 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Many Features Can a Language Model Store Under the Linear Representation Hypothesis?
Feb 11, 2026We introduce a mathematical framework for the linear representation hypothesis (LRH), which asserts that intermediate layers of language models store features linearly. We separate the hypothesis into two claims: linear representation (features are linearly embedded in neuron activations) and linear accessibility (features can be linearly decoded). We then ask: How many neurons $d$ suffice to both linearly represent and linearly access $m$ features? Classical results in compressed sensing imply that for $k$-sparse inputs, $d = O(k\log (m/k))$ suffices if we allow non-linear decoding algorithms (Candes and Tao, 2006; Candes et al., 2006; Donoho, 2006). However, the additional requirement of linear decoding takes the problem out of the classical compressed sensing, into linear compressed sensing. Our main theoretical result establishes nearly-matching upper and lower bounds for linear compressed sensing. We prove that $d = Ω_ε(\frac{k^2}{\log k}\log (m/k))$ is required while $d = O_ε(k^2\log m)$ suffices. The lower bound establishes a quantitative gap between classical and linear compressed setting, illustrating how linear accessibility is a meaningfully stronger hypothesis than linear representation alone. The upper bound confirms that neurons can store an exponential number of features under the LRH, giving theoretical evidence for the "superposition hypothesis" (Elhage et al., 2022). The upper bound proof uses standard random constructions of matrices with approximately orthogonal columns. The lower bound proof uses rank bounds for near-identity matrices (Alon, 2003) together with Turán's theorem (bounding the number of edges in clique-free graphs). We also show how our results do and do not constrain the geometry of feature representations and extend our results to allow decoders with an activation function and bias.
Language Generation and Identification From Partial Enumeration: Tight Density Bounds and Topological Characterizations
Nov 07, 2025The success of large language models (LLMs) has motivated formal theories of language generation and learning. We study the framework of \emph{language generation in the limit}, where an adversary enumerates strings from an unknown language $K$ drawn from a countable class, and an algorithm must generate unseen strings from $K$. Prior work showed that generation is always possible, and that some algorithms achieve positive lower density, revealing a \emph{validity--breadth} trade-off between correctness and coverage. We resolve a main open question in this line, proving a tight bound of $1/2$ on the best achievable lower density. We then strengthen the model to allow \emph{partial enumeration}, where the adversary reveals only an infinite subset $C \subseteq K$. We show that generation in the limit remains achievable, and if $C$ has lower density $α$ in $K$, the algorithm's output achieves density at least $α/2$, matching the upper bound. This generalizes the $1/2$ bound to the partial-information setting, where the generator must recover within a factor $1/2$ of the revealed subset's density. We further revisit the classical Gold--Angluin model of \emph{language identification} under partial enumeration. We characterize when identification in the limit is possible -- when hypotheses $M_t$ eventually satisfy $C \subseteq M \subseteq K$ -- and in the process give a new topological formulation of Angluin's characterization, showing that her condition is precisely equivalent to an appropriate topological space having the $T_D$ separation property.
Density Measures for Language Generation
Apr 19, 2025
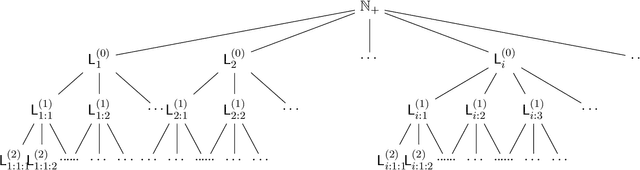
The recent successes of large language models (LLMs) have led to a surge of theoretical research into language generation. A recent line of work proposes an abstract view, called language generation in the limit, where generation is seen as a game between an adversary and an algorithm: the adversary generates strings from an unknown language $K$, chosen from a countable collection of candidate languages, and after seeing a finite set of these strings, the algorithm must generate new strings from $K$ that it has not seen before. This formalism highlights a key tension: the trade-off between validity (the algorithm should only produce strings from the language) and breadth (it should be able to produce many strings from the language). This trade-off is central in applied language generation as well, where it appears as a balance between hallucination (generating invalid utterances) and mode collapse (generating only a restricted set of outputs). Despite its importance, this trade-off has been challenging to study quantitatively. We develop ways to quantify this trade-off by formalizing breadth using measures of density. Existing algorithms for language generation in the limit produce output sets that can have zero density in the true language, and this important failure of breadth might seem unavoidable. We show, however, that such a failure is not necessary: we provide an algorithm for language generation in the limit whose outputs have strictly positive density in $K$. We also study the internal representations built by these algorithms, specifically the sequence of hypothesized candidate languages they consider, and show that achieving the strongest form of breadth may require oscillating indefinitely between high- and low-density representations. Our analysis introduces a novel topology on language families, with notions of convergence and limit points playing a key role.
The Backfiring Effect of Weak AI Safety Regulation
Mar 26, 2025Recent policy proposals aim to improve the safety of general-purpose AI, but there is little understanding of the efficacy of different regulatory approaches to AI safety. We present a strategic model that explores the interactions between the regulator, the general-purpose AI technology creators, and domain specialists--those who adapt the AI for specific applications. Our analysis examines how different regulatory measures, targeting different parts of the development chain, affect the outcome of the development process. In particular, we assume AI technology is described by two key attributes: safety and performance. The regulator first sets a minimum safety standard that applies to one or both players, with strict penalties for non-compliance. The general-purpose creator then develops the technology, establishing its initial safety and performance levels. Next, domain specialists refine the AI for their specific use cases, and the resulting revenue is distributed between the specialist and generalist through an ex-ante bargaining process. Our analysis of this game reveals two key insights: First, weak safety regulation imposed only on the domain specialists can backfire. While it might seem logical to regulate use cases (as opposed to the general-purpose technology), our analysis shows that weak regulations targeting domain specialists alone can unintentionally reduce safety. This effect persists across a wide range of settings. Second, in sharp contrast to the previous finding, we observe that stronger, well-placed regulation can in fact benefit all players subjected to it. When regulators impose appropriate safety standards on both AI creators and domain specialists, the regulation functions as a commitment mechanism, leading to safety and performance gains, surpassing what is achieved under no regulation or regulating one player only.
AI-Assisted Decision Making with Human Learning
Feb 18, 2025AI systems increasingly support human decision-making. In many cases, despite the algorithm's superior performance, the final decision remains in human hands. For example, an AI may assist doctors in determining which diagnostic tests to run, but the doctor ultimately makes the diagnosis. This paper studies such AI-assisted decision-making settings, where the human learns through repeated interactions with the algorithm. In our framework, the algorithm -- designed to maximize decision accuracy according to its own model -- determines which features the human can consider. The human then makes a prediction based on their own less accurate model. We observe that the discrepancy between the algorithm's model and the human's model creates a fundamental tradeoff. Should the algorithm prioritize recommending more informative features, encouraging the human to recognize their importance, even if it results in less accurate predictions in the short term until learning occurs? Or is it preferable to forgo educating the human and instead select features that align more closely with their existing understanding, minimizing the immediate cost of learning? This tradeoff is shaped by the algorithm's time-discounted objective and the human's learning ability. Our results show that optimal feature selection has a surprisingly clean combinatorial characterization, reducible to a stationary sequence of feature subsets that is tractable to compute. As the algorithm becomes more "patient" or the human's learning improves, the algorithm increasingly selects more informative features, enhancing both prediction accuracy and the human's understanding. Notably, early investment in learning leads to the selection of more informative features than a later investment. We complement our analysis by showing that the impact of errors in the algorithm's knowledge is limited as it does not make the prediction directly.
Sparse Autoencoders for Hypothesis Generation
Feb 05, 2025



We describe HypotheSAEs, a general method to hypothesize interpretable relationships between text data (e.g., headlines) and a target variable (e.g., clicks). HypotheSAEs has three steps: (1) train a sparse autoencoder on text embeddings to produce interpretable features describing the data distribution, (2) select features that predict the target variable, and (3) generate a natural language interpretation of each feature (e.g., "mentions being surprised or shocked") using an LLM. Each interpretation serves as a hypothesis about what predicts the target variable. Compared to baselines, our method better identifies reference hypotheses on synthetic datasets (at least +0.06 in F1) and produces more predictive hypotheses on real datasets (~twice as many significant findings), despite requiring 1-2 orders of magnitude less compute than recent LLM-based methods. HypotheSAEs also produces novel discoveries on two well-studied tasks: explaining partisan differences in Congressional speeches and identifying drivers of engagement with online headlines.
A No Free Lunch Theorem for Human-AI Collaboration
Nov 21, 2024
The gold standard in human-AI collaboration is complementarity -- when combined performance exceeds both the human and algorithm alone. We investigate this challenge in binary classification settings where the goal is to maximize 0-1 accuracy. Given two or more agents who can make calibrated probabilistic predictions, we show a "No Free Lunch"-style result. Any deterministic collaboration strategy (a function mapping calibrated probabilities into binary classifications) that does not essentially always defer to the same agent will sometimes perform worse than the least accurate agent. In other words, complementarity cannot be achieved "for free." The result does suggest one model of collaboration with guarantees, where one agent identifies "obvious" errors of the other agent. We also use the result to understand the necessary conditions enabling the success of other collaboration techniques, providing guidance to human-AI collaboration.
Maia-2: A Unified Model for Human-AI Alignment in Chess
Sep 30, 2024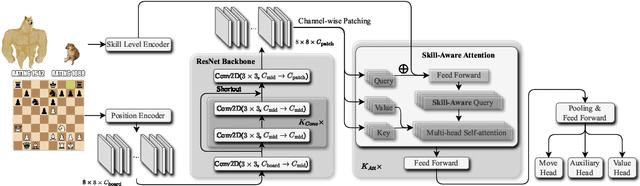
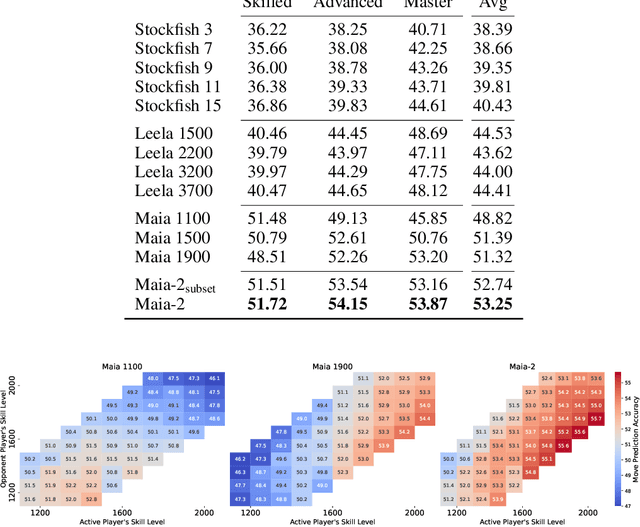
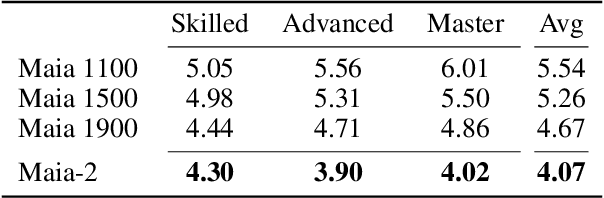
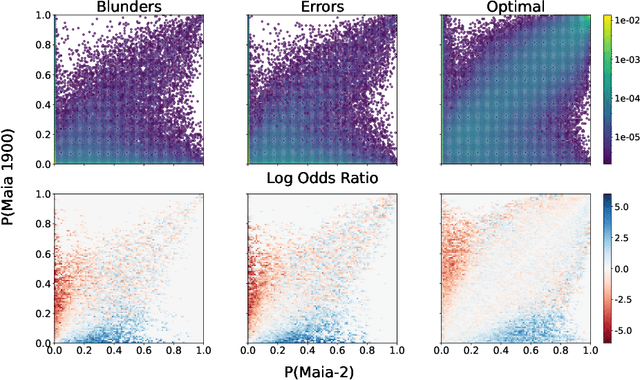
There are an increasing number of domains in which artificial intelligence (AI) systems both surpass human ability and accurately model human behavior. This introduces the possibility of algorithmically-informed teaching in these domains through more relatable AI partners and deeper insights into human decision-making. Critical to achieving this goal, however, is coherently modeling human behavior at various skill levels. Chess is an ideal model system for conducting research into this kind of human-AI alignment, with its rich history as a pivotal testbed for AI research, mature superhuman AI systems like AlphaZero, and precise measurements of skill via chess rating systems. Previous work in modeling human decision-making in chess uses completely independent models to capture human style at different skill levels, meaning they lack coherence in their ability to adapt to the full spectrum of human improvement and are ultimately limited in their effectiveness as AI partners and teaching tools. In this work, we propose a unified modeling approach for human-AI alignment in chess that coherently captures human style across different skill levels and directly captures how people improve. Recognizing the complex, non-linear nature of human learning, we introduce a skill-aware attention mechanism to dynamically integrate players' strengths with encoded chess positions, enabling our model to be sensitive to evolving player skill. Our experimental results demonstrate that this unified framework significantly enhances the alignment between AI and human players across a diverse range of expertise levels, paving the way for deeper insights into human decision-making and AI-guided teaching tools.
Evaluating the World Model Implicit in a Generative Model
Jun 06, 2024Recent work suggests that large language models may implicitly learn world models. How should we assess this possibility? We formalize this question for the case where the underlying reality is governed by a deterministic finite automaton. This includes problems as diverse as simple logical reasoning, geographic navigation, game-playing, and chemistry. We propose new evaluation metrics for world model recovery inspired by the classic Myhill-Nerode theorem from language theory. We illustrate their utility in three domains: game playing, logic puzzles, and navigation. In all domains, the generative models we consider do well on existing diagnostics for assessing world models, but our evaluation metrics reveal their world models to be far less coherent than they appear. Such incoherence creates fragility: using a generative model to solve related but subtly different tasks can lead it to fail badly. Building generative models that meaningfully capture the underlying logic of the domains they model would be immensely valuable; our results suggest new ways to assess how close a given model is to that goal.
How Random is Random? Evaluating the Randomness and Humaness of LLMs' Coin Flips
May 31, 2024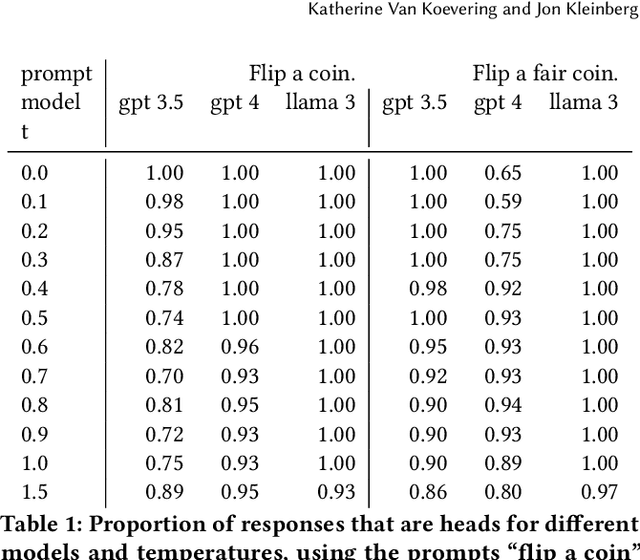
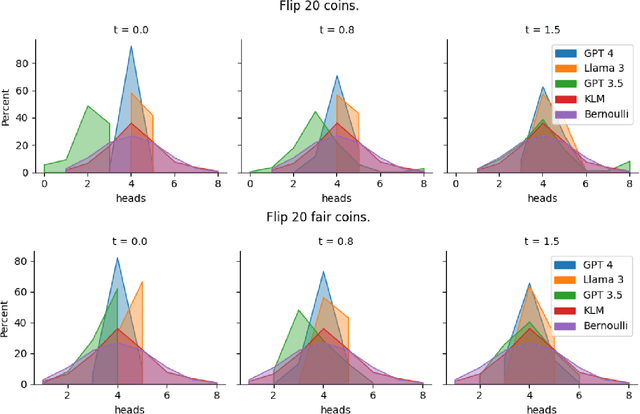

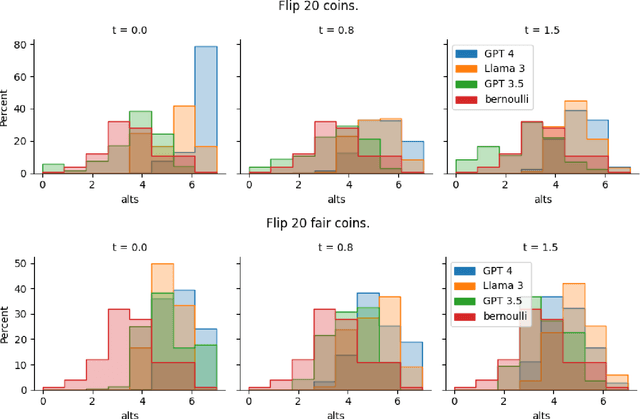
One uniquely human trait is our inability to be random. We see and produce patterns where there should not be any and we do so in a predictable way. LLMs are supplied with human data and prone to human biases. In this work, we explore how LLMs approach randomness and where and how they fail through the lens of the well studied phenomena of generating binary random sequences. We find that GPT 4 and Llama 3 exhibit and exacerbate nearly every human bias we test in this context, but GPT 3.5 exhibits more random behavior. This dichotomy of randomness or humaness is proposed as a fundamental question of LLMs and that either behavior may be useful in different circumstances.