 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time augmentation improves efficiency in conformal prediction
May 28, 2025A conformal classifier produces a set of predicted classes and provides a probabilistic guarantee that the set includes the true class. Unfortunately, it is often the case that conformal classifiers produce uninformatively large sets. In this work, we show that test-time augmentation (TTA)--a technique that introduces inductive biases during inference--reduces the size of the sets produced by conformal classifiers. Our approach is flexible, computationally efficient, and effective. It can be combined with any conformal score, requires no model retraining, and reduces prediction set sizes by 10%-14% on average. We conduct an evaluation of the approach spanning three datasets, three models, two established conformal scoring methods, different guarantee strengths, and several distribution shifts to show when and why test-time augmentation is a useful addition to the conformal pipeline.
Evaluating multiple models using labeled and unlabeled data
Jan 21, 2025



It remains difficult to evaluate machine learning classifiers in the absence of a large, labeled dataset. While labeled data can be prohibitively expensive or impossible to obtain, unlabeled data is plentiful. Here, we introduce Semi-Supervised Model Evaluation (SSME), a method that uses both labeled and unlabeled data to evaluate machine learning classifiers. SSME is the first evaluation method to take advantage of the fact that: (i) there are frequently multiple classifiers for the same task, (ii) continuous classifier scores are often available for all classes, and (iii) unlabeled data is often far more plentiful than labeled data. The key idea is to use a semi-supervised mixture model to estimate the joint distribution of ground truth labels and classifier predictions. We can then use this model to estimate any metric that is a function of classifier scores and ground truth labels (e.g., accuracy or expected calibration error). We present experiments in four domains where obtaining large labeled datasets is often impractical: (1) healthcare, (2) content moderation, (3) molecular property prediction, and (4) image annotation. Our results demonstrate that SSME estimates performance more accurately than do competing methods, reducing error by 5.1x relative to using labeled data alone and 2.4x relative to the next best competing method. SSME also improves accuracy when evaluating performance across subsets of the test distribution (e.g., specific demographic subgroups) and when evaluating the performance of language models.
Learning Disease Progression Models That Capture Health Disparities
Dec 20, 2024
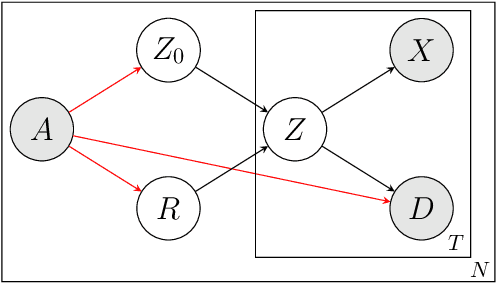
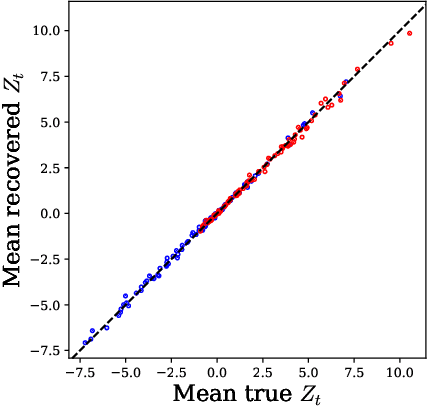
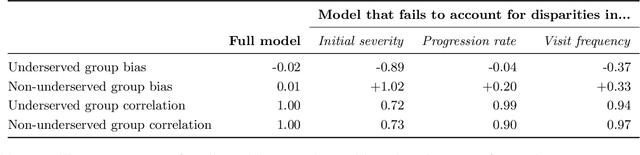
Disease progression models are widely used to inform the diagnosis and treatment of many progressive diseases. However, a significant limitation of existing models is that they do not account for health disparities that can bias the observed data. To address this, we develop an interpretable Bayesian disease progression model that captures three key health disparities: certain patient populations may (1) start receiving care only when their disease is more severe, (2) experience faster disease progression even while receiving care, or (3) receive follow-up care less frequently conditional on disease severity. We show theoretically and empirically that failing to account for disparities produces biased estimates of severity (underestimating severity for disadvantaged groups, for example). On a dataset of heart failure patients, we show that our model can identify groups that face each type of health disparity, and that accounting for these disparities meaningfully shifts which patients are considered high-risk.
Generative AI in Medicine
Dec 13, 2024

The increased capabilities of generative AI have dramatically expanded its possible use cases in medicine. We provide a comprehensive overview of generative AI use cases for clinicians, patients, clinical trial organizers, researchers, and trainees. We then discuss the many challenges -- including maintaining privacy and security, improving transparency and interpretability, upholding equity, and rigorously evaluating models -- which must be overcome to realize this potential, and the open research directions they give rise to.
Machine Learning for Health symposium 2023 -- Findings track
Dec 01, 2023A collection of the accepted Findings papers that were presented at the 3rd Machine Learning for Health symposium (ML4H 2023), which was held on December 10, 2023, in New Orleans, Louisiana, USA. ML4H 2023 invited high-quality submissions on relevant problems in a variety of health-related disciplines including healthcare, biomedicine, and public health. Two submission tracks were offered: the archival Proceedings track, and the non-archival Findings track. Proceedings were targeted at mature work with strong technical sophistication and a high impact to health. The Findings track looked for new ideas that could spark insightful discussion, serve as valuable resources for the community, or could enable new collaborations. Submissions to the Proceedings track, if not accepted, were automatically considered for the Findings track. All the manuscripts submitted to ML4H Symposium underwent a double-blind peer-review process.
Coarse race data conceals disparities in clinical risk score performance
Apr 18, 2023



Healthcare data in the United States often records only a patient's coarse race group: for example, both Indian and Chinese patients are typically coded as ``Asian.'' It is unknown, however, whether this coarse coding conceals meaningful disparities in the performance of clinical risk scores across granular race groups. Here we show that it does. Using data from 418K emergency department visits, we assess clinical risk score performance disparities across granular race groups for three outcomes, five risk scores, and four performance metrics. Across outcomes and metrics, we show that there are significant granular disparities in performance within coarse race categories. In fact, variation in performance metrics within coarse groups often exceeds the variation between coarse groups. We explore why these disparities arise, finding that outcome rates, feature distributions, and the relationships between features and outcomes all vary significantly across granular race categories. Our results suggest that healthcare providers, hospital systems, and machine learning researchers should strive to collect, release, and use granular race data in place of coarse race data, and that existing analyses may significantly underestimate racial disparities in performance.
Improved Text Classification via Test-Time Augmentation
Jun 27, 2022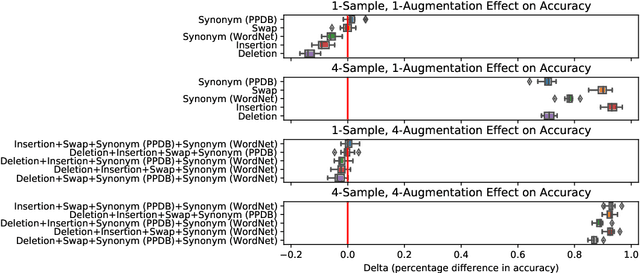

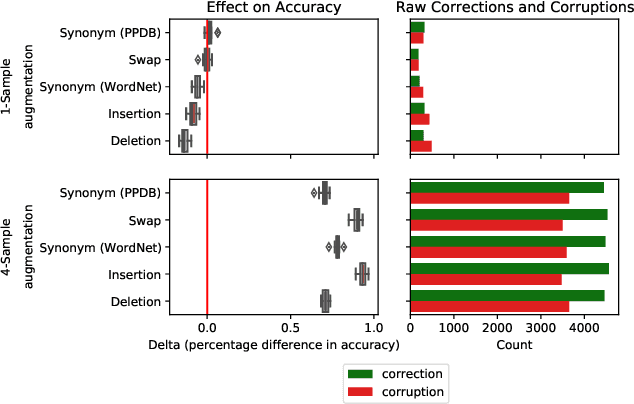
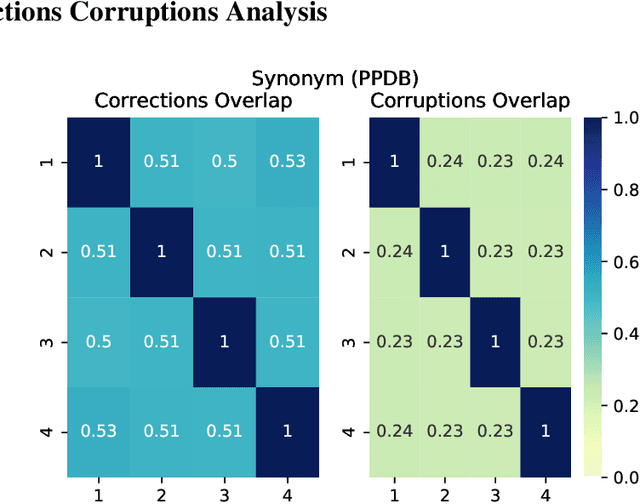
Test-time augmentation -- the aggregation of predictions across transformed examples of test inputs -- is an established technique to improve the performance of image classification models. Importantly, TTA can be used to improve model performance post-hoc, without additional training. Although test-time augmentation (TTA) can be applied to any data modality, it has seen limited adoption in NLP due in part to the difficulty of identifying label-preserving transformations. In this paper, we present augmentation policies that yield significant accuracy improvements with language models. A key finding is that augmentation policy design -- for instance, the number of samples generated from a single, non-deterministic augmentation -- has a considerable impact on the benefit of TTA. Experiments across a binary classification task and dataset show that test-time augmentation can deliver consistent improvements over current state-of-the-art approaches.
Data Augmentation for Electrocardiograms
Apr 09, 2022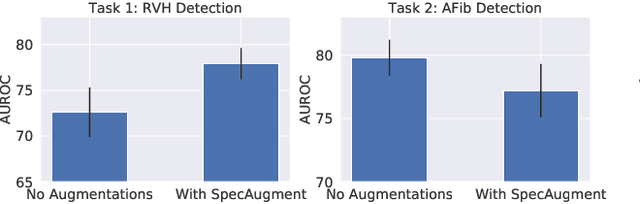
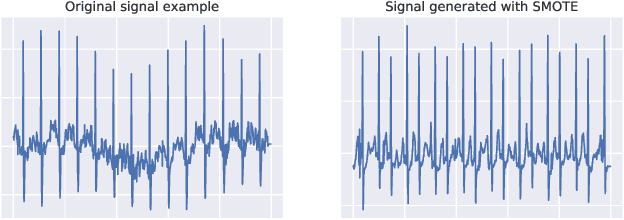
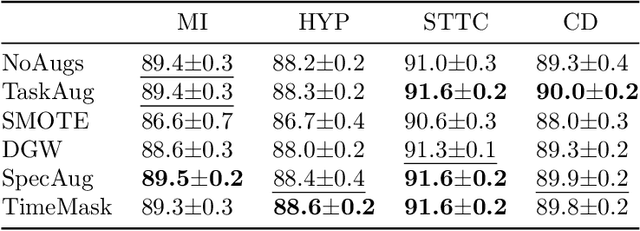
Neural network models have demonstrated impressive performance in predicting pathologies and outcomes from the 12-lead electrocardiogram (ECG). However, these models often need to be trained with large, labelled datasets, which are not available for many predictive tasks of interest. In this work, we perform an empirical study examining whether training time data augmentation methods can be used to improve performance on such data-scarce ECG prediction problems. We investigate how data augmentation strategies impact model performance when detecting cardiac abnormalities from the ECG. Motivated by our finding that the effectiveness of existing augmentation strategies is highly task-dependent, we introduce a new method, TaskAug, which defines a flexible augmentation policy that is optimized on a per-task basis. We outline an efficient learning algorithm to do so that leverages recent work in nested optimization and implicit differentiation. In experiments, considering three datasets and eight predictive tasks, we find that TaskAug is competitive with or improves on prior work, and the learned policies shed light on what transformations are most effective for different tasks. We distill key insights from our experimental evaluation, generating a set of best practices for applying data augmentation to ECG prediction problems.
Quantifying Inequality in Underreported Medical Conditions
Oct 08, 2021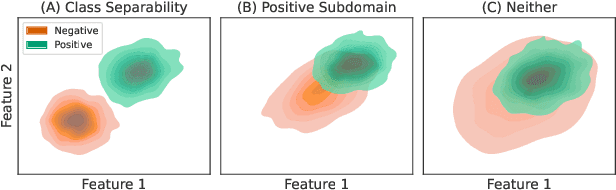
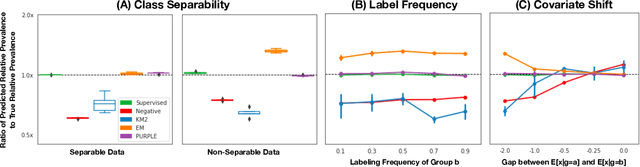

Estimating the prevalence of a medical condition, or the proportion of the population in which it occurs, is a fundamental problem in healthcare and public health. Accurate estimates of the relative prevalence across groups -- capturing, for example, that a condition affects women more frequently than men -- facilitate effective and equitable health policy which prioritizes groups who are disproportionately affected by a condition. However, it is difficult to estimate relative prevalence when a medical condition is underreported. In this work, we provide a method for accurately estimating the relative prevalence of underreported medical conditions, building upon the positive unlabeled learning framework. We show that under the commonly made covariate shift assumption -- i.e., that the probability of having a disease conditional on symptoms remains constant across groups -- we can recover the relative prevalence, even without restrictive assumptions commonly made in positive unlabeled learning and even if it is impossible to recover the absolute prevalence. We provide a suite of experiments on synthetic and real health data that demonstrate our method's ability to recover the relative prevalence more accurately than do baselines, and the method's robustness to plausible violations of the covariate shift assumption.
Learning to Limit Data Collection via Scaling Laws: Data Minimization Compliance in Practice
Jul 16, 2021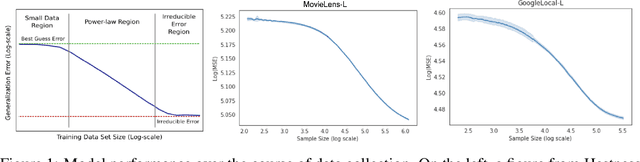
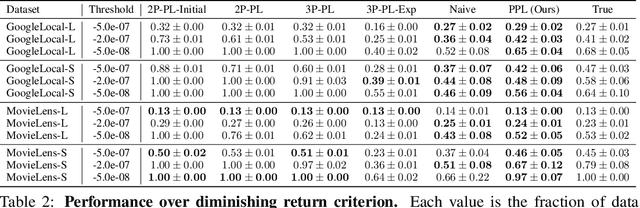
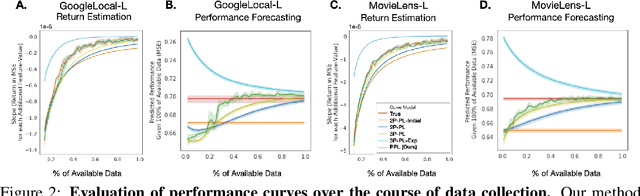
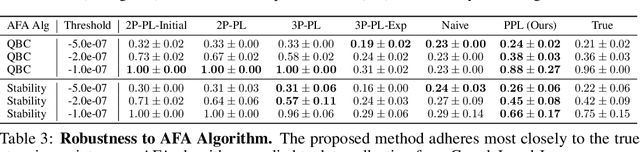
Data minimization is a legal obligation defined in the European Union's General Data Protection Regulation (GDPR) as the responsibility to process an adequate, relevant, and limited amount of personal data in relation to a processing purpose. However, unlike fairness or transparency, the principle has not seen wide adoption for machine learning systems due to a lack of computational interpretation. In this paper, we build on literature in machine learning and law to propose the first learning framework for limiting data collection based on an interpretation that ties the data collection purpose to system performance. We formalize a data minimization criterion based on performance curve derivatives and provide an effective and interpretable piecewise power law technique that models distinct stages of an algorithm's performance throughout data collection. Results from our empirical investigation offer deeper insights into the relevant considerations when designing a data minimization framework, including the choice of feature acquisition algorithm, initialization conditions, as well as impacts on individuals that hint at tensions between data minimization and fairness.