 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAM: Semantically Equivalent Across Modalities Benchmark for Vision-Language Models
Aug 25, 2025Evaluating whether vision-language models (VLMs) reason consistently across representations is challenging because modality comparisons are typically confounded by task differences and asymmetric information. We introduce SEAM, a benchmark that pairs semantically equivalent inputs across four domains that have existing standardized textual and visual notations. By employing distinct notation systems across modalities, in contrast to OCR-based image-text pairing, SEAM provides a rigorous comparative assessment of the textual-symbolic and visual-spatial reasoning capabilities of VLMs. Across 21 contemporary models, we observe systematic modality imbalance: vision frequently lags language in overall performance, despite the problems containing semantically equivalent information, and cross-modal agreement is relatively low. Our error analysis reveals two main drivers: textual perception failures from tokenization in domain notation and visual perception failures that induce hallucinations. We also show that our results are largely robust to visual transformations. SEAM establishes a controlled, semantically equivalent setting for measuring and improving modality-agnostic reasoning.
Maia-2: A Unified Model for Human-AI Alignment in Chess
Sep 30, 2024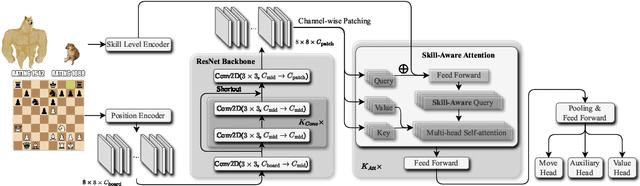
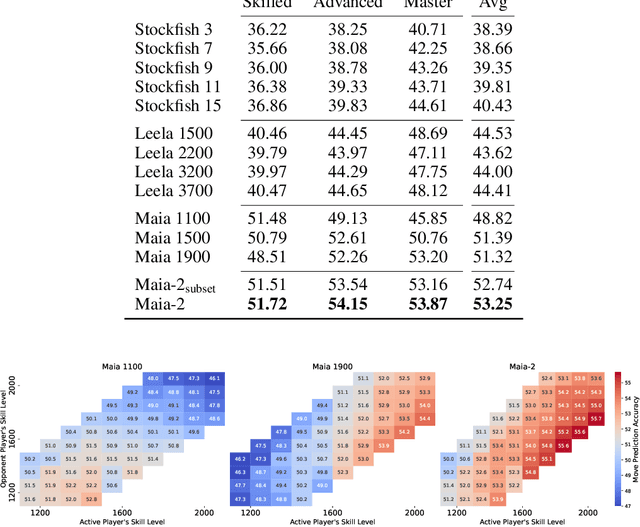
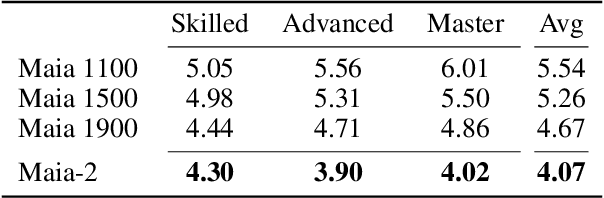
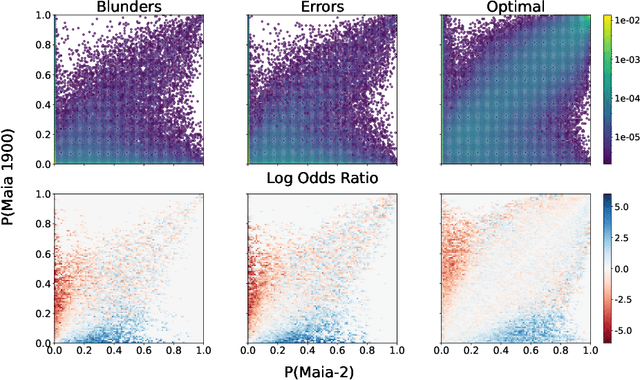
There are an increasing number of domains in which artificial intelligence (AI) systems both surpass human ability and accurately model human behavior. This introduces the possibility of algorithmically-informed teaching in these domains through more relatable AI partners and deeper insights into human decision-making. Critical to achieving this goal, however, is coherently modeling human behavior at various skill levels. Chess is an ideal model system for conducting research into this kind of human-AI alignment, with its rich history as a pivotal testbed for AI research, mature superhuman AI systems like AlphaZero, and precise measurements of skill via chess rating systems. Previous work in modeling human decision-making in chess uses completely independent models to capture human style at different skill levels, meaning they lack coherence in their ability to adapt to the full spectrum of human improvement and are ultimately limited in their effectiveness as AI partners and teaching tools. In this work, we propose a unified modeling approach for human-AI alignment in chess that coherently captures human style across different skill levels and directly captures how people improve. Recognizing the complex, non-linear nature of human learning, we introduce a skill-aware attention mechanism to dynamically integrate players' strengths with encoded chess positions, enabling our model to be sensitive to evolving player skill. Our experimental results demonstrate that this unified framework significantly enhances the alignment between AI and human players across a diverse range of expertise levels, paving the way for deeper insights into human decision-making and AI-guided teaching tools.
Sparsify-then-Classify: From Internal Neurons of Large Language Models To Efficient Text Classifiers
Nov 27, 2023Among the many tasks that Large Language Models (LLMs) have revolutionized is text classification. However, existing approaches for applying pretrained LLMs to text classification predominantly rely on using single token outputs from only the last layer of hidden states. As a result, they suffer from limitations in efficiency, task-specificity, and interpretability. In our work, we contribute an approach that uses all internal representations by employing multiple pooling strategies on all activation and hidden states. Our novel lightweight strategy, Sparsify-then-Classify (STC) first sparsifies task-specific features layer-by-layer, then aggregates across layers for text classification. STC can be applied as a seamless plug-and-play module on top of existing LLMs. Our experiments on a comprehensive set of models and datasets demonstrate that STC not only consistently improves the classification performance of pretrained and fine-tuned models, but is also more efficient for both training and inference, and is more intrinsically interpretable.