 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScenario-aware and Mutual-based approach for Multi-scenario Recommendation in E-Commerce
Dec 16, 2020

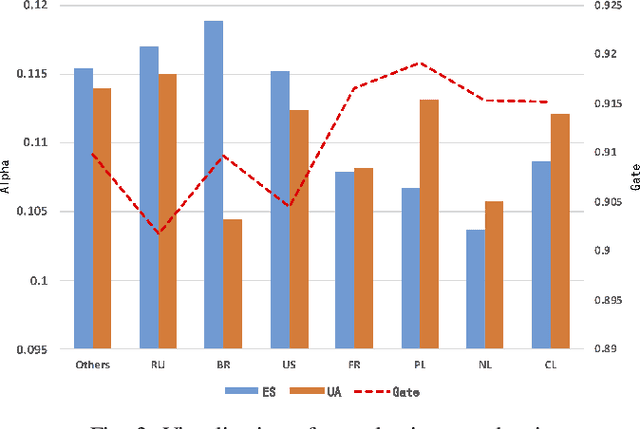
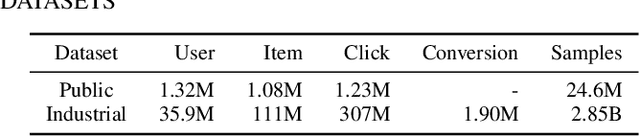
Recommender systems (RSs) are essential for e-commerce platforms to help meet the enormous needs of users. How to capture user interests and make accurate recommendations for users in heterogeneous e-commerce scenarios is still a continuous research topic. However, most existing studies overlook the intrinsic association of the scenarios: the log data collected from platforms can be naturally divided into different scenarios (e.g., country, city, culture). We observed that the scenarios are heterogeneous because of the huge differences among them. Therefore, a unified model is difficult to effectively capture complex correlations (e.g., differences and similarities) between multiple scenarios thus seriously reducing the accuracy of recommendation results. In this paper, we target the problem of multi-scenario recommendation in e-commerce, and propose a novel recommendation model named Scenario-aware Mutual Learning (SAML) that leverages the differences and similarities between multiple scenarios. We first introduce scenario-aware feature representation, which transforms the embedding and attention modules to map the features into both global and scenario-specific subspace in parallel. Then we introduce an auxiliary network to model the shared knowledge across all scenarios, and use a multi-branch network to model differences among specific scenarios. Finally, we employ a novel mutual unit to adaptively learn the similarity between various scenarios and incorporate it into multi-branch network. We conduct extensive experiments on both public and industrial datasets, empirical results show that SAML consistently and significantly outperforms state-of-the-art methods.
Validation Set Evaluation can be Wrong: An Evaluator-Generator Approach for Maximizing Online Performance of Ranking in E-commerce
Mar 27, 2020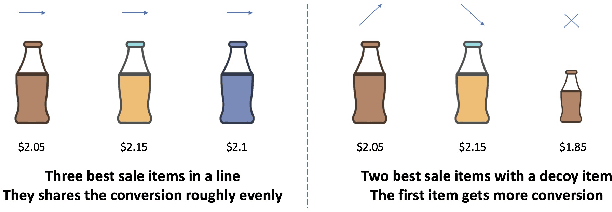
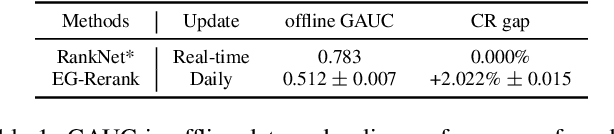
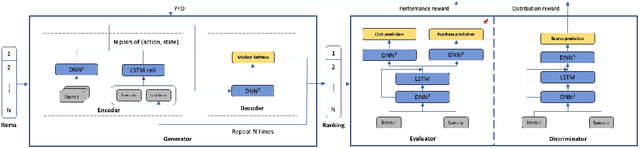
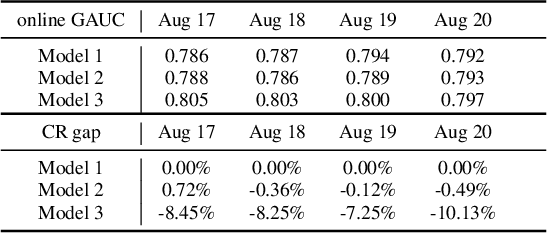
Learning-to-rank (LTR) has become a key technology in E-commerce applications. Previous LTR approaches followed the supervised learning paradigm so that learned models should match the labeled data point-wisely or pair-wisely. However, we have noticed that global context information, including the total order of items in the displayed webpage, can play an important role in interactions with the customers. Therefore, to approach the best global ordering, the exploration in a large combinatorial space of items is necessary, which requires evaluating orders that may not appear in the labeled data. In this scenario, we first show that the classical data-based metrics can be inconsistent with online performance, or even misleading. We then propose to learn an evaluator and search the best model guided by the evaluator, which forms the evaluator-generator framework for training the group-wise LTR model. The evaluator is learned from the labeled data, and is enhanced by incorporating the order context information. The generator is trained with the supervision of the evaluator by reinforcement learning to generate the best order in the combinatorial space. Our experiments in one of the world's largest retail platforms disclose that the learned evaluator is a much better indicator than classical data-based metrics. Moreover, our LTR model achieves a significant improvement ($\textgreater2\%$) from the current industrial-level pair-wise models in terms of both Conversion Rate (CR) and Gross Merchandise Volume (GMV) in online A/B tests.
Policy Optimization with Model-based Explorations
Nov 18, 2018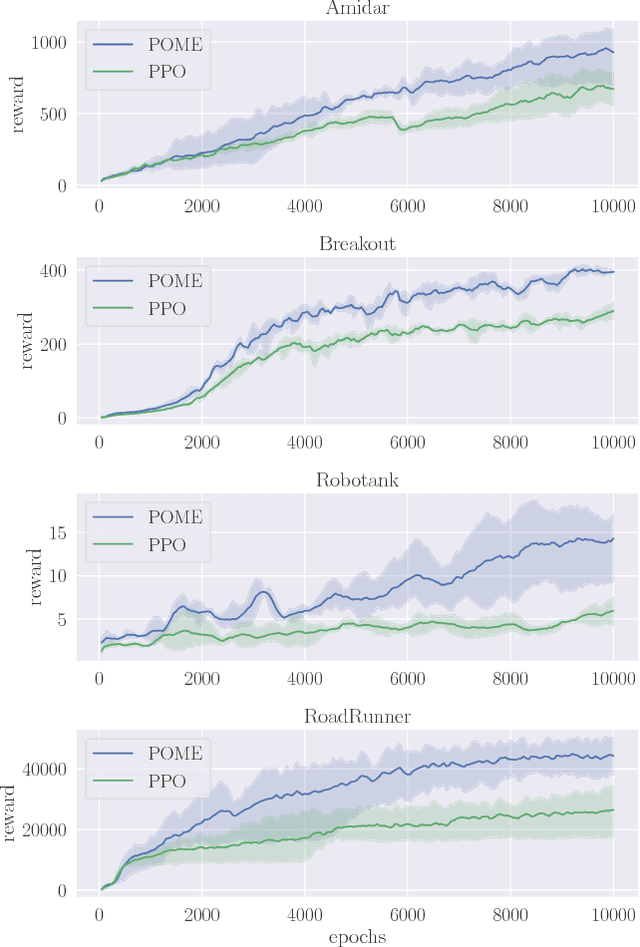
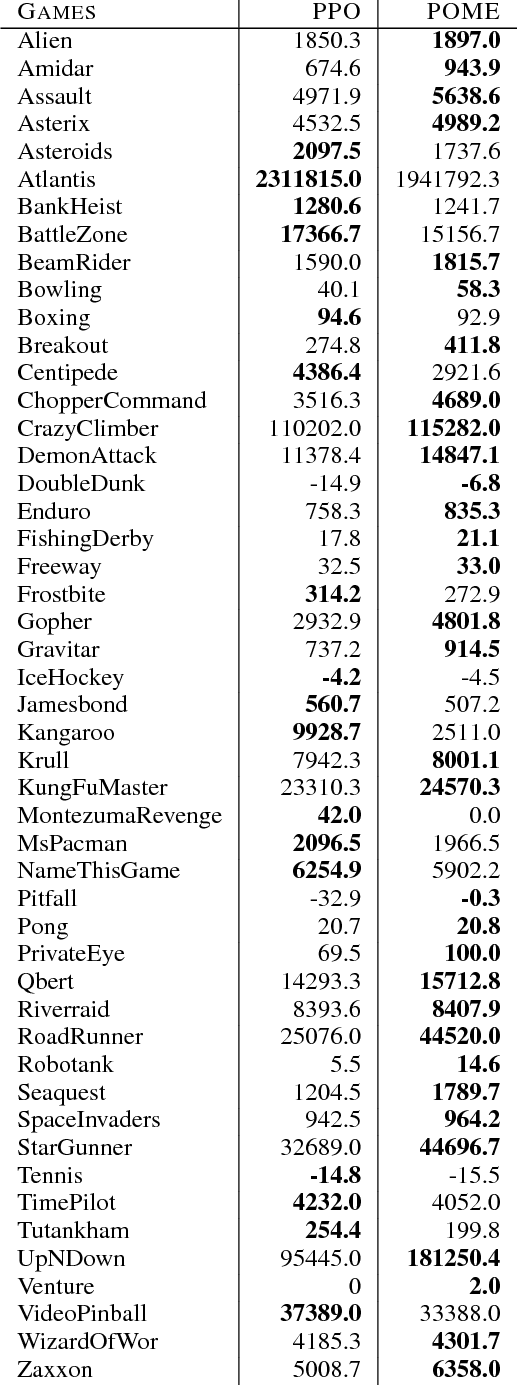
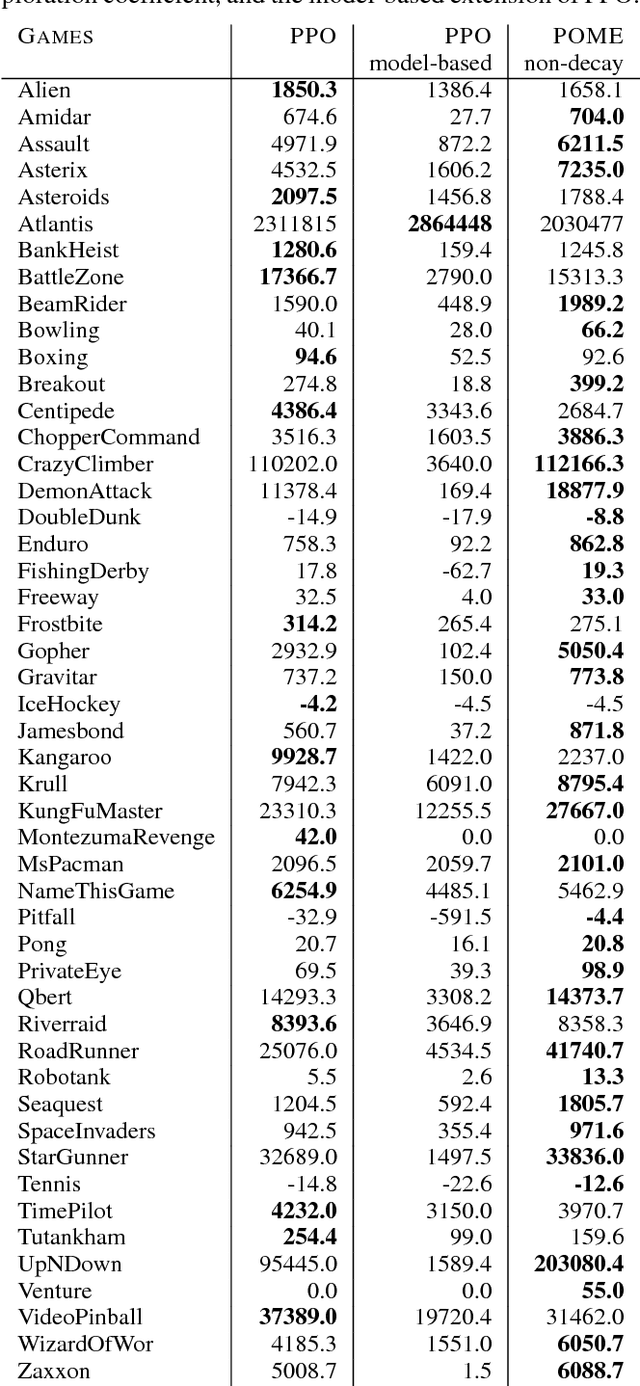
Model-free reinforcement learning methods such as the Proximal Policy Optimization algorithm (PPO) have successfully applied in complex decision-making problems such as Atari games. However, these methods suffer from high variances and high sample complexity. On the other hand, model-based reinforcement learning methods that learn the transition dynamics are more sample efficient, but they often suffer from the bias of the transition estimation. How to make use of both model-based and model-free learning is a central problem in reinforcement learning. In this paper, we present a new technique to address the trade-off between exploration and exploitation, which regards the difference between model-free and model-based estimations as a measure of exploration value. We apply this new technique to the PPO algorithm and arrive at a new policy optimization method, named Policy Optimization with Model-based Explorations (POME). POME uses two components to predict the actions' target values: a model-free one estimated by Monte-Carlo sampling and a model-based one which learns a transition model and predicts the value of the next state. POME adds the error of these two target estimations as the additional exploration value for each state-action pair, i.e, encourages the algorithm to explore the states with larger target errors which are hard to estimate. We compare POME with PPO on Atari 2600 games, and it shows that POME outperforms PPO on 33 games out of 49 games.
Selective Zero-Shot Classification with Augmented Attributes
Jul 19, 2018
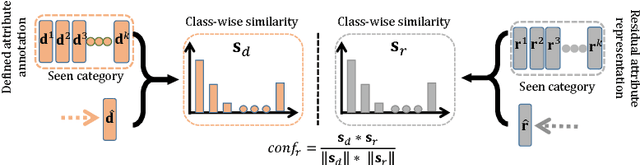
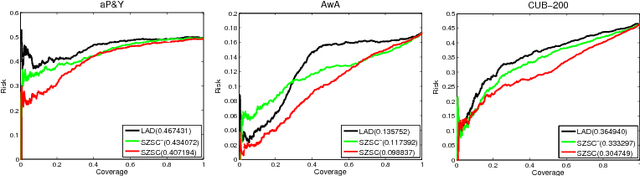
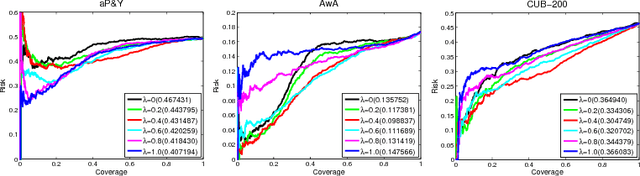
In this paper, we introduce a selective zero-shot classification problem: how can the classifier avoid making dubious predictions? Existing attribute-based zero-shot classification methods are shown to work poorly in the selective classification scenario. We argue the under-complete human defined attribute vocabulary accounts for the poor performance. We propose a selective zero-shot classifier based on both the human defined and the automatically discovered residual attributes. The proposed classifier is constructed by firstly learning the defined and the residual attributes jointly. Then the predictions are conducted within the subspace of the defined attributes. Finally, the prediction confidence is measured by both the defined and the residual attributes. Experiments conducted on several benchmarks demonstrate that our classifier produces a superior performance to other methods under the risk-coverage trade-off metric.
Speeding up the Metabolism in E-commerce by Reinforcement Mechanism Design
Jul 02, 2018

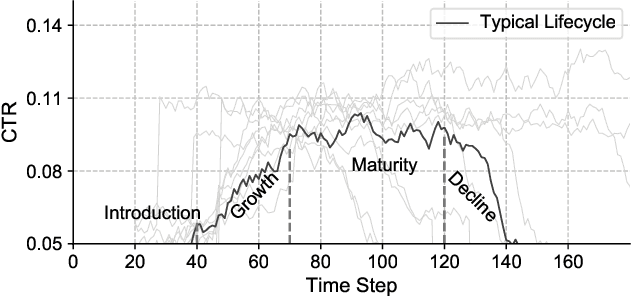
In a large E-commerce platform, all the participants compete for impressions under the allocation mechanism of the platform. Existing methods mainly focus on the short-term return based on the current observations instead of the long-term return. In this paper, we formally establish the lifecycle model for products, by defining the introduction, growth, maturity and decline stages and their transitions throughout the whole life period. Based on such model, we further propose a reinforcement learning based mechanism design framework for impression allocation, which incorporates the first principal component based permutation and the novel experiences generation method, to maximize short-term as well as long-term return of the platform. With the power of trial-and-error, it is possible to optimize impression allocation strategies globally which is contribute to the healthy development of participants and the platform itself. We evaluate our algorithm on a simulated environment built based on one of the largest E-commerce platforms, and a significant improvement has been achieved in comparison with the baseline solutions.
Virtual-Taobao: Virtualizing Real-world Online Retail Environment for Reinforcement Learning
May 25, 2018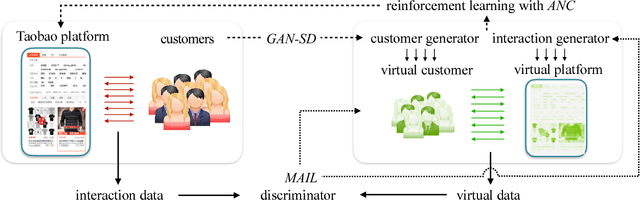
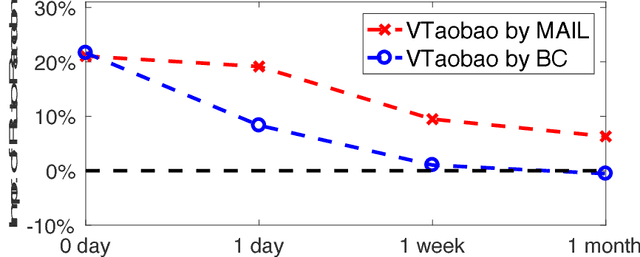
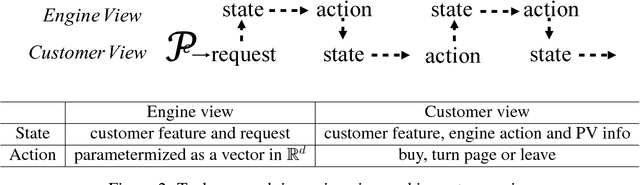

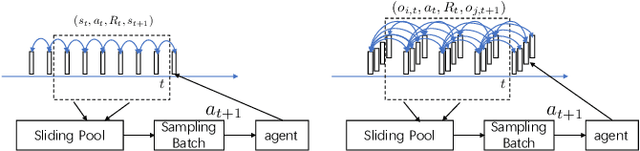
Applying reinforcement learning in physical-world tasks is extremely challenging. It is commonly infeasible to sample a large number of trials, as required by current reinforcement learning methods, in a physical environment. This paper reports our project on using reinforcement learning for better commodity search in Taobao, one of the largest online retail platforms and meanwhile a physical environment with a high sampling cost. Instead of training reinforcement learning in Taobao directly, we present our approach: first we build Virtual Taobao, a simulator learned from historical customer behavior data through the proposed GAN-SD (GAN for Simulating Distributions) and MAIL (multi-agent adversarial imitation learning), and then we train policies in Virtual Taobao with no physical costs in which ANC (Action Norm Constraint) strategy is proposed to reduce over-fitting. In experiments, Virtual Taobao is trained from hundreds of millions of customers' records, and its properties are compared with the real environment. The results disclose that Virtual Taobao faithfully recovers important properties of the real environment. We also show that the policies trained in Virtual Taobao can have significantly superior online performance to the traditional supervised approaches. We hope our work could shed some light on reinforcement learning applications in complex physical environments.