 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised High-Fidelity Clothing Model Generation
Dec 14, 2021
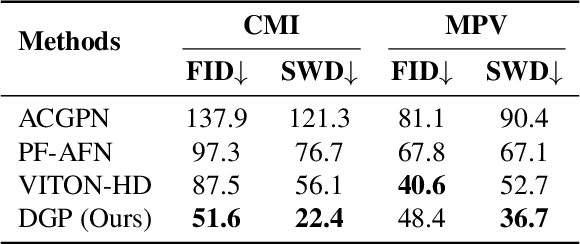
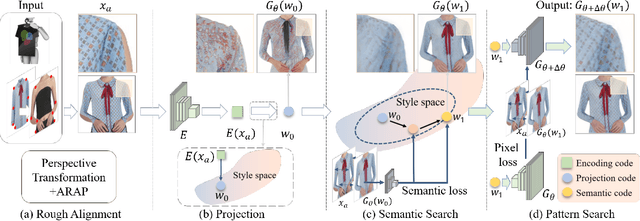

The development of online economics arouses the demand of generating images of models on product clothes, to display new clothes and promote sales. However, the expensive proprietary model images challenge the existing image virtual try-on methods in this scenario, as most of them need to be trained on considerable amounts of model images accompanied with paired clothes images. In this paper, we propose a cheap yet scalable weakly-supervised method called Deep Generative Projection (DGP) to address this specific scenario. Lying in the heart of the proposed method is to imitate the process of human predicting the wearing effect, which is an unsupervised imagination based on life experience rather than computation rules learned from supervisions. Here a pretrained StyleGAN is used to capture the practical experience of wearing. Experiments show that projecting the rough alignment of clothing and body onto the StyleGAN space can yield photo-realistic wearing results. Experiments on real scene proprietary model images demonstrate the superiority of DGP over several state-of-the-art supervised methods when generating clothing model images.
Shape Controllable Virtual Try-on for Underwear Models
Jul 28, 2021
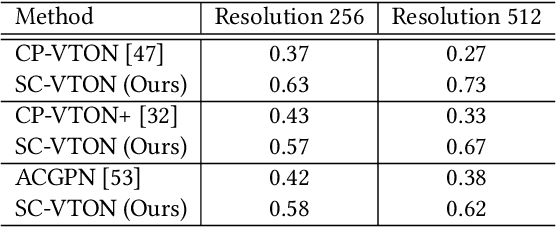
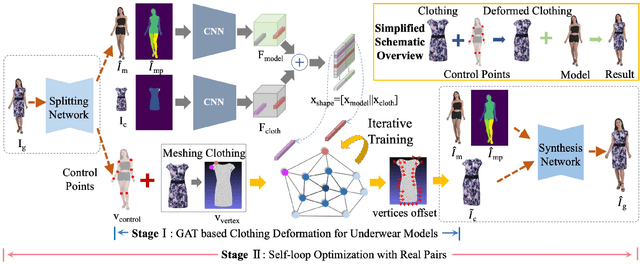
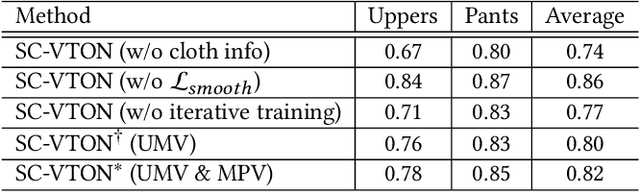
Image virtual try-on task has abundant applications and has become a hot research topic recently. Existing 2D image-based virtual try-on methods aim to transfer a target clothing image onto a reference person, which has two main disadvantages: cannot control the size and length precisely; unable to accurately estimate the user's figure in the case of users wearing thick clothes, resulting in inaccurate dressing effect. In this paper, we put forward an akin task that aims to dress clothing for underwear models. %, which is also an urgent need in e-commerce scenarios. To solve the above drawbacks, we propose a Shape Controllable Virtual Try-On Network (SC-VTON), where a graph attention network integrates the information of model and clothing to generate the warped clothing image. In addition, the control points are incorporated into SC-VTON for the desired clothing shape. Furthermore, by adding a Splitting Network and a Synthesis Network, we can use clothing/model pair data to help optimize the deformation module and generalize the task to the typical virtual try-on task. Extensive experiments show that the proposed method can achieve accurate shape control. Meanwhile, compared with other methods, our method can generate high-resolution results with detailed textures.
Amalgamating Filtered Knowledge: Learning Task-customized Student from Multi-task Teachers
May 28, 2019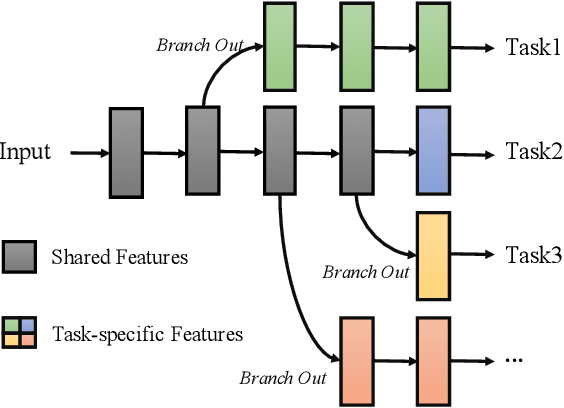
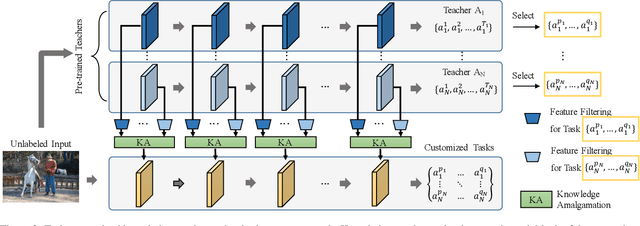

Many well-trained Convolutional Neural Network(CNN) models have now been released online by developers for the sake of effortless reproducing. In this paper, we treat such pre-trained networks as teachers and explore how to learn a target student network for customized tasks, using multiple teachers that handle different tasks. We assume no human-labelled annotations are available, and each teacher model can be either single- or multi-task network, where the former is a degenerated case of the latter. The student model, depending on the customized tasks, learns the related knowledge filtered from the multiple teachers, and eventually masters the complete or a subset of expertise from all teachers. To this end, we adopt a layer-wise training strategy, which entangles the student's network block to be learned with the corresponding teachers. As demonstrated on several benchmarks, the learned student network achieves very promising results, even outperforming the teachers on the customized tasks.
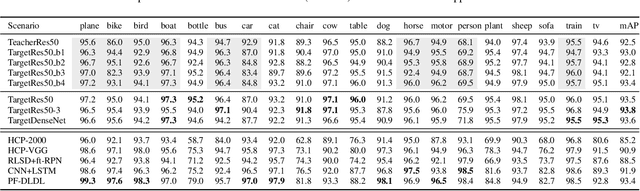
Student Becoming the Master: Knowledge Amalgamation for Joint Scene Parsing, Depth Estimation, and More
Apr 23, 2019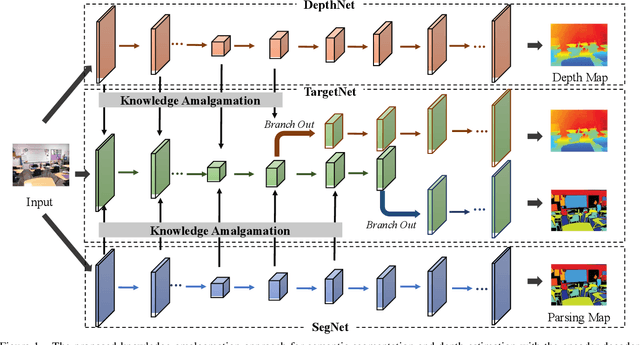
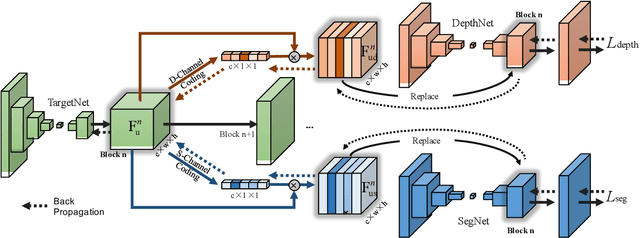
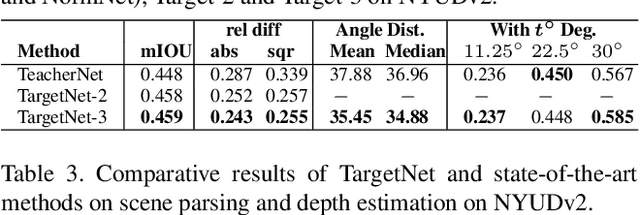
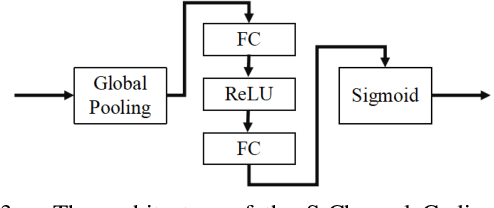
In this paper, we investigate a novel deep-model reusing task. Our goal is to train a lightweight and versatile student model, without human-labelled annotations, that amalgamates the knowledge and masters the expertise of two pretrained teacher models working on heterogeneous problems, one on scene parsing and the other on depth estimation. To this end, we propose an innovative training strategy that learns the parameters of the student intertwined with the teachers, achieved by 'projecting' its amalgamated features onto each teacher's domain and computing the loss. We also introduce two options to generalize the proposed training strategy to handle three or more tasks simultaneously. The proposed scheme yields very encouraging results. As demonstrated on several benchmarks, the trained student model achieves results even superior to those of the teachers in their own expertise domains and on par with the state-of-the-art fully supervised models relying on human-labelled annotations.
Selective Zero-Shot Classification with Augmented Attributes
Jul 19, 2018
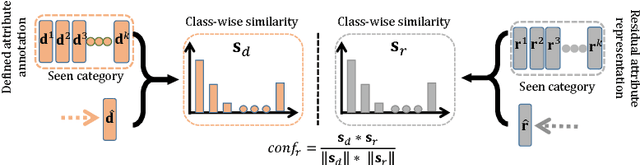
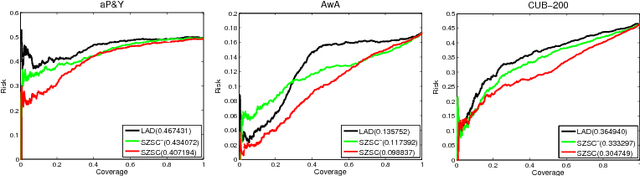
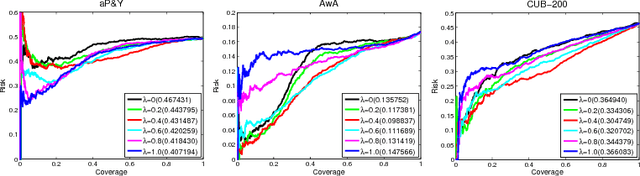
In this paper, we introduce a selective zero-shot classification problem: how can the classifier avoid making dubious predictions? Existing attribute-based zero-shot classification methods are shown to work poorly in the selective classification scenario. We argue the under-complete human defined attribute vocabulary accounts for the poor performance. We propose a selective zero-shot classifier based on both the human defined and the automatically discovered residual attributes. The proposed classifier is constructed by firstly learning the defined and the residual attributes jointly. Then the predictions are conducted within the subspace of the defined attributes. Finally, the prediction confidence is measured by both the defined and the residual attributes. Experiments conducted on several benchmarks demonstrate that our classifier produces a superior performance to other methods under the risk-coverage trade-off metric.