 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing Reliability Metrics for Reward Models in Large Language Models
Apr 21, 2025The reward model (RM) that represents human preferences plays a crucial role in optimizing the outputs of large language models (LLMs), e.g., through reinforcement learning from human feedback (RLHF) or rejection sampling. However, a long challenge for RM is its uncertain reliability, i.e., LLM outputs with higher rewards may not align with actual human preferences. Currently, there is a lack of a convincing metric to quantify the reliability of RMs. To bridge this gap, we propose the \textit{\underline{R}eliable at \underline{$\eta$}} (RETA) metric, which directly measures the reliability of an RM by evaluating the average quality (scored by an oracle) of the top $\eta$ quantile responses assessed by an RM. On top of RETA, we present an integrated benchmarking pipeline that allows anyone to evaluate their own RM without incurring additional Oracle labeling costs. Extensive experimental studies demonstrate the superior stability of RETA metric, providing solid evaluations of the reliability of various publicly available and proprietary RMs. When dealing with an unreliable RM, we can use the RETA metric to identify the optimal quantile from which to select the responses.
Learning-To-Ensemble by Contextual Rank Aggregation in E-Commerce
Aug 10, 2021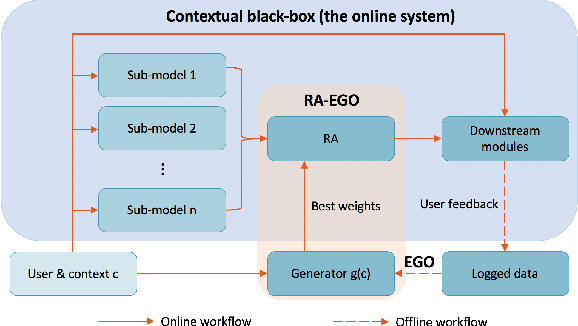
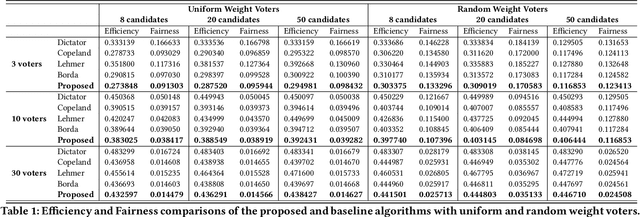
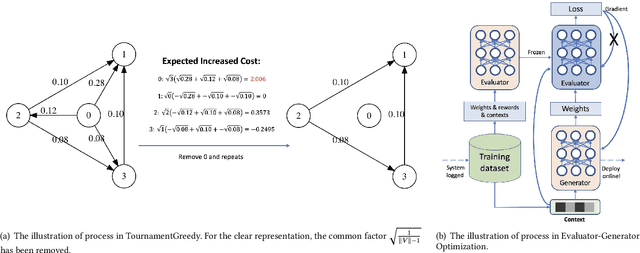

Ensemble models in E-commerce combine predictions from multiple sub-models for ranking and revenue improvement. Industrial ensemble models are typically deep neural networks, following the supervised learning paradigm to infer conversion rate given inputs from sub-models. However, this process has the following two problems. Firstly, the point-wise scoring approach disregards the relationships between items and leads to homogeneous displayed results, while diversified display benefits user experience and revenue. Secondly, the learning paradigm focuses on the ranking metrics and does not directly optimize the revenue. In our work, we propose a new Learning-To-Ensemble (LTE) framework RAEGO, which replaces the ensemble model with a contextual Rank Aggregator (RA) and explores the best weights of sub-models by the Evaluator-Generator Optimization (EGO). To achieve the best online performance, we propose a new rank aggregation algorithm TournamentGreedy as a refinement of classic rank aggregators, which also produces the best average weighted Kendall Tau Distance (KTD) amongst all the considered algorithms with quadratic time complexity. Under the assumption that the best output list should be Pareto Optimal on the KTD metric for sub-models, we show that our RA algorithm has higher efficiency and coverage in exploring the optimal weights. Combined with the idea of Bayesian Optimization and gradient descent, we solve the online contextual Black-Box Optimization task that finds the optimal weights for sub-models given a chosen RA model. RA-EGO has been deployed in our online system and has improved the revenue significantly.