 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRankJudge: A Multi-Turn LLM-as-a-Judge Synthetic Benchmark Generator
May 20, 2026As interactive LLM-based applications are created and refined, model developers need to evaluate the quality of generated text along many possible axes. For simpler systems, human evaluation may be practical, but in complicated systems like conversational chatbots, the amount of generated text can overwhelm human annotation resources. Model developers have begun to rely heavily on auto-evaluation, where LLMs are also used to judge generation quality. However, existing LLM-as-a-judge benchmarks largely focus on simple Q\&A tasks that do not match the complexity of multi-turn conversations. We introduce RankJudge, a benchmark generator for evaluating LLM-as-a-judge on multi-turn conversations grounded in reference documents. RankJudge creates pairs of conversations where one conversation has a single flaw injected into one turn. This construction allows paired conversations to be labeled unambiguously as better or worse, and precisely isolates failure categories to individual turns, enabling a strict joint correctness criterion for judging. We implement RankJudge across the domains of machine learning, biomedicine, and finance, evaluate 21 frontier LLM judges, and rank those judges via the Bradley-Terry model. Our formulation also allows ranking each conversation pair with difficulty ratings, which we use to dynamically curate the evaluation slice to reduce label noise, as confirmed via human annotation. We find that judge rankings are stable under partial observability, coarser correctness criteria, and an alternative random-walk rating algorithm.
Chessformer: A Unified Architecture for Chess Modeling
May 18, 2026Chess has long served as a canonical testbed for artificial intelligence, but modeling approaches for its central tasks have diverged. Maximizing playing strength, predicting human play, and enabling interpretability are typically solved with disparate architectures, and these designs are often misaligned with the geometry of the domain. This raises the natural question of whether these objectives require separate modeling paradigms, or if there exists a single architecture that supports them simultaneously. We introduce Chessformer, a unified architecture that advances the state of the art on all three central goals in chess modeling. Chessformer is an encoder-only transformer that represents board squares as tokens, augments self-attention with a novel dynamic positional encoding called Geometric Attention Bias (GAB) that adapts to domain-specific geometry, and predicts actions with an attention-based source-destination policy head. We evaluate Chessformer on each front. First, we develop \maiathree, a family of models for human move prediction that reaches 57.1\% move-matching accuracy, significantly surpassing the previous state of the art with fewer than a quarter of the parameters. Second, we integrate Chessformer into Leela Chess Zero, a leading open-source engine, adding over 100 Elo of playing strength and resulting in tournament victories over Stockfish in major computer chess competitions. Third, we show that Chessformer's square-token design makes attention patterns and activations directly attributable to board squares, enabling granular interpretability analyses that prior architectures do not naturally support. More broadly, our results demonstrate that aligning a model's tokenization, positional encoding, and output design with the underlying structure of a domain can yield simultaneous gains in performance, human compatibility, and interpretability.
MINER: Mining Multimodal Internal Representation for Efficient Retrieval
May 07, 2026Visual document retrieval has become essential for accessing information in visually rich documents. Existing approaches fall into two camps. Late-interaction retrievers achieve strong quality through fine-grained token-level matching but store hundreds of vectors per page, incurring large index footprints and high serving costs. By contrast, dense single-vector retrievers retain storage and latency advantages but consistently lag in quality because they compress all information into a single final-layer embedding. In this work, we first conduct a layerwise diagnostic on single-vector retrievers, revealing that retrieval-relevant signal resides in internal representations. Motivated by these findings, we propose MINER (Mining Multimodal Internal RepreseNtation for Efficient Retrieval), a lightweight plug-in module that probes and fuses internal signals across transformer layers into a single compact embedding without modifying the backbone or sacrificing single-vector efficiency. The first Retrieval-Aligned Layer Probing stage attaches a lightweight probe at each layer, surfacing which dimensions carry retrieval-relevant information. The subsequent Adaptive Sparse Multi-Layer Fusion stage applies performance-adaptive neuron-level masking to the selected layers and fuses the surviving signals into the final dense vector. Across ViDoRe V1/V2/V3, MINER outperforms existing dense single-vector retrievers on the majority of benchmarks, with up to 4.5% nDCG@5 improvement over its corresponding backbone. Compared to strong late-interaction baselines, in some settings MINER substantially narrows the nDCG@$5$ gap to $0.2$ while preserving the storage and serving advantages of dense retrieval.
LLM Safety From Within: Detecting Harmful Content with Internal Representations
Apr 20, 2026Guard models are widely used to detect harmful content in user prompts and LLM responses. However, state-of-the-art guard models rely solely on terminal-layer representations and overlook the rich safety-relevant features distributed across internal layers. We present SIREN, a lightweight guard model that harnesses these internal features. By identifying safety neurons via linear probing and combining them through an adaptive layer-weighted strategy, SIREN builds a harmfulness detector from LLM internals without modifying the underlying model. Our comprehensive evaluation shows that SIREN substantially outperforms state-of-the-art open-source guard models across multiple benchmarks while using 250 times fewer trainable parameters. Moreover, SIREN exhibits superior generalization to unseen benchmarks, naturally enables real-time streaming detection, and significantly improves inference efficiency compared to generative guard models. Overall, our results highlight LLM internal states as a promising foundation for practical, high-performance harmfulness detection.
ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
Apr 02, 2026We introduce ThinkTwice, a simple two-phase framework that jointly optimizes LLMs to solve reasoning problems and refine the answers, based on Group Relative Policy Optimization (GRPO). In each pair of training steps, ThinkTwice first optimizes the model on solving reasoning problems, then optimizes it on refining its own solutions to the same problems, using the same binary correctness reward in both phases without correctness signals or critique annotations. Across five mathematical reasoning benchmarks and two model families including Qwen3-4B and Olmo3-7B, ThinkTwice substantially improves both reasoning and refinement performance over competitive online policy optimization baselines. Specifically, on Qwen3-4B, ThinkTwice outperforms GRPO on AIME by 5 percentage points before refinement and by 11.5 points after one self-refinement step, measured by pass@4. Analysis of the training dynamics of ThinkTwice reveals an implicit rectify-then-fortify curriculum: refinement predominantly corrects errors early in training and naturally shifts toward preserving already-correct solutions as the model improves, yielding a more rectified reward signal. Our work establishes joint training of reasoning and self-refinement as a principled and effective methodology for RLVR.
Grounded Chess Reasoning in Language Models via Master Distillation
Mar 20, 2026Language models often lack grounded reasoning capabilities in specialized domains where training data is scarce but bespoke systems excel. We introduce a general framework for distilling expert system reasoning into natural language chain-of-thought explanations, enabling compact models to acquire domain expertise and the ability to generate faithful, grounded explanations. Rather than distilling only final outputs, we capture the full reasoning process, transforming opaque expert computations into transparent, step-by-step explanations. We demonstrate this approach in chess, a canonical reasoning domain where language models continue to underperform. Our 4B parameter model, C1, advances from a near-zero baseline to 48.1% accuracy, outperforming all open-source models and most frontier proprietary systems. Notably, C1 surpasses its distillation teacher and generates solutions in two orders of magnitude fewer tokens than baselines. Unlike prior neural chess approaches that predict only best moves, C1 generates explainable solutions revealing strategic reasoning. Our pipeline combines supervised fine-tuning and reinforcement learning with theme-balanced data sampling for comprehensive tactical coverage. Master Distillation demonstrates how to inject expert-level knowledge into compact models for under-optimized domains, offering a recipe for unlocking RLVR where LLMs lack sufficient base capabilities.
Level Up: Defining and Exploiting Transitional Problems for Curriculum Learning
Mar 14, 2026Curriculum learning--ordering training examples in a sequence to aid machine learning--takes inspiration from human learning, but has not gained widespread acceptance. Static strategies for scoring item difficulty rely on indirect proxy scores of varying quality and produce curricula that are not specific to the learner at hand. Dynamic approaches base difficulty estimates on gradient information, requiring considerable extra computation during training. We introduce a novel method for measuring the difficulty of individual problem instances directly relative to the ability of a given model, and identify transitional problems that are consistently easier as model ability increases. Applying this method to chess and mathematics, we find that training on a curriculum that "levels up" from easier to harder transitional problems most efficiently improves a model to the next tier of competence. These problems induce a natural progression from easier to harder items, which outperforms other training strategies. By measuring difficulty directly relative to model competence, our method yields interpretable problems, learner-specific curricula, and a principled basis for step-by-step improvement.
SEAM: Semantically Equivalent Across Modalities Benchmark for Vision-Language Models
Aug 25, 2025Evaluating whether vision-language models (VLMs) reason consistently across representations is challenging because modality comparisons are typically confounded by task differences and asymmetric information. We introduce SEAM, a benchmark that pairs semantically equivalent inputs across four domains that have existing standardized textual and visual notations. By employing distinct notation systems across modalities, in contrast to OCR-based image-text pairing, SEAM provides a rigorous comparative assessment of the textual-symbolic and visual-spatial reasoning capabilities of VLMs. Across 21 contemporary models, we observe systematic modality imbalance: vision frequently lags language in overall performance, despite the problems containing semantically equivalent information, and cross-modal agreement is relatively low. Our error analysis reveals two main drivers: textual perception failures from tokenization in domain notation and visual perception failures that induce hallucinations. We also show that our results are largely robust to visual transformations. SEAM establishes a controlled, semantically equivalent setting for measuring and improving modality-agnostic reasoning.
Maia-2: A Unified Model for Human-AI Alignment in Chess
Sep 30, 2024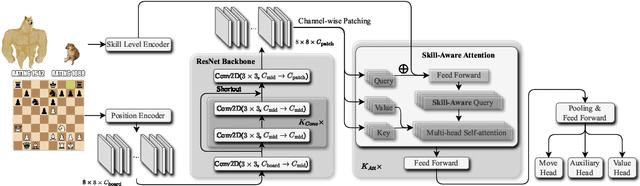
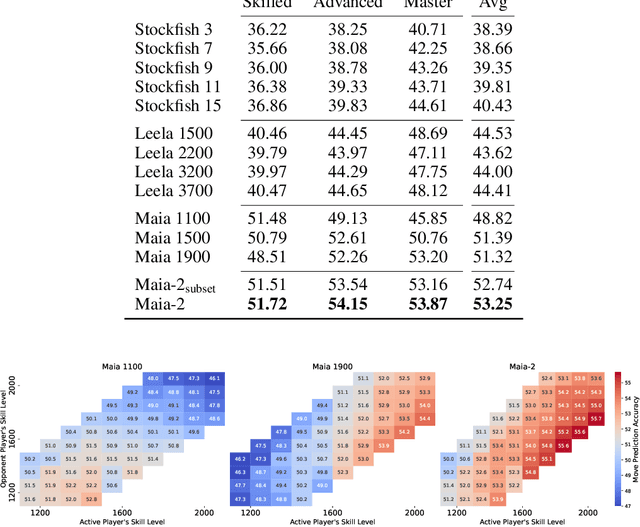
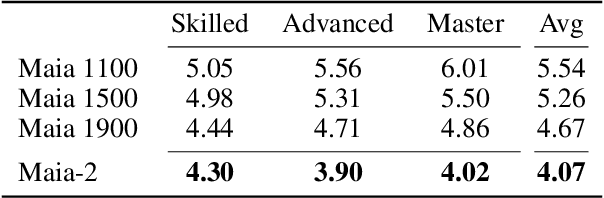
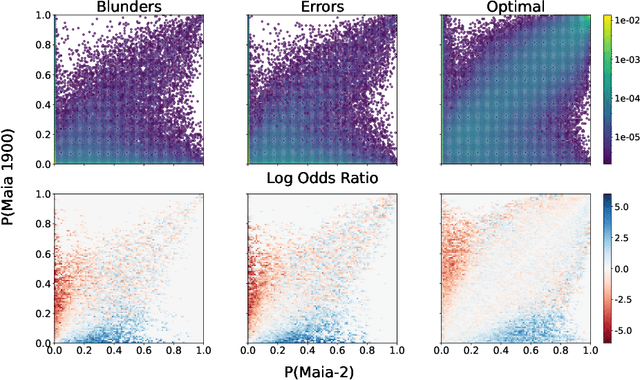
There are an increasing number of domains in which artificial intelligence (AI) systems both surpass human ability and accurately model human behavior. This introduces the possibility of algorithmically-informed teaching in these domains through more relatable AI partners and deeper insights into human decision-making. Critical to achieving this goal, however, is coherently modeling human behavior at various skill levels. Chess is an ideal model system for conducting research into this kind of human-AI alignment, with its rich history as a pivotal testbed for AI research, mature superhuman AI systems like AlphaZero, and precise measurements of skill via chess rating systems. Previous work in modeling human decision-making in chess uses completely independent models to capture human style at different skill levels, meaning they lack coherence in their ability to adapt to the full spectrum of human improvement and are ultimately limited in their effectiveness as AI partners and teaching tools. In this work, we propose a unified modeling approach for human-AI alignment in chess that coherently captures human style across different skill levels and directly captures how people improve. Recognizing the complex, non-linear nature of human learning, we introduce a skill-aware attention mechanism to dynamically integrate players' strengths with encoded chess positions, enabling our model to be sensitive to evolving player skill. Our experimental results demonstrate that this unified framework significantly enhances the alignment between AI and human players across a diverse range of expertise levels, paving the way for deeper insights into human decision-making and AI-guided teaching tools.
DiffuDetox: A Mixed Diffusion Model for Text Detoxification
Jun 14, 2023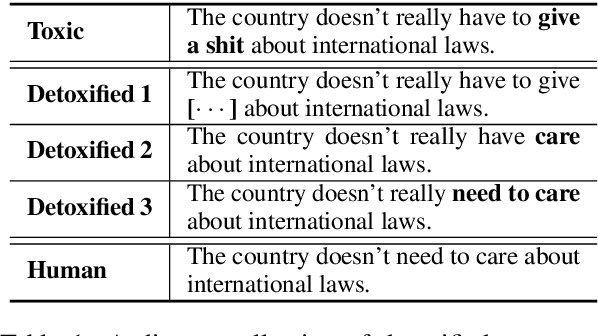
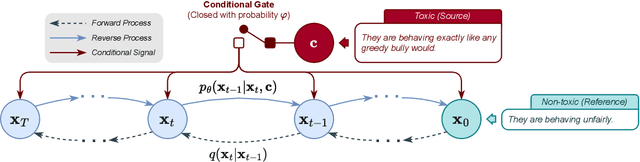
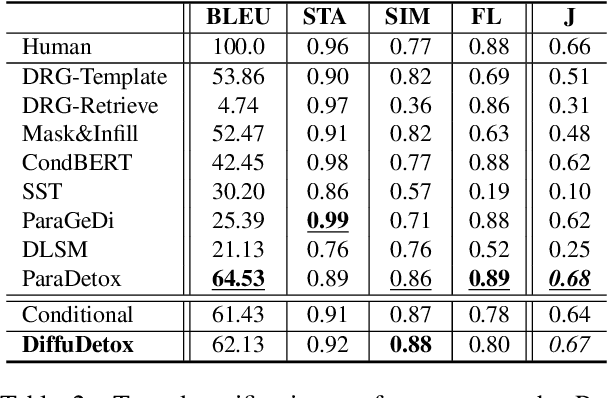
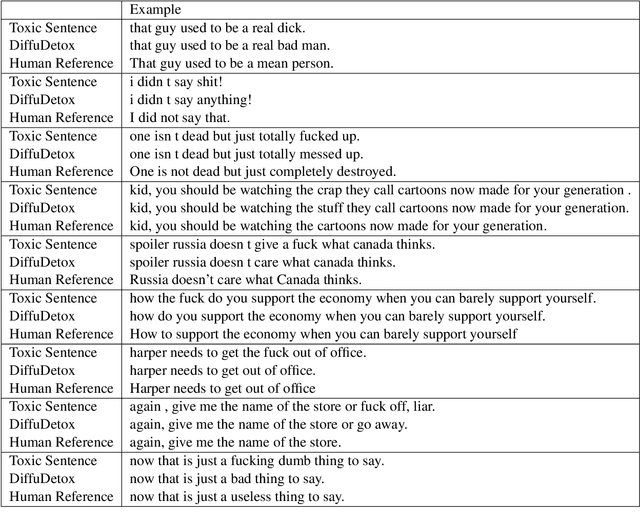
Text detoxification is a conditional text generation task aiming to remove offensive content from toxic text. It is highly useful for online forums and social media, where offensive content is frequently encountered. Intuitively, there are diverse ways to detoxify sentences while preserving their meanings, and we can select from detoxified sentences before displaying text to users. Conditional diffusion models are particularly suitable for this task given their demonstrated higher generative diversity than existing conditional text generation models based on language models. Nonetheless, text fluency declines when they are trained with insufficient data, which is the case for this task. In this work, we propose DiffuDetox, a mixed conditional and unconditional diffusion model for text detoxification. The conditional model takes toxic text as the condition and reduces its toxicity, yielding a diverse set of detoxified sentences. The unconditional model is trained to recover the input text, which allows the introduction of additional fluent text for training and thus ensures text fluency. Extensive experimental results and in-depth analysis demonstrate the effectiveness of our proposed DiffuDetox.