Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Lottery Ticket Transformers: Structural and Behavioral Study of Sparse Neural Machine Translation
Paper and Code
Oct 12, 2020
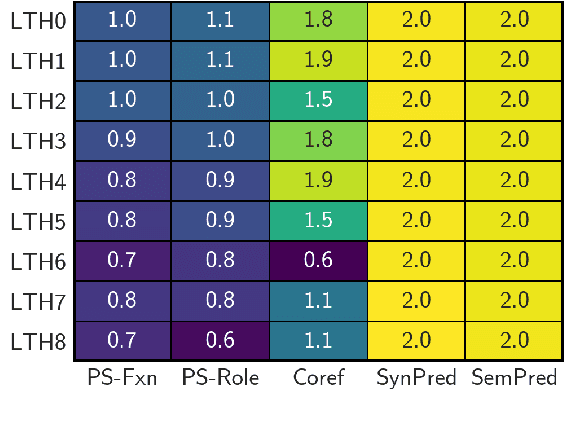
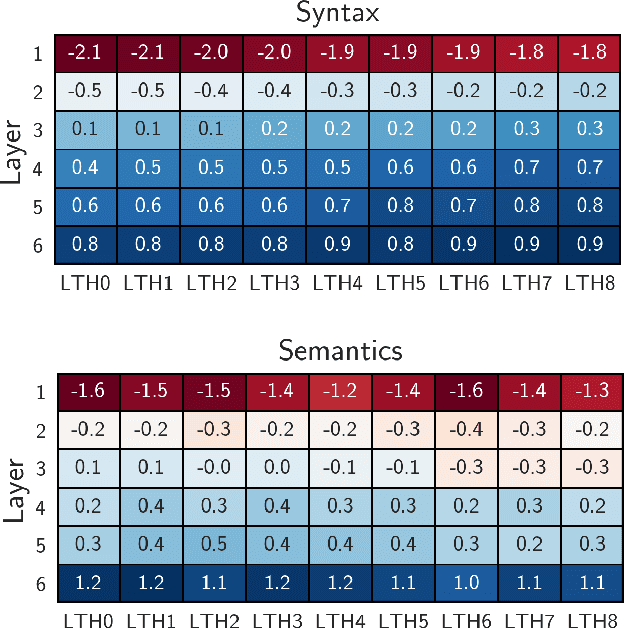

Recent work on the lottery ticket hypothesis has produced highly sparse Transformers for NMT while maintaining BLEU. However, it is unclear how such pruning techniques affect a model's learned representations. By probing Transformers with more and more low-magnitude weights pruned away, we find that complex semantic information is first to be degraded. Analysis of internal activations reveals that higher layers diverge most over the course of pruning, gradually becoming less complex than their dense counterparts. Meanwhile, early layers of sparse models begin to perform more encoding. Attention mechanisms remain remarkably consistent as sparsity increases.
* Camera-ready for BlackboxNLP @ EMNLP 2020
View paper on