 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAwakening Dormant Users: Generative Recommendation with Counterfactual Functional Role Reasoning
Feb 13, 2026Awakening dormant users, who remain engaged but exhibit low conversion, is a pivotal driver for incremental GMV growth in large-scale e-commerce platforms. However, existing approaches often yield suboptimal results since they typically rely on single-step estimation of an item's intrinsic value (e.g., immediate click probability). This mechanism overlooks the instrumental effect of items, where specific interactions act as triggers to shape latent intent and drive subsequent decisions along a conversion trajectory. To bridge this gap, we propose RoleGen, a novel framework that synergizes a Conversion Trajectory Reasoner with a Generative Behavioral Backbone. Specifically, the LLM-based Reasoner explicitly models the context-dependent Functional Role of items to reconstruct intent evolution. It further employs counterfactual inference to simulate diverse conversion paths, effectively mitigating interest collapse. These reasoned candidate items are integrated into the generative backbone, which is optimized via a collaborative "Reasoning-Execution-Feedback-Reflection" closed-loop strategy to ensure grounded execution. Extensive offline experiments and online A/B testing on the Kuaishou e-commerce platform demonstrate that RoleGen achieves a 6.2% gain in Recall@1 and a 7.3% increase in online order volume, confirming its effectiveness in activating the dormant user base.
Customized Conversational Recommender Systems
Jun 30, 2022
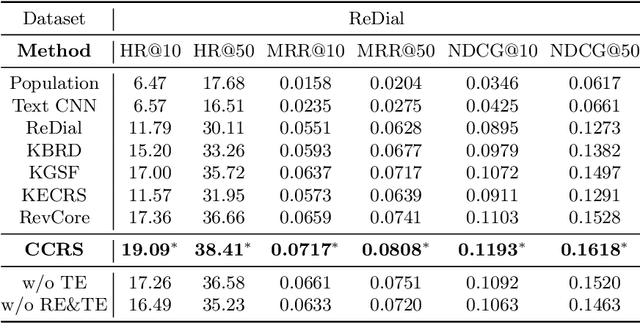
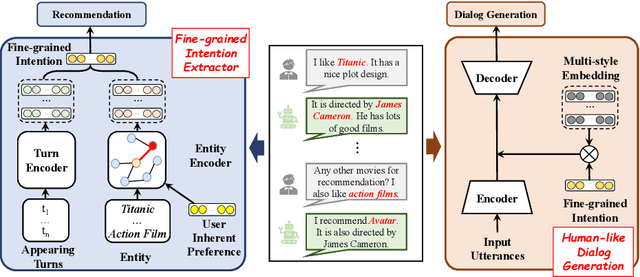
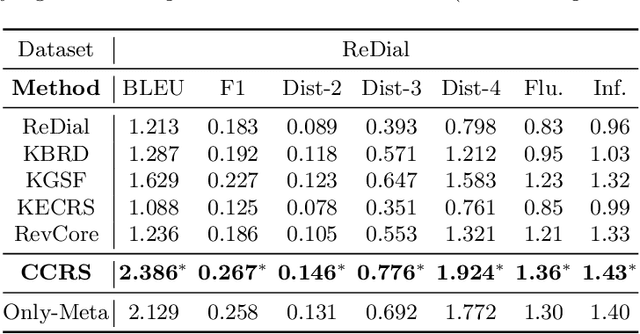
Conversational recommender systems (CRS) aim to capture user's current intentions and provide recommendations through real-time multi-turn conversational interactions. As a human-machine interactive system, it is essential for CRS to improve the user experience. However, most CRS methods neglect the importance of user experience. In this paper, we propose two key points for CRS to improve the user experience: (1) Speaking like a human, human can speak with different styles according to the current dialogue context. (2) Identifying fine-grained intentions, even for the same utterance, different users have diverse finegrained intentions, which are related to users' inherent preference. Based on the observations, we propose a novel CRS model, coined Customized Conversational Recommender System (CCRS), which customizes CRS model for users from three perspectives. For human-like dialogue services, we propose multi-style dialogue response generator which selects context-aware speaking style for utterance generation. To provide personalized recommendations, we extract user's current fine-grained intentions from dialogue context with the guidance of user's inherent preferences. Finally, to customize the model parameters for each user, we train the model from the meta-learning perspective. Extensive experiments and a series of analyses have shown the superiority of our CCRS on both the recommendation and dialogue services.
User-Centric Conversational Recommendation with Multi-Aspect User Modeling
Apr 25, 2022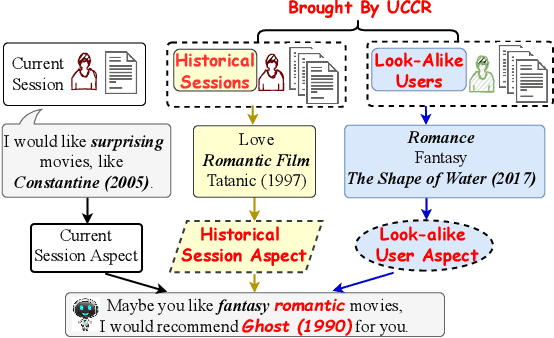
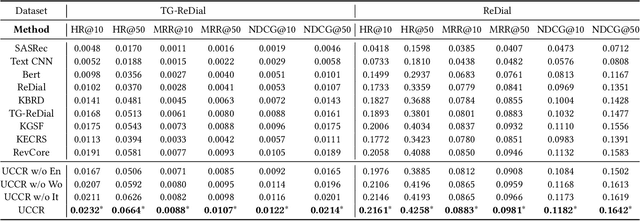

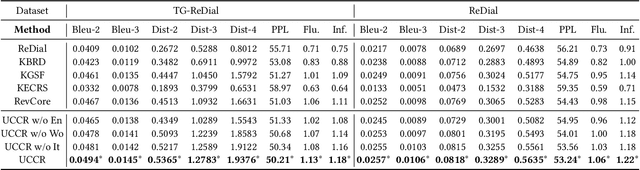
Conversational recommender systems (CRS) aim to provide highquality recommendations in conversations. However, most conventional CRS models mainly focus on the dialogue understanding of the current session, ignoring other rich multi-aspect information of the central subjects (i.e., users) in recommendation. In this work, we highlight that the user's historical dialogue sessions and look-alike users are essential sources of user preferences besides the current dialogue session in CRS. To systematically model the multi-aspect information, we propose a User-Centric Conversational Recommendation (UCCR) model, which returns to the essence of user preference learning in CRS tasks. Specifically, we propose a historical session learner to capture users' multi-view preferences from knowledge, semantic, and consuming views as supplements to the current preference signals. A multi-view preference mapper is conducted to learn the intrinsic correlations among different views in current and historical sessions via self-supervised objectives. We also design a temporal look-alike user selector to understand users via their similar users. The learned multi-aspect multi-view user preferences are then used for the recommendation and dialogue generation. In experiments, we conduct comprehensive evaluations on both Chinese and English CRS datasets. The significant improvements over competitive models in both recommendation and dialogue generation verify the superiority of UCCR.
Generalizing to the Future: Mitigating Entity Bias in Fake News Detection
Apr 20, 2022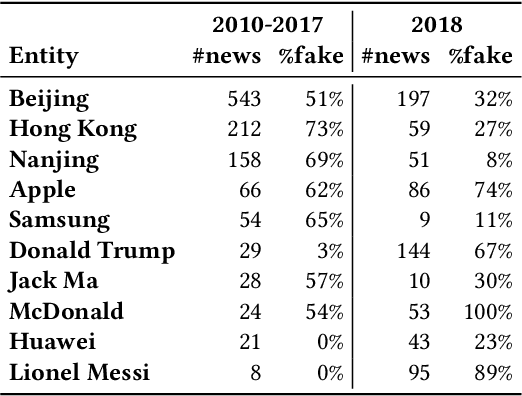
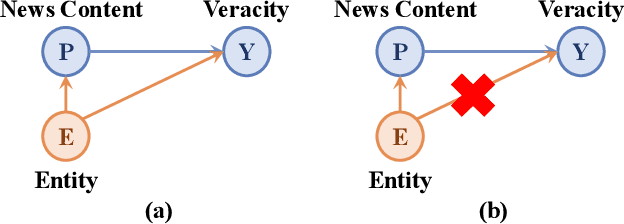

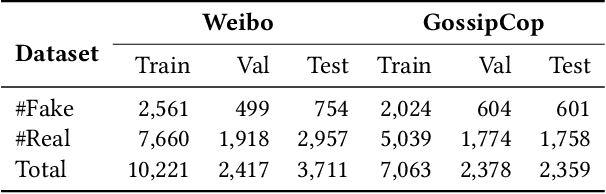
The wide dissemination of fake news is increasingly threatening both individuals and society. Fake news detection aims to train a model on the past news and detect fake news of the future. Though great efforts have been made, existing fake news detection methods overlooked the unintended entity bias in the real-world data, which seriously influences models' generalization ability to future data. For example, 97\% of news pieces in 2010-2017 containing the entity `Donald Trump' are real in our data, but the percentage falls down to merely 33\% in 2018. This would lead the model trained on the former set to hardly generalize to the latter, as it tends to predict news pieces about `Donald Trump' as real for lower training loss. In this paper, we propose an entity debiasing framework (\textbf{ENDEF}) which generalizes fake news detection models to the future data by mitigating entity bias from a cause-effect perspective. Based on the causal graph among entities, news contents, and news veracity, we separately model the contribution of each cause (entities and contents) during training. In the inference stage, we remove the direct effect of the entities to mitigate entity bias. Extensive offline experiments on the English and Chinese datasets demonstrate that the proposed framework can largely improve the performance of base fake news detectors, and online tests verify its superiority in practice. To the best of our knowledge, this is the first work to explicitly improve the generalization ability of fake news detection models to the future data. The code has been released at https://github.com/ICTMCG/ENDEF-SIGIR2022.
Warm Up Cold-start Advertisements: Improving CTR Predictions via Learning to Learn ID Embeddings
Apr 25, 2019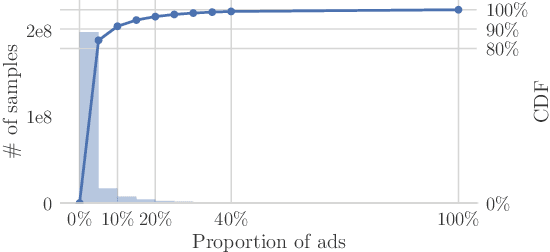
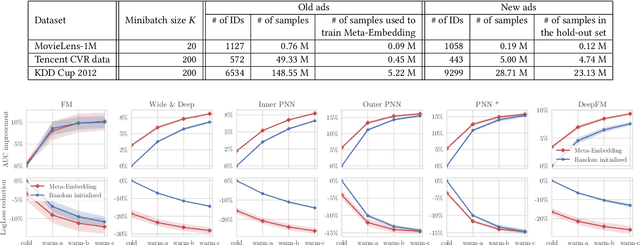
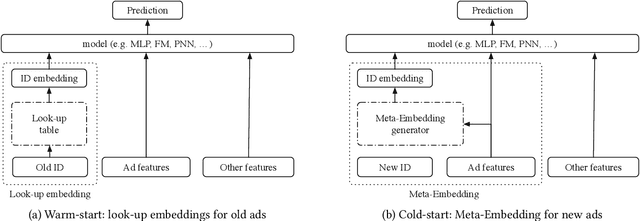
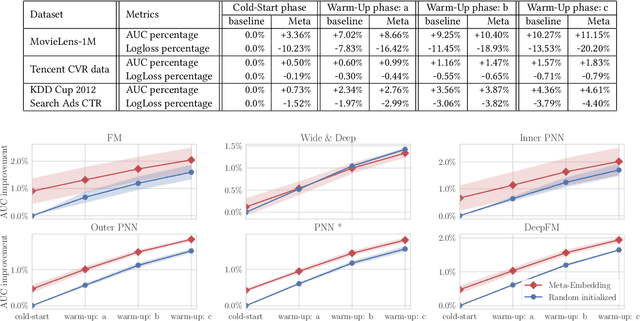
Click-through rate (CTR) prediction has been one of the most central problems in computational advertising. Lately, embedding techniques that produce low-dimensional representations of ad IDs drastically improve CTR prediction accuracies. However, such learning techniques are data demanding and work poorly on new ads with little logging data, which is known as the cold-start problem. In this paper, we aim to improve CTR predictions during both the cold-start phase and the warm-up phase when a new ad is added to the candidate pool. We propose Meta-Embedding, a meta-learning-based approach that learns to generate desirable initial embeddings for new ad IDs. The proposed method trains an embedding generator for new ad IDs by making use of previously learned ads through gradient-based meta-learning. In other words, our method learns how to learn better embeddings. When a new ad comes, the trained generator initializes the embedding of its ID by feeding its contents and attributes. Next, the generated embedding can speed up the model fitting during the warm-up phase when a few labeled examples are available, compared to the existing initialization methods. Experimental results on three real-world datasets showed that Meta-Embedding can significantly improve both the cold-start and warm-up performances for six existing CTR prediction models, ranging from lightweight models such as Factorization Machines to complicated deep models such as PNN and DeepFM. All of the above apply to conversion rate (CVR) predictions as well.