 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompass-Thinker-7B Technical Report
Aug 12, 2025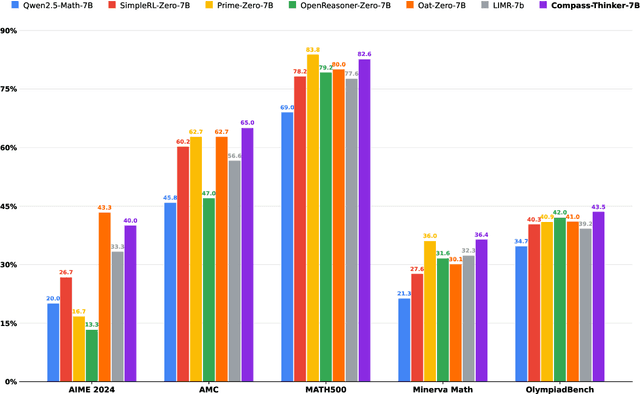

Recent R1-Zero-like research further demonstrates that reasoning extension has given large language models (LLMs) unprecedented reasoning capabilities, and Reinforcement Learning is the core technology to elicit its complex reasoning. However, conducting RL experiments directly on hyperscale models involves high computational costs and resource demands, posing significant risks. We propose the Compass-Thinker-7B model, which aims to explore the potential of Reinforcement Learning with less computational resources and costs, and provides insights for further research into RL recipes for larger models. Compass-Thinker-7B is trained from an open source model through a specially designed Reinforcement Learning Pipeline. we curate a dataset of 30k verifiable mathematics problems for the Reinforcement Learning Pipeline. By configuring data and training settings with different difficulty distributions for different stages, the potential of the model is gradually released and the training efficiency is improved. Extensive evaluations show that Compass-Thinker-7B possesses exceptional reasoning potential, and achieves superior performance on mathematics compared to the same-sized RL model.Especially in the challenging AIME2024 evaluation, Compass-Thinker-7B achieves 40% accuracy.
dots.llm1 Technical Report
Jun 06, 2025Mixture of Experts (MoE) models have emerged as a promising paradigm for scaling language models efficiently by activating only a subset of parameters for each input token. In this report, we present dots.llm1, a large-scale MoE model that activates 14B parameters out of a total of 142B parameters, delivering performance on par with state-of-the-art models while reducing training and inference costs. Leveraging our meticulously crafted and efficient data processing pipeline, dots.llm1 achieves performance comparable to Qwen2.5-72B after pretraining on 11.2T high-quality tokens and post-training to fully unlock its capabilities. Notably, no synthetic data is used during pretraining. To foster further research, we open-source intermediate training checkpoints at every one trillion tokens, providing valuable insights into the learning dynamics of large language models.
Establishing Reliability Metrics for Reward Models in Large Language Models
Apr 21, 2025The reward model (RM) that represents human preferences plays a crucial role in optimizing the outputs of large language models (LLMs), e.g., through reinforcement learning from human feedback (RLHF) or rejection sampling. However, a long challenge for RM is its uncertain reliability, i.e., LLM outputs with higher rewards may not align with actual human preferences. Currently, there is a lack of a convincing metric to quantify the reliability of RMs. To bridge this gap, we propose the \textit{\underline{R}eliable at \underline{$\eta$}} (RETA) metric, which directly measures the reliability of an RM by evaluating the average quality (scored by an oracle) of the top $\eta$ quantile responses assessed by an RM. On top of RETA, we present an integrated benchmarking pipeline that allows anyone to evaluate their own RM without incurring additional Oracle labeling costs. Extensive experimental studies demonstrate the superior stability of RETA metric, providing solid evaluations of the reliability of various publicly available and proprietary RMs. When dealing with an unreliable RM, we can use the RETA metric to identify the optimal quantile from which to select the responses.
Imitate TheWorld: A Search Engine Simulation Platform
Aug 10, 2021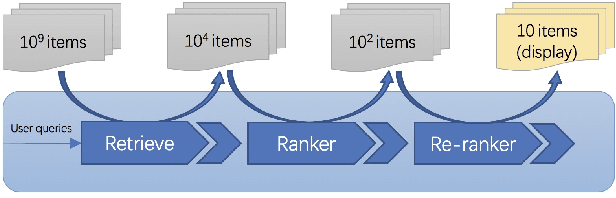
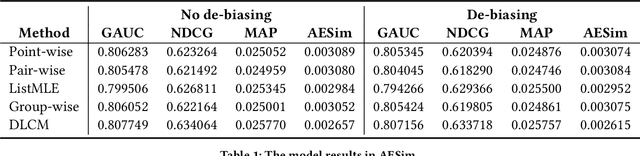
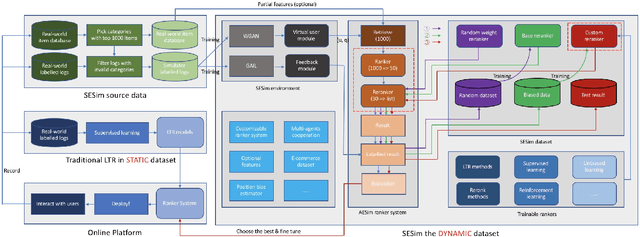

Recent E-commerce applications benefit from the growth of deep learning techniques. However, we notice that many works attempt to maximize business objectives by closely matching offline labels which follow the supervised learning paradigm. This results in models obtain high offline performance in terms of Area Under Curve (AUC) and Normalized Discounted Cumulative Gain (NDCG), but cannot consistently increase the revenue metrics such as purchases amount of users. Towards the issues, we build a simulated search engine AESim that can properly give feedback by a well-trained discriminator for generated pages, as a dynamic dataset. Different from previous simulation platforms which lose connection with the real world, ours depends on the real data in AliExpress Search: we use adversarial learning to generate virtual users and use Generative Adversarial Imitation Learning (GAIL) to capture behavior patterns of users. Our experiments also show AESim can better reflect the online performance of ranking models than classic ranking metrics, implying AESim can play a surrogate of AliExpress Search and evaluate models without going online.
On-Demand and Lightweight Knowledge Graph Generation -- a Demonstration with DBpedia
Jul 02, 2021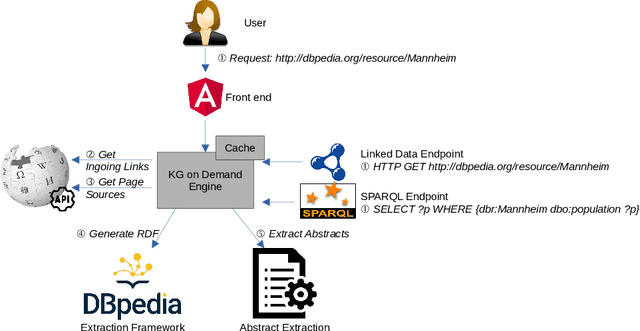

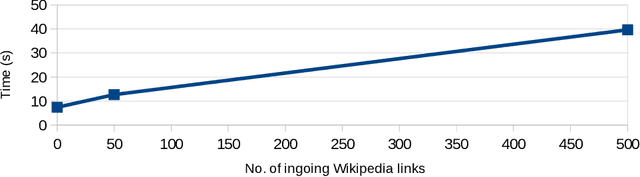
Modern large-scale knowledge graphs, such as DBpedia, are datasets which require large computational resources to serve and process. Moreover, they often have longer release cycles, which leads to outdated information in those graphs. In this paper, we present DBpedia on Demand -- a system which serves DBpedia resources on demand without the need to materialize and store the entire graph, and which even provides limited querying functionality.