 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's In My Human Feedback? Learning Interpretable Descriptions of Preference Data
Oct 30, 2025Human feedback can alter language models in unpredictable and undesirable ways, as practitioners lack a clear understanding of what feedback data encodes. While prior work studies preferences over certain attributes (e.g., length or sycophancy), automatically extracting relevant features without pre-specifying hypotheses remains challenging. We introduce What's In My Human Feedback? (WIMHF), a method to explain feedback data using sparse autoencoders. WIMHF characterizes both (1) the preferences a dataset is capable of measuring and (2) the preferences that the annotators actually express. Across 7 datasets, WIMHF identifies a small number of human-interpretable features that account for the majority of the preference prediction signal achieved by black-box models. These features reveal a wide diversity in what humans prefer, and the role of dataset-level context: for example, users on Reddit prefer informality and jokes, while annotators in HH-RLHF and PRISM disprefer them. WIMHF also surfaces potentially unsafe preferences, such as that LMArena users tend to vote against refusals, often in favor of toxic content. The learned features enable effective data curation: re-labeling the harmful examples in Arena yields large safety gains (+37%) with no cost to general performance. They also allow fine-grained personalization: on the Community Alignment dataset, we learn annotator-specific weights over subjective features that improve preference prediction. WIMHF provides a human-centered analysis method for practitioners to better understand and use preference data.
Sparse Autoencoders for Hypothesis Generation
Feb 05, 2025



We describe HypotheSAEs, a general method to hypothesize interpretable relationships between text data (e.g., headlines) and a target variable (e.g., clicks). HypotheSAEs has three steps: (1) train a sparse autoencoder on text embeddings to produce interpretable features describing the data distribution, (2) select features that predict the target variable, and (3) generate a natural language interpretation of each feature (e.g., "mentions being surprised or shocked") using an LLM. Each interpretation serves as a hypothesis about what predicts the target variable. Compared to baselines, our method better identifies reference hypotheses on synthetic datasets (at least +0.06 in F1) and produces more predictive hypotheses on real datasets (~twice as many significant findings), despite requiring 1-2 orders of magnitude less compute than recent LLM-based methods. HypotheSAEs also produces novel discoveries on two well-studied tasks: explaining partisan differences in Congressional speeches and identifying drivers of engagement with online headlines.
Generative AI in Medicine
Dec 13, 2024

The increased capabilities of generative AI have dramatically expanded its possible use cases in medicine. We provide a comprehensive overview of generative AI use cases for clinicians, patients, clinical trial organizers, researchers, and trainees. We then discuss the many challenges -- including maintaining privacy and security, improving transparency and interpretability, upholding equity, and rigorously evaluating models -- which must be overcome to realize this potential, and the open research directions they give rise to.
Annotation alignment: Comparing LLM and human annotations of conversational safety
Jun 10, 2024

To what extent to do LLMs align with human perceptions of safety? We study this question via *annotation alignment*, the extent to which LLMs and humans agree when annotating the safety of user-chatbot conversations. We leverage the recent DICES dataset (Aroyo et al., 2023), in which 350 conversations are each rated for safety by 112 annotators spanning 10 race-gender groups. GPT-4 achieves a Pearson correlation of $r = 0.59$ with the average annotator rating, higher than the median annotator's correlation with the average ($r=0.51$). We show that larger datasets are needed to resolve whether GPT-4 exhibits disparities in how well it correlates with demographic groups. Also, there is substantial idiosyncratic variation in correlation *within* groups, suggesting that race & gender do not fully capture differences in alignment. Finally, we find that GPT-4 cannot predict when one demographic group finds a conversation more unsafe than another.
Large language models shape and are shaped by society: A survey of arXiv publication patterns
Jul 20, 2023There has been a steep recent increase in the number of large language model (LLM) papers, producing a dramatic shift in the scientific landscape which remains largely undocumented through bibliometric analysis. Here, we analyze 388K papers posted on the CS and Stat arXivs, focusing on changes in publication patterns in 2023 vs. 2018-2022. We analyze how the proportion of LLM papers is increasing; the LLM-related topics receiving the most attention; the authors writing LLM papers; how authors' research topics correlate with their backgrounds; the factors distinguishing highly cited LLM papers; and the patterns of international collaboration. We show that LLM research increasingly focuses on societal impacts: there has been an 18x increase in the proportion of LLM-related papers on the Computers and Society sub-arXiv, and authors newly publishing on LLMs are more likely to focus on applications and societal impacts than more experienced authors. LLM research is also shaped by social dynamics: we document gender and academic/industry disparities in the topics LLM authors focus on, and a US/China schism in the collaboration network. Overall, our analysis documents the profound ways in which LLM research both shapes and is shaped by society, attesting to the necessity of sociotechnical lenses.
Coarse race data conceals disparities in clinical risk score performance
Apr 18, 2023



Healthcare data in the United States often records only a patient's coarse race group: for example, both Indian and Chinese patients are typically coded as ``Asian.'' It is unknown, however, whether this coarse coding conceals meaningful disparities in the performance of clinical risk scores across granular race groups. Here we show that it does. Using data from 418K emergency department visits, we assess clinical risk score performance disparities across granular race groups for three outcomes, five risk scores, and four performance metrics. Across outcomes and metrics, we show that there are significant granular disparities in performance within coarse race categories. In fact, variation in performance metrics within coarse groups often exceeds the variation between coarse groups. We explore why these disparities arise, finding that outcome rates, feature distributions, and the relationships between features and outcomes all vary significantly across granular race categories. Our results suggest that healthcare providers, hospital systems, and machine learning researchers should strive to collect, release, and use granular race data in place of coarse race data, and that existing analyses may significantly underestimate racial disparities in performance.
Combining Compressions for Multiplicative Size Scaling on Natural Language Tasks
Aug 20, 2022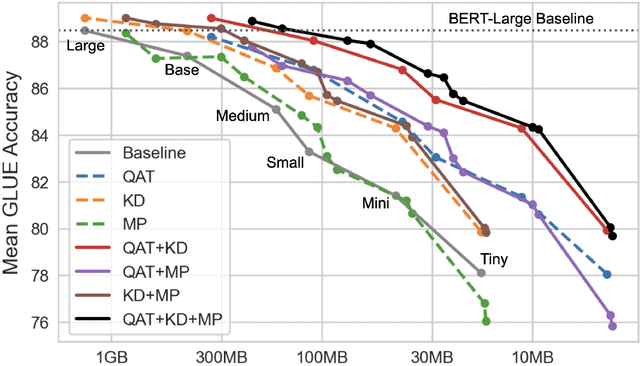
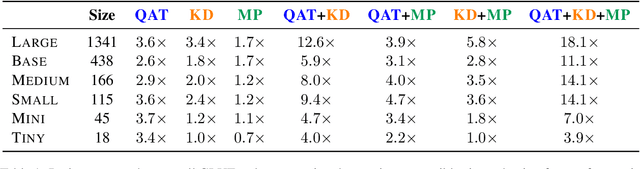
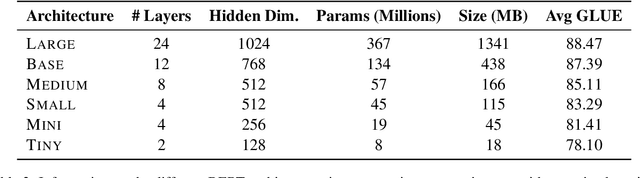
Quantization, knowledge distillation, and magnitude pruning are among the most popular methods for neural network compression in NLP. Independently, these methods reduce model size and can accelerate inference, but their relative benefit and combinatorial interactions have not been rigorously studied. For each of the eight possible subsets of these techniques, we compare accuracy vs. model size tradeoffs across six BERT architecture sizes and eight GLUE tasks. We find that quantization and distillation consistently provide greater benefit than pruning. Surprisingly, except for the pair of pruning and quantization, using multiple methods together rarely yields diminishing returns. Instead, we observe complementary and super-multiplicative reductions to model size. Our work quantitatively demonstrates that combining compression methods can synergistically reduce model size, and that practitioners should prioritize (1) quantization, (2) knowledge distillation, and (3) pruning to maximize accuracy vs. model size tradeoffs.
Studying the Consistency and Composability of Lottery Ticket Pruning Masks
Apr 30, 2021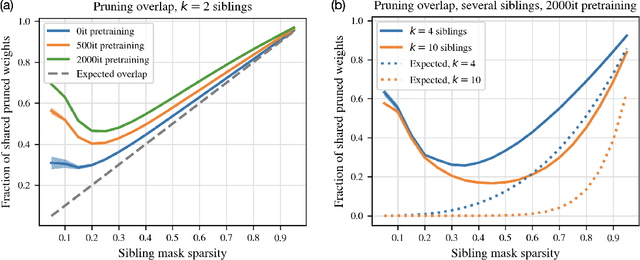

Magnitude pruning is a common, effective technique to identify sparse subnetworks at little cost to accuracy. In this work, we ask whether a particular architecture's accuracy-sparsity tradeoff can be improved by combining pruning information across multiple runs of training. From a shared ResNet-20 initialization, we train several network copies (\emph{siblings}) to completion using different SGD data orders on CIFAR-10. While the siblings' pruning masks are naively not much more similar than chance, starting sibling training after a few epochs of shared pretraining significantly increases pruning overlap. We then choose a subnetwork by either (1) taking all weights that survive pruning in any sibling (mask union), or (2) taking only the weights that survive pruning across all siblings (mask intersection). The resulting subnetwork is retrained. Strikingly, we find that union and intersection masks perform very similarly. Both methods match the accuracy-sparsity tradeoffs of the one-shot magnitude pruning baseline, even when we combine masks from up to $k = 10$ siblings.
Dissecting Lottery Ticket Transformers: Structural and Behavioral Study of Sparse Neural Machine Translation
Oct 12, 2020
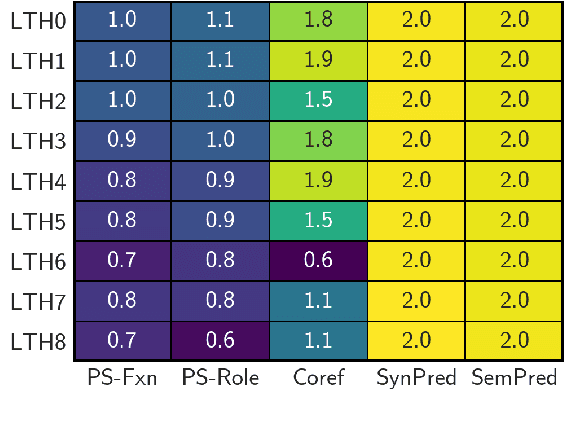
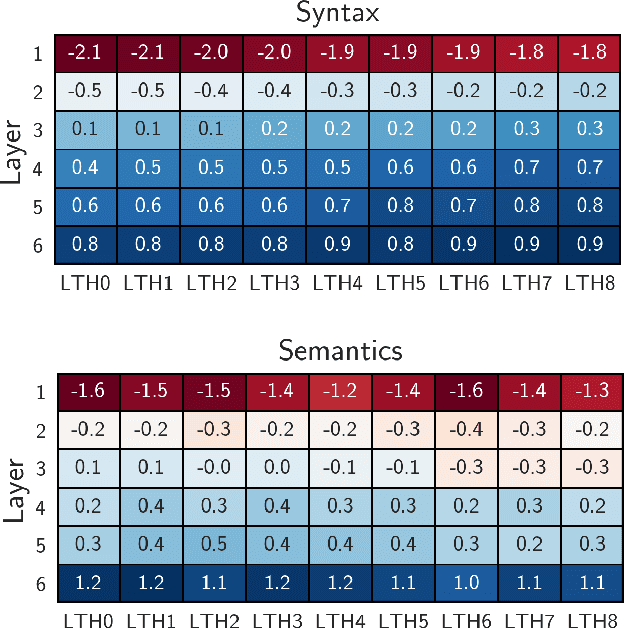

Recent work on the lottery ticket hypothesis has produced highly sparse Transformers for NMT while maintaining BLEU. However, it is unclear how such pruning techniques affect a model's learned representations. By probing Transformers with more and more low-magnitude weights pruned away, we find that complex semantic information is first to be degraded. Analysis of internal activations reveals that higher layers diverge most over the course of pruning, gradually becoming less complex than their dense counterparts. Meanwhile, early layers of sparse models begin to perform more encoding. Attention mechanisms remain remarkably consistent as sparsity increases.