 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Attentive Memory Network for Click-through Rate Prediction with Long Sequences
Aug 08, 2022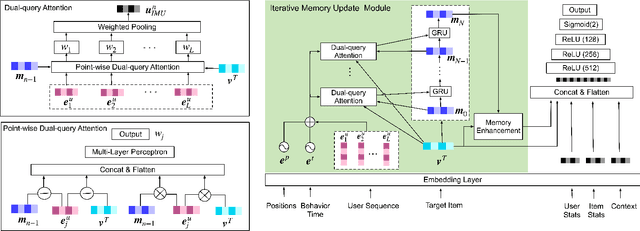
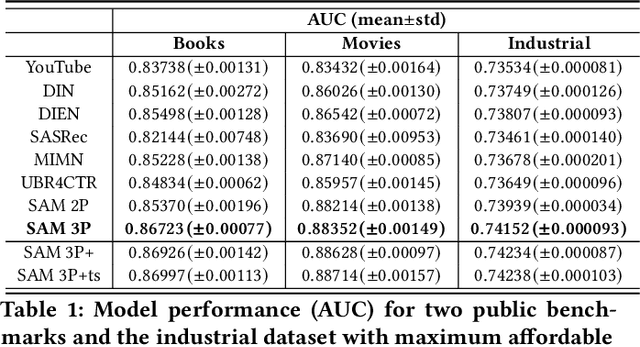
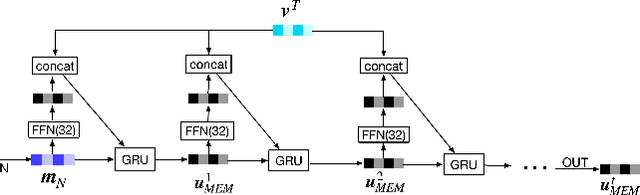
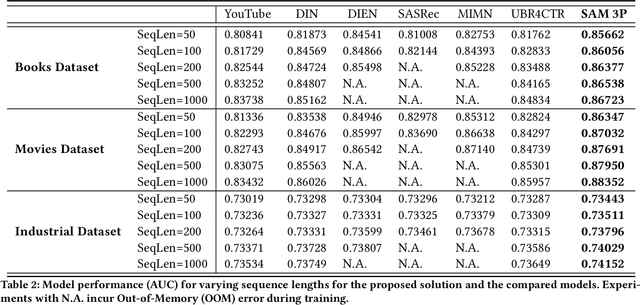
Sequential recommendation predicts users' next behaviors with their historical interactions. Recommending with longer sequences improves recommendation accuracy and increases the degree of personalization. As sequences get longer, existing works have not yet addressed the following two main challenges. Firstly, modeling long-range intra-sequence dependency is difficult with increasing sequence lengths. Secondly, it requires efficient memory and computational speeds. In this paper, we propose a Sparse Attentive Memory (SAM) network for long sequential user behavior modeling. SAM supports efficient training and real-time inference for user behavior sequences with lengths on the scale of thousands. In SAM, we model the target item as the query and the long sequence as the knowledge database, where the former continuously elicits relevant information from the latter. SAM simultaneously models target-sequence dependencies and long-range intra-sequence dependencies with O(L) complexity and O(1) number of sequential updates, which can only be achieved by the self-attention mechanism with O(L^2) complexity. Extensive empirical results demonstrate that our proposed solution is effective not only in long user behavior modeling but also on short sequences modeling. Implemented on sequences of length 1000, SAM is successfully deployed on one of the largest international E-commerce platforms. This inference time is within 30ms, with a substantial 7.30% click-through rate improvement for the online A/B test. To the best of our knowledge, it is the first end-to-end long user sequence modeling framework that models intra-sequence and target-sequence dependencies with the aforementioned degree of efficiency and successfully deployed on a large-scale real-time industrial recommender system.
Imitate TheWorld: A Search Engine Simulation Platform
Aug 10, 2021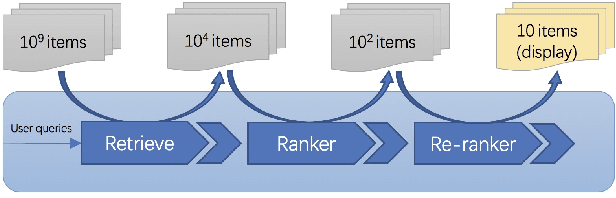
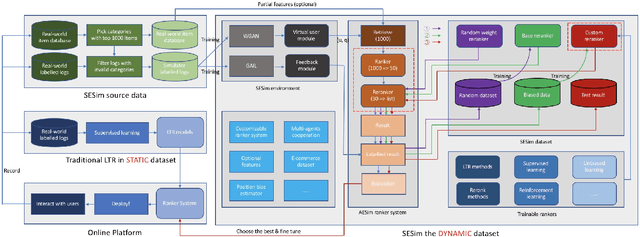

Recent E-commerce applications benefit from the growth of deep learning techniques. However, we notice that many works attempt to maximize business objectives by closely matching offline labels which follow the supervised learning paradigm. This results in models obtain high offline performance in terms of Area Under Curve (AUC) and Normalized Discounted Cumulative Gain (NDCG), but cannot consistently increase the revenue metrics such as purchases amount of users. Towards the issues, we build a simulated search engine AESim that can properly give feedback by a well-trained discriminator for generated pages, as a dynamic dataset. Different from previous simulation platforms which lose connection with the real world, ours depends on the real data in AliExpress Search: we use adversarial learning to generate virtual users and use Generative Adversarial Imitation Learning (GAIL) to capture behavior patterns of users. Our experiments also show AESim can better reflect the online performance of ranking models than classic ranking metrics, implying AESim can play a surrogate of AliExpress Search and evaluate models without going online.
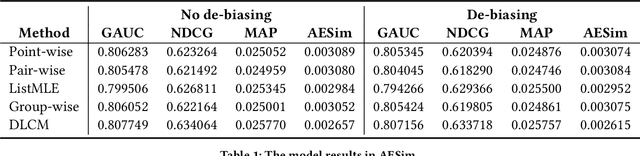
Validation Set Evaluation can be Wrong: An Evaluator-Generator Approach for Maximizing Online Performance of Ranking in E-commerce
Mar 27, 2020
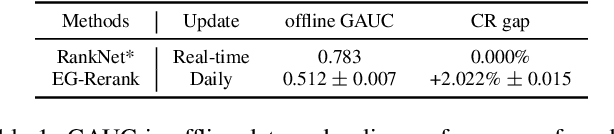
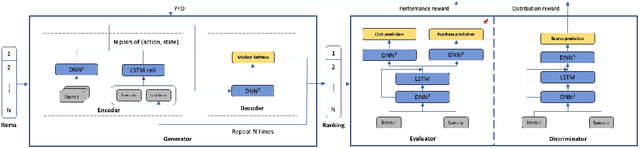
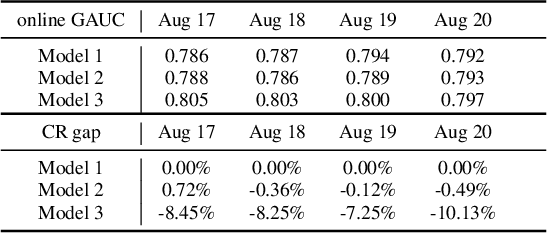
Learning-to-rank (LTR) has become a key technology in E-commerce applications. Previous LTR approaches followed the supervised learning paradigm so that learned models should match the labeled data point-wisely or pair-wisely. However, we have noticed that global context information, including the total order of items in the displayed webpage, can play an important role in interactions with the customers. Therefore, to approach the best global ordering, the exploration in a large combinatorial space of items is necessary, which requires evaluating orders that may not appear in the labeled data. In this scenario, we first show that the classical data-based metrics can be inconsistent with online performance, or even misleading. We then propose to learn an evaluator and search the best model guided by the evaluator, which forms the evaluator-generator framework for training the group-wise LTR model. The evaluator is learned from the labeled data, and is enhanced by incorporating the order context information. The generator is trained with the supervision of the evaluator by reinforcement learning to generate the best order in the combinatorial space. Our experiments in one of the world's largest retail platforms disclose that the learned evaluator is a much better indicator than classical data-based metrics. Moreover, our LTR model achieves a significant improvement ($\textgreater2\%$) from the current industrial-level pair-wise models in terms of both Conversion Rate (CR) and Gross Merchandise Volume (GMV) in online A/B tests.
Temporal-adaptive Hierarchical Reinforcement Learning
Feb 06, 2020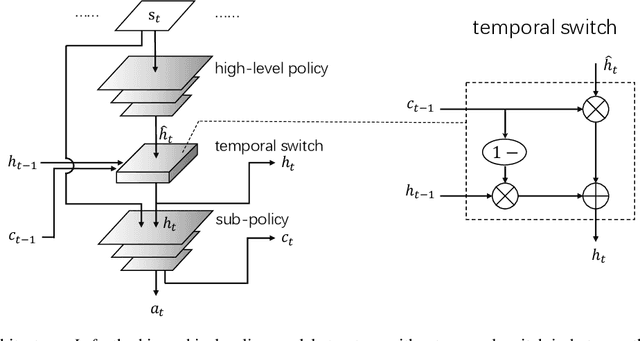
Hierarchical reinforcement learning (HRL) helps address large-scale and sparse reward issues in reinforcement learning. In HRL, the policy model has an inner representation structured in levels. With this structure, the reinforcement learning task is expected to be decomposed into corresponding levels with sub-tasks, and thus the learning can be more efficient. In HRL, although it is intuitive that a high-level policy only needs to make macro decisions in a low frequency, the exact frequency is hard to be simply determined. Previous HRL approaches often employed a fixed-time skip strategy or learn a terminal condition without taking account of the context, which, however, not only requires manual adjustments but also sacrifices some decision granularity. In this paper, we propose the \emph{temporal-adaptive hierarchical policy learning} (TEMPLE) structure, which uses a temporal gate to adaptively control the high-level policy decision frequency. We train the TEMPLE structure with PPO and test its performance in a range of environments including 2-D rooms, Mujoco tasks, and Atari games. The results show that the TEMPLE structure can lead to improved performance in these environments with a sequential adaptive high-level control.
Reinforcement Learning Experience Reuse with Policy Residual Representation
May 31, 2019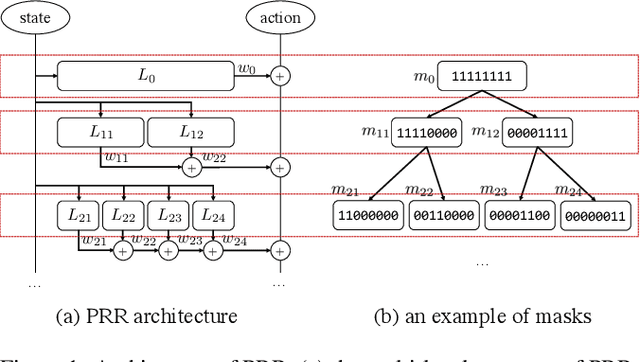

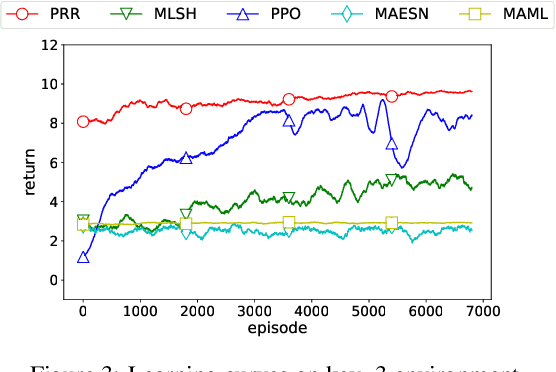
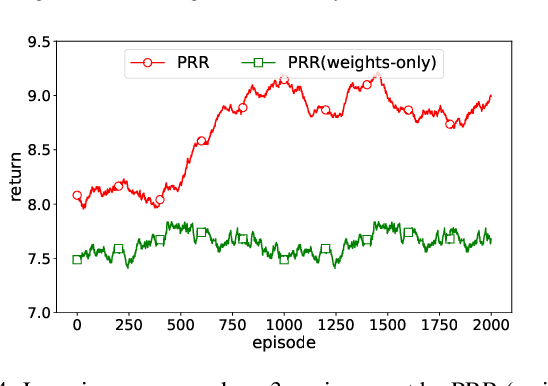
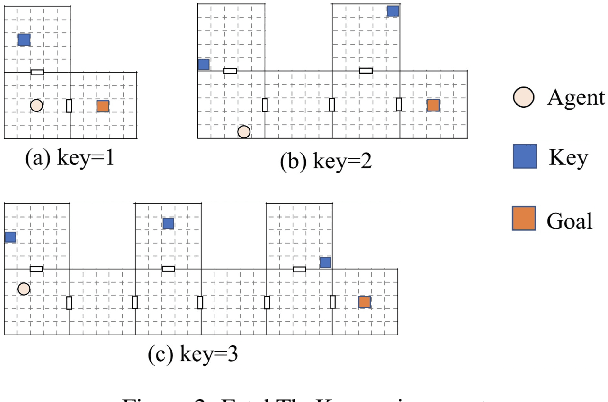
Experience reuse is key to sample-efficient reinforcement learning. One of the critical issues is how the experience is represented and stored. Previously, the experience can be stored in the forms of features, individual models, and the average model, each lying at a different granularity. However, new tasks may require experience across multiple granularities. In this paper, we propose the policy residual representation (PRR) network, which can extract and store multiple levels of experience. PRR network is trained on a set of tasks with a multi-level architecture, where a module in each level corresponds to a subset of the tasks. Therefore, the PRR network represents the experience in a spectrum-like way. When training on a new task, PRR can provide different levels of experience for accelerating the learning. We experiment with the PRR network on a set of grid world navigation tasks, locomotion tasks, and fighting tasks in a video game. The results show that the PRR network leads to better reuse of experience and thus outperforms some state-of-the-art approaches.