 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLI-Gym: Scalable CLI Task Generation via Agentic Environment Inversion
Feb 11, 2026Agentic coding requires agents to effectively interact with runtime environments, e.g., command line interfaces (CLI), so as to complete tasks like resolving dependency issues, fixing system problems, etc. But it remains underexplored how such environment-intensive tasks can be obtained at scale to enhance agents' capabilities. To address this, based on an analogy between the Dockerfile and the agentic task, we propose to employ agents to simulate and explore environment histories, guided by execution feedback. By tracing histories of a healthy environment, its state can be inverted to an earlier one with runtime failures, from which a task can be derived by packing the buggy state and the corresponding error messages. With our method, named CLI-Gym, a total of 1,655 environment-intensive tasks are derived, being the largest collection of its kind. Moreover, with curated successful trajectories, our fine-tuned model, named LiberCoder, achieves substantial absolute improvements of +21.1% (to 46.1%) on Terminal-Bench, outperforming various strong baselines. To our knowledge, this is the first public pipeline for scalable derivation of environment-intensive tasks.
FeatureBench: Benchmarking Agentic Coding for Complex Feature Development
Feb 11, 2026Agents powered by large language models (LLMs) are increasingly adopted in the software industry, contributing code as collaborators or even autonomous developers. As their presence grows, it becomes important to assess the current boundaries of their coding abilities. Existing agentic coding benchmarks, however, cover a limited task scope, e.g., bug fixing within a single pull request (PR), and often rely on non-executable evaluations or lack an automated approach for continually updating the evaluation coverage. To address such issues, we propose FeatureBench, a benchmark designed to evaluate agentic coding performance in end-to-end, feature-oriented software development. FeatureBench incorporates an execution-based evaluation protocol and a scalable test-driven method that automatically derives tasks from code repositories with minimal human effort. By tracing from unit tests along a dependency graph, our approach can identify feature-level coding tasks spanning multiple commits and PRs scattered across the development timeline, while ensuring the proper functioning of other features after the separation. Using this framework, we curated 200 challenging evaluation tasks and 3825 executable environments from 24 open-source repositories in the first version of our benchmark. Empirical evaluation reveals that the state-of-the-art agentic model, such as Claude 4.5 Opus, which achieves a 74.4% resolved rate on SWE-bench, succeeds on only 11.0% of tasks, opening new opportunities for advancing agentic coding. Moreover, benefiting from our automated task collection toolkit, FeatureBench can be easily scaled and updated over time to mitigate data leakage. The inherent verifiability of constructed environments also makes our method potentially valuable for agent training.
Distilling the Implicit Multi-Branch Structure in LLMs' Reasoning via Reinforcement Learning
May 22, 2025Distilling reasoning paths from teacher to student models via supervised fine-tuning (SFT) provides a shortcut for improving the reasoning ability of smaller Large Language Models (LLMs). However, the reasoning paths generated by teacher models often reflect only surface-level traces of their underlying authentic reasoning. Insights from cognitive neuroscience suggest that authentic reasoning involves a complex interweaving between meta-reasoning (which selects appropriate sub-problems from multiple candidates) and solving (which addresses the sub-problem). This implies authentic reasoning has an implicit multi-branch structure. Supervised fine-tuning collapses this rich structure into a flat sequence of token prediction in the teacher's reasoning path, preventing effective distillation of this structure to students. To address this limitation, we propose RLKD, a reinforcement learning (RL)-based distillation framework guided by a novel Generative Structure Reward Model (GSRM). Our GSRM converts reasoning paths into multiple meta-reasoning-solving steps and computes rewards to measure structural alignment between student and teacher reasoning. RLKD combines this reward with RL, enabling student LLMs to internalize the teacher's implicit multi-branch reasoning structure rather than merely mimicking fixed output paths. Experiments show RLKD surpasses standard SFT-RL pipelines even when trained on 0.1% of data under an RL-only regime, unlocking greater student reasoning potential than SFT-based distillation.
Style Miner: Find Significant and Stable Explanatory Factors in Time Series with Constrained Reinforcement Learning
Mar 21, 2023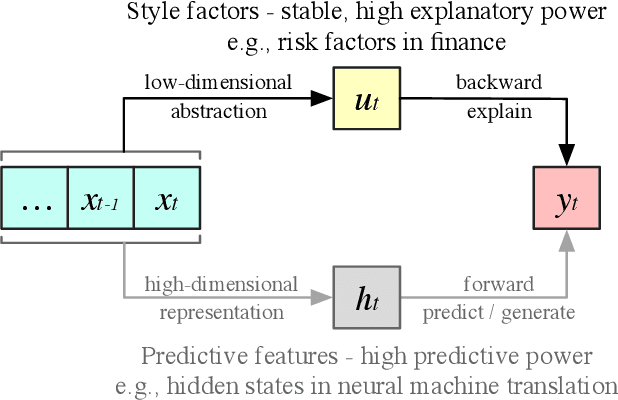



In high-dimensional time-series analysis, it is essential to have a set of key factors (namely, the style factors) that explain the change of the observed variable. For example, volatility modeling in finance relies on a set of risk factors, and climate change studies in climatology rely on a set of causal factors. The ideal low-dimensional style factors should balance significance (with high explanatory power) and stability (consistent, no significant fluctuations). However, previous supervised and unsupervised feature extraction methods can hardly address the tradeoff. In this paper, we propose Style Miner, a reinforcement learning method to generate style factors. We first formulate the problem as a Constrained Markov Decision Process with explanatory power as the return and stability as the constraint. Then, we design fine-grained immediate rewards and costs and use a Lagrangian heuristic to balance them adaptively. Experiments on real-world financial data sets show that Style Miner outperforms existing learning-based methods by a large margin and achieves a relatively 10% gain in R-squared explanatory power compared to the industry-renowned factors proposed by human experts.
Learn Continuously, Act Discretely: Hybrid Action-Space Reinforcement Learning For Optimal Execution
Jul 22, 2022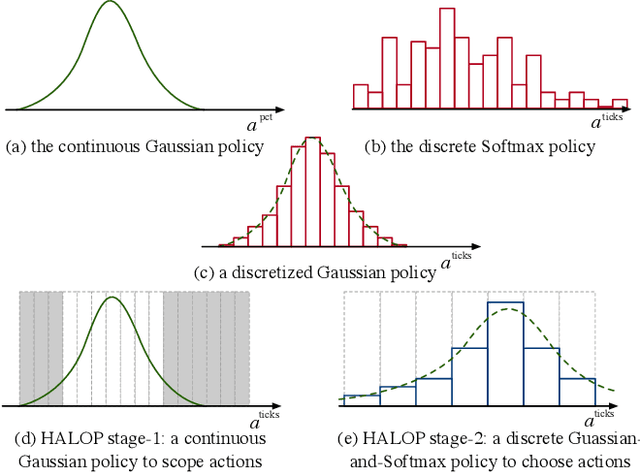
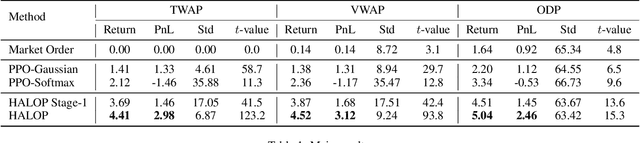
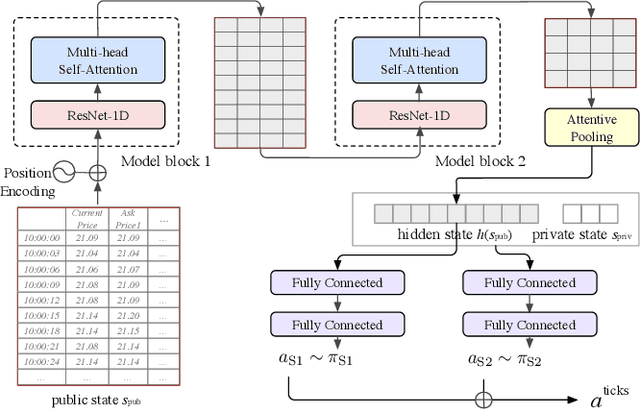

Optimal execution is a sequential decision-making problem for cost-saving in algorithmic trading. Studies have found that reinforcement learning (RL) can help decide the order-splitting sizes. However, a problem remains unsolved: how to place limit orders at appropriate limit prices? The key challenge lies in the "continuous-discrete duality" of the action space. On the one hand, the continuous action space using percentage changes in prices is preferred for generalization. On the other hand, the trader eventually needs to choose limit prices discretely due to the existence of the tick size, which requires specialization for every single stock with different characteristics (e.g., the liquidity and the price range). So we need continuous control for generalization and discrete control for specialization. To this end, we propose a hybrid RL method to combine the advantages of both of them. We first use a continuous control agent to scope an action subset, then deploy a fine-grained agent to choose a specific limit price. Extensive experiments show that our method has higher sample efficiency and better training stability than existing RL algorithms and significantly outperforms previous learning-based methods for order execution.
Follow the Prophet: Accurate Online Conversion Rate Prediction in the Face of Delayed Feedback
Aug 13, 2021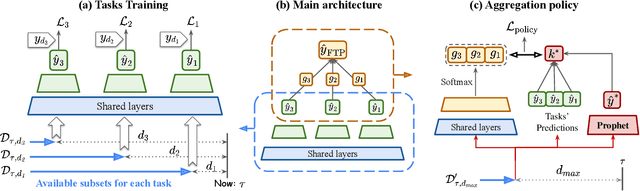
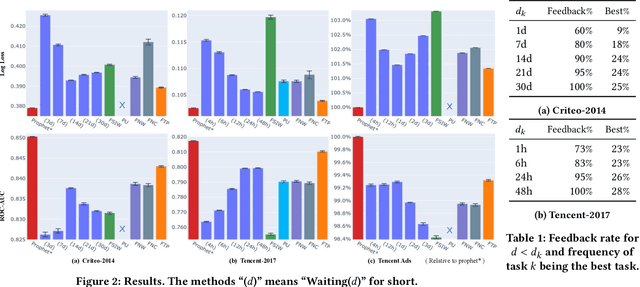
The delayed feedback problem is one of the imperative challenges in online advertising, which is caused by the highly diversified feedback delay of a conversion varying from a few minutes to several days. It is hard to design an appropriate online learning system under these non-identical delay for different types of ads and users. In this paper, we propose to tackle the delayed feedback problem in online advertising by "Following the Prophet" (FTP for short). The key insight is that, if the feedback came instantly for all the logged samples, we could get a model without delayed feedback, namely the "prophet". Although the prophet cannot be obtained during online learning, we show that we could predict the prophet's predictions by an aggregation policy on top of a set of multi-task predictions, where each task captures the feedback patterns of different periods. We propose the objective and optimization approach for the policy, and use the logged data to imitate the prophet. Extensive experiments on three real-world advertising datasets show that our method outperforms the previous state-of-the-art baselines.
GuideBoot: Guided Bootstrap for Deep Contextual Bandits
Jul 18, 2021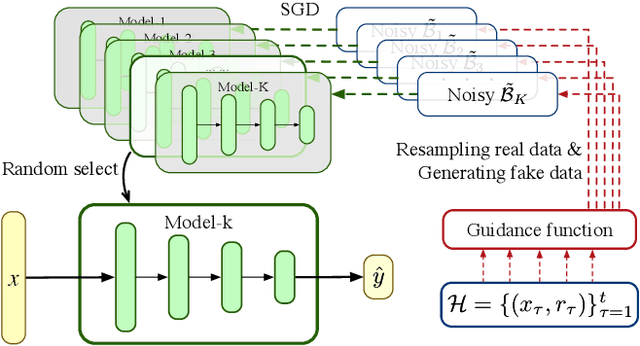
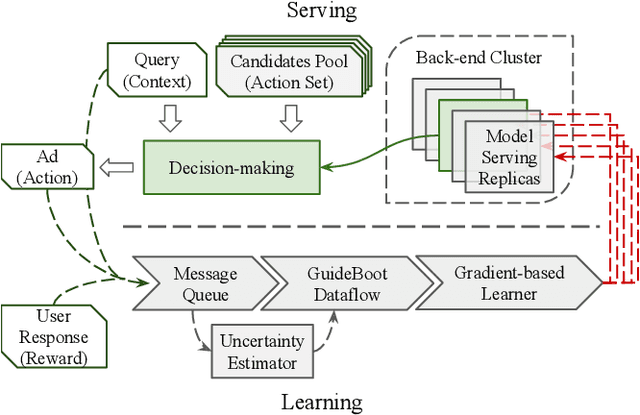
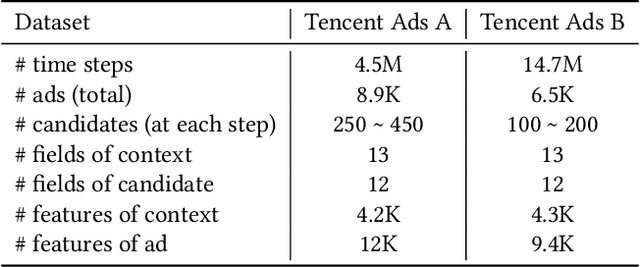
The exploration/exploitation (E&E) dilemma lies at the core of interactive systems such as online advertising, for which contextual bandit algorithms have been proposed. Bayesian approaches provide guided exploration with principled uncertainty estimation, but the applicability is often limited due to over-simplified assumptions. Non-Bayesian bootstrap methods, on the other hand, can apply to complex problems by using deep reward models, but lacks clear guidance to the exploration behavior. It still remains largely unsolved to develop a practical method for complex deep contextual bandits. In this paper, we introduce Guided Bootstrap (GuideBoot for short), combining the best of both worlds. GuideBoot provides explicit guidance to the exploration behavior by training multiple models over both real samples and noisy samples with fake labels, where the noise is added according to the predictive uncertainty. The proposed method is efficient as it can make decisions on-the-fly by utilizing only one randomly chosen model, but is also effective as we show that it can be viewed as a non-Bayesian approximation of Thompson sampling. Moreover, we extend it to an online version that can learn solely from streaming data, which is favored in real applications. Extensive experiments on both synthetic task and large-scale advertising environments show that GuideBoot achieves significant improvements against previous state-of-the-art methods.
Trust the Model When It Is Confident: Masked Model-based Actor-Critic
Oct 10, 2020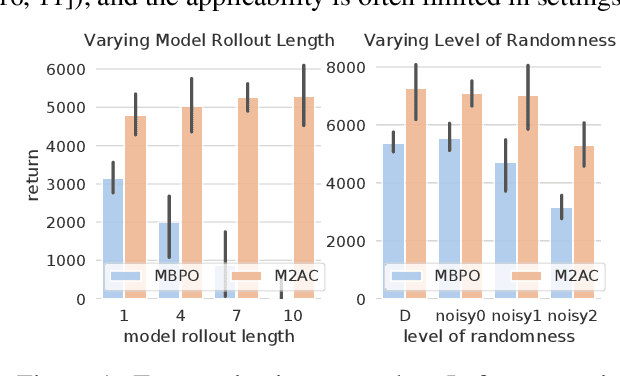
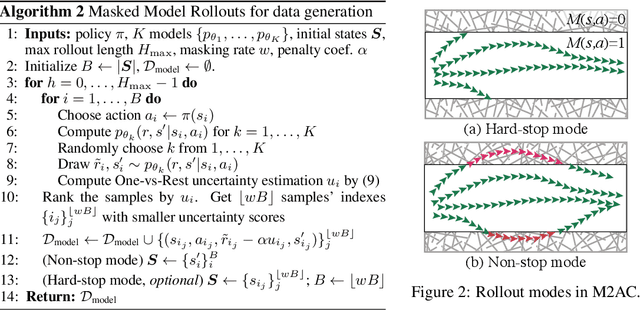
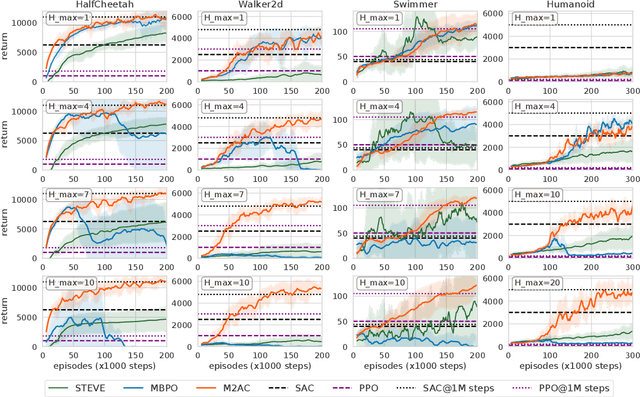
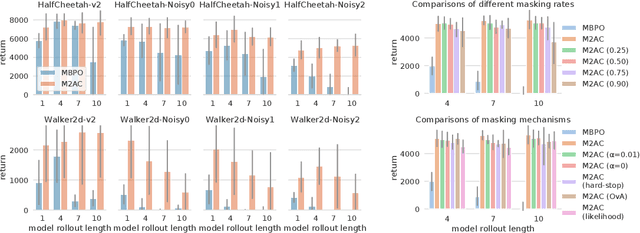
It is a popular belief that model-based Reinforcement Learning (RL) is more sample efficient than model-free RL, but in practice, it is not always true due to overweighed model errors. In complex and noisy settings, model-based RL tends to have trouble using the model if it does not know when to trust the model. In this work, we find that better model usage can make a huge difference. We show theoretically that if the use of model-generated data is restricted to state-action pairs where the model error is small, the performance gap between model and real rollouts can be reduced. It motivates us to use model rollouts only when the model is confident about its predictions. We propose Masked Model-based Actor-Critic (M2AC), a novel policy optimization algorithm that maximizes a model-based lower-bound of the true value function. M2AC implements a masking mechanism based on the model's uncertainty to decide whether its prediction should be used or not. Consequently, the new algorithm tends to give robust policy improvements. Experiments on continuous control benchmarks demonstrate that M2AC has strong performance even when using long model rollouts in very noisy environments, and it significantly outperforms previous state-of-the-art methods.
GoChat: Goal-oriented Chatbots with Hierarchical Reinforcement Learning
May 26, 2020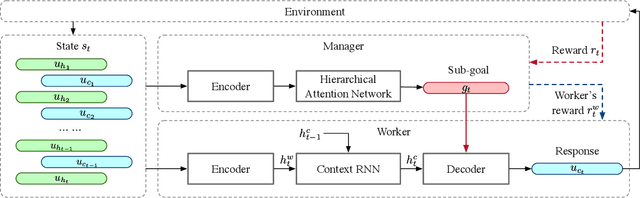
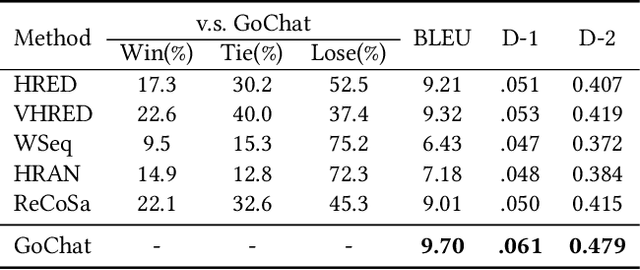

A chatbot that converses like a human should be goal-oriented (i.e., be purposeful in conversation), which is beyond language generation. However, existing dialogue systems often heavily rely on cumbersome hand-crafted rules or costly labelled datasets to reach the goals. In this paper, we propose Goal-oriented Chatbots (GoChat), a framework for end-to-end training chatbots to maximize the longterm return from offline multi-turn dialogue datasets. Our framework utilizes hierarchical reinforcement learning (HRL), where the high-level policy guides the conversation towards the final goal by determining some sub-goals, and the low-level policy fulfills the sub-goals by generating the corresponding utterance for response. In our experiments on a real-world dialogue dataset for anti-fraud in financial, our approach outperforms previous methods on both the quality of response generation as well as the success rate of accomplishing the goal.
Towards reliable and fair probabilistic predictions: field-aware calibration with neural networks
May 28, 2019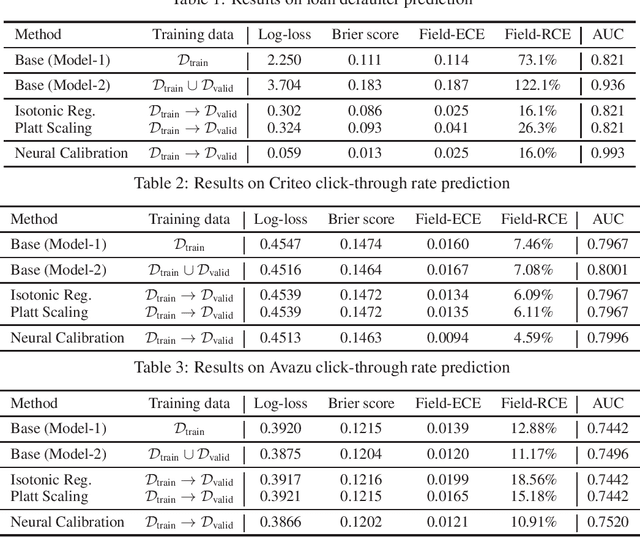
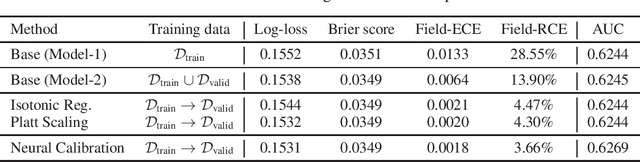
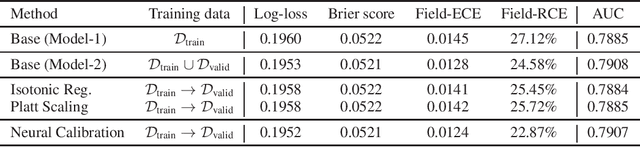
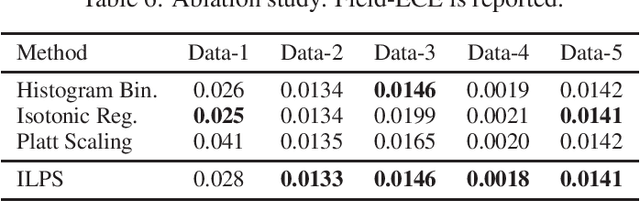
In machine learning, it is observed that probabilistic predictions sometimes disagree with averaged actual outcomes on certain subsets of data. This is also known as miscalibration that is responsible for unreliability and unfairness of practical machine learning systems. In this paper, we put forward an evaluation metric for calibration, coined field-level calibration error, that measures bias in predictions over the input fields that the decision maker concerns. We show that existing calibration methods perform poorly under our new metric. Specifically, after learning a calibration mapping over the validation dataset, existing methods have limited improvements in our error metric and completely fail to improve other non-calibration metrics such as the AUC score. We propose Neural Calibration, a new calibration method, which learns to calibrate by making full use of all input information over the validation set. We test our method on five large-scale real-world datasets. The results show that Neural Calibration significantly improves against uncalibrated predictions in all well-known metrics such as the negative log-likelihood, the Brier score, the AUC score, as well as our proposed field-level calibration error.