose a general LTV modeling method, which solves the problem that customers' long-term contribution is difficult to quantify while existing methods, such as modeling the click-through rate, only pursue the short-term contribution. At the same time, we also propose a fast dynamic programming solution based on a mutated bisection method and the memoryless repeated experiments assumption. The model and method can be applied to different service scenarios, such as the recommendation system. Experiments on real-world datasets confirm the effectiveness of the proposed model and optimization method. In addition, this whole LTV structure was deployed at a large E-commerce mobile phone application, where it managed to select optimal push message sending time and achieved a 10\% LTV improvement.
A General Traffic Shaping Protocol in E-Commerce
Dec 30, 2021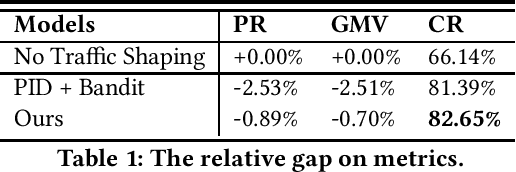
To approach different business objectives, online traffic shaping algorithms aim at improving exposures of a target set of items, such as boosting the growth of new commodities. Generally, these algorithms assume that the utility of each user-item pair can be accessed via a well-trained conversion rate prediction model. However, for real E-Commerce platforms, there are unavoidable factors preventing us from learning such an accurate model. In order to break the heavy dependence on accurate inputs of the utility, we propose a general online traffic shaping protocol for online E-Commerce applications. In our framework, we approximate the function mapping the bonus scores, which generally are the only method to influence the ranking result in the traffic shaping problem, to the numbers of exposures and purchases. Concretely, we approximate the above function by a class of the piece-wise linear function constructed on the convex hull of the explored data points. Moreover, we reformulate the online traffic shaping problem as linear programming where these piece-wise linear functions are embedded into both the objective and constraints. Our algorithm can straightforwardly optimize the linear programming in the prime space, and its solution can be simply applied by a stochastic strategy to fulfill the optimized objective and the constraints in expectation. Finally, the online A/B test shows our proposed algorithm steadily outperforms the previous industrial level traffic shaping algorithm.
Re-ranking With Constraints on Diversified Exposures for Homepage Recommender System
Dec 12, 2021
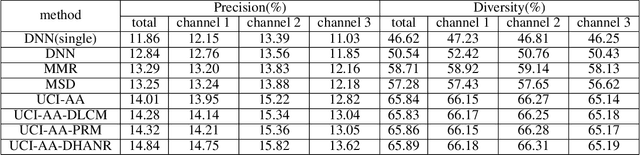
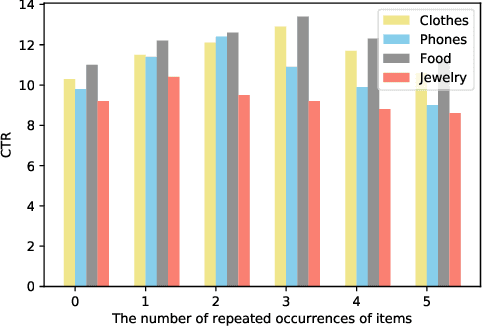
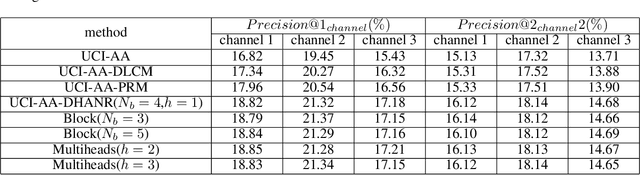
The homepage recommendation on most E-commerce applications places items in a hierarchical manner, where different channels display items in different styles. Existing algorithms usually optimize the performance of a single channel. So designing the model to achieve the optimal recommendation list which maximize the Click-Through Rate (CTR) of whole homepage is a challenge problem. Other than the accuracy objective, display diversity on the homepage is also important since homogeneous display usually hurts user experience. In this paper, we propose a two-stage architecture of the homepage recommendation system. In the first stage, we develop efficient algorithms for recommending items to proper channels while maintaining diversity. The two methods can be combined: user-channel-item predictive model with diversity constraint. In the second stage, we provide an ordered list of items in each channel. Existing re-ranking models are hard to describe the mutual influence between items in both intra-channel and inter-channel. Therefore, we propose a Deep \& Hierarchical Attention Network Re-ranking (DHANR) model for homepage recommender systems. The Hierarchical Attention Network consists of an item encoder, an item-level attention layer, a channel encoder and a channel-level attention layer. Our method achieves a significant improvement in terms of precision, intra-list average distance(ILAD) and channel-wise Precision@k in offline experiments and in terms of CTR and ILAD in our online systems.
Learning-To-Ensemble by Contextual Rank Aggregation in E-Commerce
Aug 10, 2021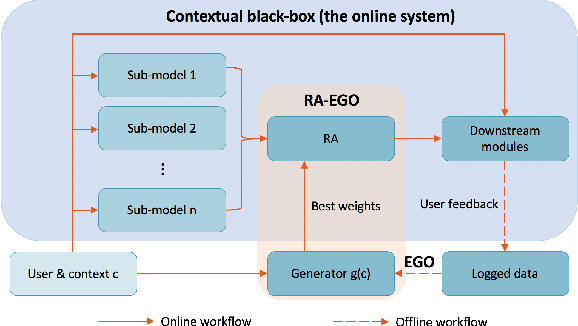
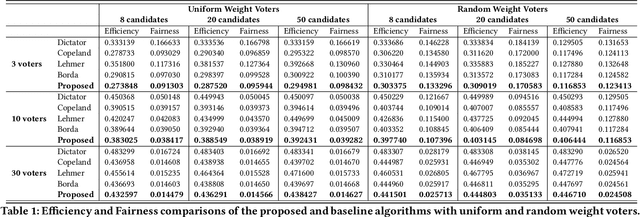
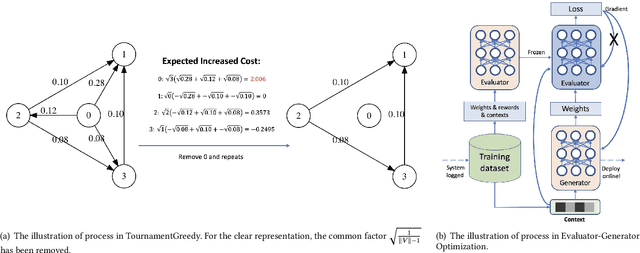

Ensemble models in E-commerce combine predictions from multiple sub-models for ranking and revenue improvement. Industrial ensemble models are typically deep neural networks, following the supervised learning paradigm to infer conversion rate given inputs from sub-models. However, this process has the following two problems. Firstly, the point-wise scoring approach disregards the relationships between items and leads to homogeneous displayed results, while diversified display benefits user experience and revenue. Secondly, the learning paradigm focuses on the ranking metrics and does not directly optimize the revenue. In our work, we propose a new Learning-To-Ensemble (LTE) framework RAEGO, which replaces the ensemble model with a contextual Rank Aggregator (RA) and explores the best weights of sub-models by the Evaluator-Generator Optimization (EGO). To achieve the best online performance, we propose a new rank aggregation algorithm TournamentGreedy as a refinement of classic rank aggregators, which also produces the best average weighted Kendall Tau Distance (KTD) amongst all the considered algorithms with quadratic time complexity. Under the assumption that the best output list should be Pareto Optimal on the KTD metric for sub-models, we show that our RA algorithm has higher efficiency and coverage in exploring the optimal weights. Combined with the idea of Bayesian Optimization and gradient descent, we solve the online contextual Black-Box Optimization task that finds the optimal weights for sub-models given a chosen RA model. RA-EGO has been deployed in our online system and has improved the revenue significantly.