 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Institutional Frameworks Do Chatbots Assume? Auditing Jurisdictional Defaults in Multilingual LLMs
May 29, 2026LLMs increasingly answer questions about taxes, labor protections, healthcare, education, pensions, and administrative procedures, where usefulness often depends on the applicable jurisdiction. Multilingual users may write in their most comfortable language rather than one associated with the country or region whose rules apply. We ask whether deployed LLMs use input language as a default jurisdictional signal when prompts omit any country or region. Prior multilingual audits show that prompt language can shift cultural, political, or normative outputs; we examine which legal-administrative framework models supply when jurisdiction is underspecified. We evaluate seven LLMs developed in the United States or China on 60 underspecified legal-administrative prompts in English and Mandarin Chinese under three system-prompt conditions, yielding 2,520 manually annotated responses. Across models and conditions, Chinese input more often produces China-specific answers, while English input more often produces U.S.-specific, comparative, or generic answers. Prompts requiring a single answer further increase jurisdiction selection: pooled across models, 74.5% of English-input responses adopt a U.S. framework, while 53.3% of Chinese-input responses adopt a China framework. This directional pattern appears in all seven models. We describe this deployment-level pattern as institutional-framework misselection risk: a fluent answer may rely on a legal-administrative context the user did not intend, especially when their preferred language differs from the relevant jurisdiction. LLM interfaces should not route institutional advice by input language alone; when location is absent, they should request it or state the jurisdictional scope of the answer.
Representational Harms in LLM-Generated Narratives Against Global Majority Nationalities
Apr 24, 2026Large language models (LLMs) are increasingly used for text generation tasks from everyday use to high-stakes enterprise and government applications, including simulated interviews with asylum seekers. While many works highlight the new potential applications of LLMs, there are risks of LLMs encoding and perpetuating harmful biases about non-dominant communities across the globe. To better evaluate and mitigate such harms, more research examining how LLMs portray diverse individuals is needed. In this work, we study how national origin identities are portrayed by widely-adopted LLMs in response to open-ended narrative generation prompts. Our findings demonstrate the presence of persistent representational harms by national origin, including harmful stereotypes, erasure, and one-dimensional portrayals of Global Majority identities. Minoritized national identities are simultaneously underrepresented in power-neutral stories and overrepresented in subordinated character portrayals, which are over fifty times more likely to appear than dominant portrayals. The degree of harm is amplified when US nationality cues (e.g., ``American'') are present in input prompts. Notably, we find that the harms we identify cannot be explained away via sycophancy, as US-centric biases persist even when replacing US nationality cues with non-US national identities in the prompts. Based on our findings, we call for further exploration of cultural harms in LLMs through methodologies that center Global Majority perspectives and challenge the uncritical adoption of US-based LLMs for the classification, surveillance, and misrepresentation of the majority of our planet.
The Malicious Technical Ecosystem: Exposing Limitations in Technical Governance of AI-Generated Non-Consensual Intimate Images of Adults
Apr 24, 2025In this paper, we adopt a survivor-centered approach to locate and dissect the role of sociotechnical AI governance in preventing AI-Generated Non-Consensual Intimate Images (AIG-NCII) of adults, colloquially known as "deep fake pornography." We identify a "malicious technical ecosystem" or "MTE," comprising of open-source face-swapping models and nearly 200 "nudifying" software programs that allow non-technical users to create AIG-NCII within minutes. Then, using the National Institute of Standards and Technology (NIST) AI 100-4 report as a reflection of current synthetic content governance methods, we show how the current landscape of practices fails to effectively regulate the MTE for adult AIG-NCII, as well as flawed assumptions explaining these gaps.
"Ownership, Not Just Happy Talk": Co-Designing a Participatory Large Language Model for Journalism
Jan 28, 2025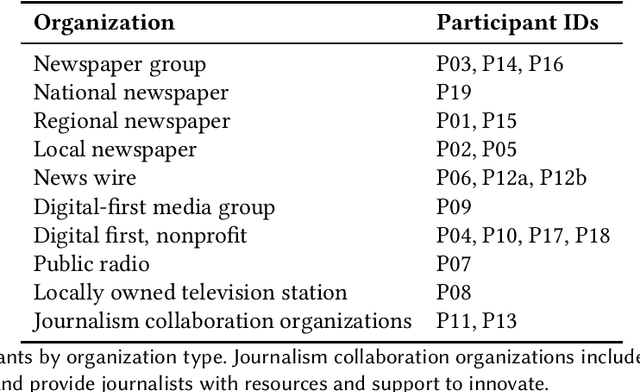
Journalism has emerged as an essential domain for understanding the uses, limitations, and impacts of large language models (LLMs) in the workplace. News organizations face divergent financial incentives: LLMs already permeate newswork processes within financially constrained organizations, even as ongoing legal challenges assert that AI companies violate their copyright. At stake are key questions about what LLMs are created to do, and by whom: How might a journalist-led LLM work, and what can participatory design illuminate about the present-day challenges about adapting ``one-size-fits-all'' foundation models to a given context of use? In this paper, we undertake a co-design exploration to understand how a participatory approach to LLMs might address opportunities and challenges around AI in journalism. Our 20 interviews with reporters, data journalists, editors, labor organizers, product leads, and executives highlight macro, meso, and micro tensions that designing for this opportunity space must address. From these desiderata, we describe the result of our co-design work: organizational structures and functionality for a journalist-controlled LLM. In closing, we discuss the limitations of commercial foundation models for workplace use, and the methodological implications of applying participatory methods to LLM co-design.
Participation in the age of foundation models
May 29, 2024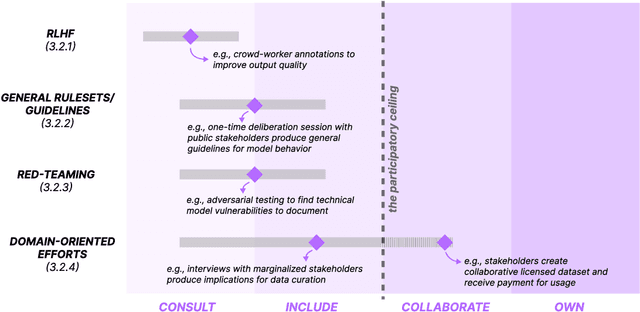
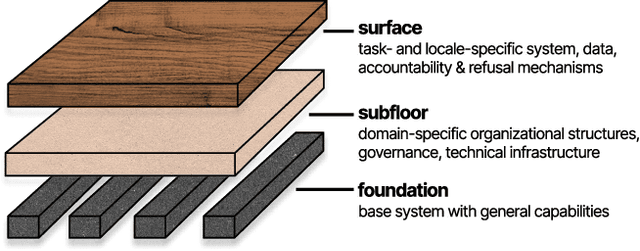
Growing interest and investment in the capabilities of foundation models has positioned such systems to impact a wide array of public services. Alongside these opportunities is the risk that these systems reify existing power imbalances and cause disproportionate harm to marginalized communities. Participatory approaches hold promise to instead lend agency and decision-making power to marginalized stakeholders. But existing approaches in participatory AI/ML are typically deeply grounded in context - how do we apply these approaches to foundation models, which are, by design, disconnected from context? Our paper interrogates this question. First, we examine existing attempts at incorporating participation into foundation models. We highlight the tension between participation and scale, demonstrating that it is intractable for impacted communities to meaningfully shape a foundation model that is intended to be universally applicable. In response, we develop a blueprint for participatory foundation models that identifies more local, application-oriented opportunities for meaningful participation. In addition to the "foundation" layer, our framework proposes the "subfloor'' layer, in which stakeholders develop shared technical infrastructure, norms and governance for a grounded domain, and the "surface'' layer, in which affected communities shape the use of a foundation model for a specific downstream task. The intermediate "subfloor'' layer scopes the range of potential harms to consider, and affords communities more concrete avenues for deliberation and intervention. At the same time, it avoids duplicative effort by scaling input across relevant use cases. Through three case studies in clinical care, financial services, and journalism, we illustrate how this multi-layer model can create more meaningful opportunities for participation than solely intervening at the foundation layer.
* 13 pages, 2 figures. Appeared at FAccT '24
Improved Text Classification via Test-Time Augmentation
Jun 27, 2022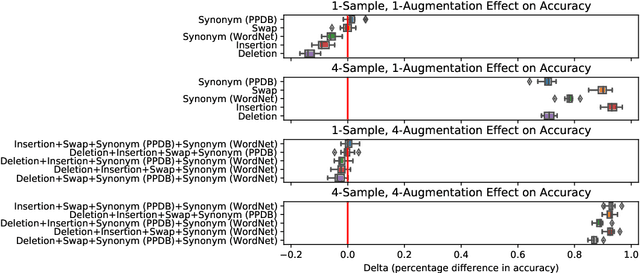

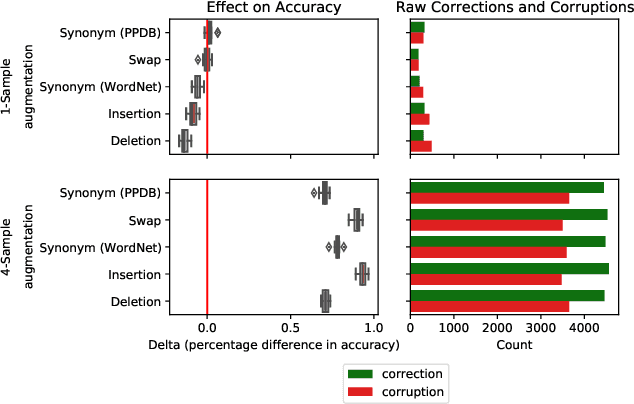
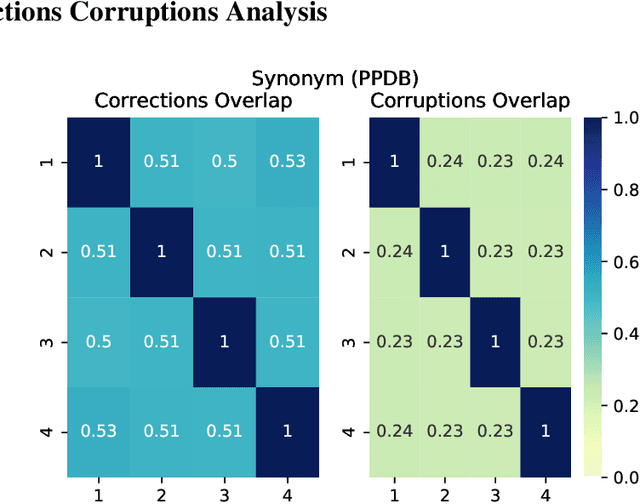
Test-time augmentation -- the aggregation of predictions across transformed examples of test inputs -- is an established technique to improve the performance of image classification models. Importantly, TTA can be used to improve model performance post-hoc, without additional training. Although test-time augmentation (TTA) can be applied to any data modality, it has seen limited adoption in NLP due in part to the difficulty of identifying label-preserving transformations. In this paper, we present augmentation policies that yield significant accuracy improvements with language models. A key finding is that augmentation policy design -- for instance, the number of samples generated from a single, non-deterministic augmentation -- has a considerable impact on the benefit of TTA. Experiments across a binary classification task and dataset show that test-time augmentation can deliver consistent improvements over current state-of-the-art approaches.
Beyond Faithfulness: A Framework to Characterize and Compare Saliency Methods
Jun 07, 2022
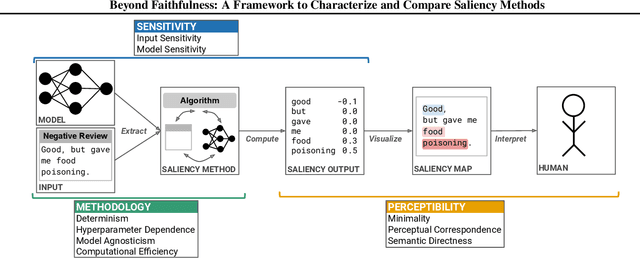
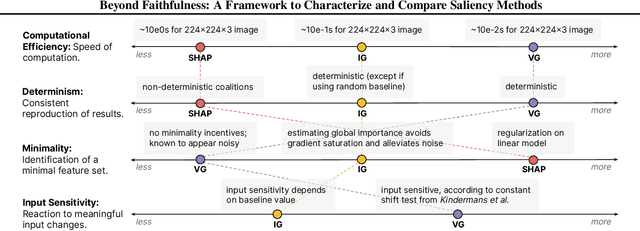

Saliency methods calculate how important each input feature is to a machine learning model's prediction, and are commonly used to understand model reasoning. "Faithfulness", or how fully and accurately the saliency output reflects the underlying model, is an oft-cited desideratum for these methods. However, explanation methods must necessarily sacrifice certain information in service of user-oriented goals such as simplicity. To that end, and akin to performance metrics, we frame saliency methods as abstractions: individual tools that provide insight into specific aspects of model behavior and entail tradeoffs. Using this framing, we describe a framework of nine dimensions to characterize and compare the properties of saliency methods. We group these dimensions into three categories that map to different phases of the interpretation process: methodology, or how the saliency is calculated; sensitivity, or relationships between the saliency result and the underlying model or input; and, perceptibility, or how a user interprets the result. As we show, these dimensions give us a granular vocabulary for describing and comparing saliency methods -- for instance, allowing us to develop "saliency cards" as a form of documentation, or helping downstream users understand tradeoffs and choose a method for a particular use case. Moreover, by situating existing saliency methods within this framework, we identify opportunities for future work, including filling gaps in the landscape and developing new evaluation metrics.
Intuitively Assessing ML Model Reliability through Example-Based Explanations and Editing Model Inputs
Feb 17, 2021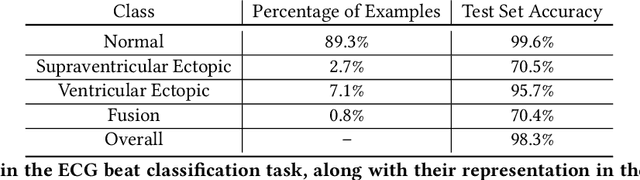
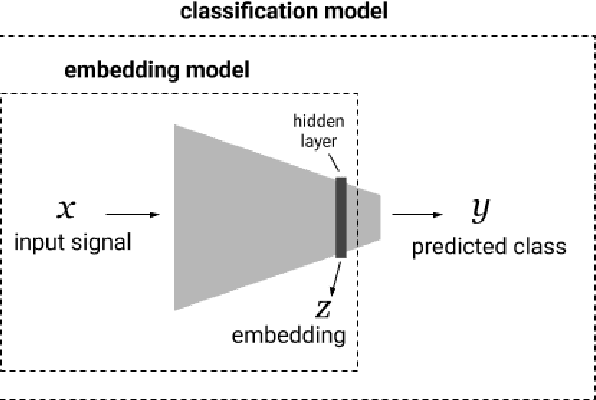
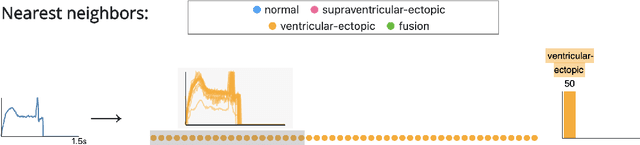
Interpretability methods aim to help users build trust in and understand the capabilities of machine learning models. However, existing approaches often rely on abstract, complex visualizations that poorly map to the task at hand or require non-trivial ML expertise to interpret. Here, we present two interface modules to facilitate a more intuitive assessment of model reliability. To help users better characterize and reason about a model's uncertainty, we visualize raw and aggregate information about a given input's nearest neighbors in the training dataset. Using an interactive editor, users can manipulate this input in semantically-meaningful ways, determine the effect on the output, and compare against their prior expectations. We evaluate our interface using an electrocardiogram beat classification case study. Compared to a baseline feature importance interface, we find that 9 physicians are better able to align the model's uncertainty with clinically relevant factors and build intuition about its capabilities and limitations.
Beyond Expertise and Roles: A Framework to Characterize the Stakeholders of Interpretable Machine Learning and their Needs
Jan 24, 2021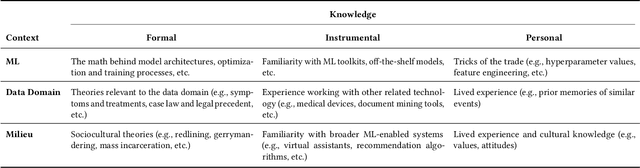
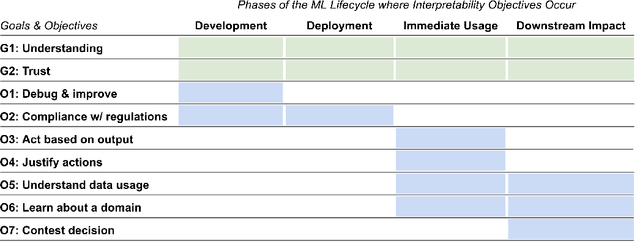
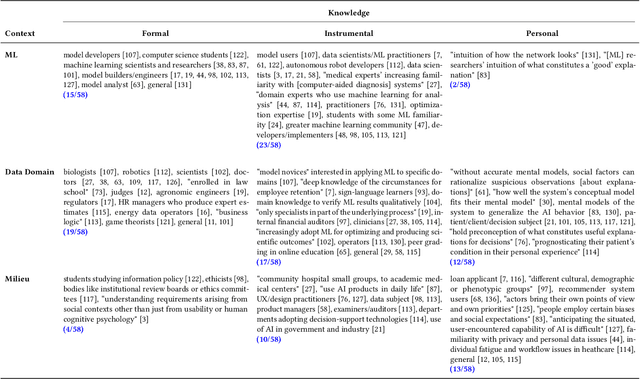
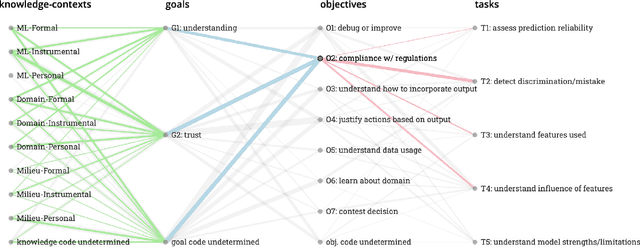
To ensure accountability and mitigate harm, it is critical that diverse stakeholders can interrogate black-box automated systems and find information that is understandable, relevant, and useful to them. In this paper, we eschew prior expertise- and role-based categorizations of interpretability stakeholders in favor of a more granular framework that decouples stakeholders' knowledge from their interpretability needs. We characterize stakeholders by their formal, instrumental, and personal knowledge and how it manifests in the contexts of machine learning, the data domain, and the general milieu. We additionally distill a hierarchical typology of stakeholder needs that distinguishes higher-level domain goals from lower-level interpretability tasks. In assessing the descriptive, evaluative, and generative powers of our framework, we find our more nuanced treatment of stakeholders reveals gaps and opportunities in the interpretability literature, adds precision to the design and comparison of user studies, and facilitates a more reflexive approach to conducting this research.
Underspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020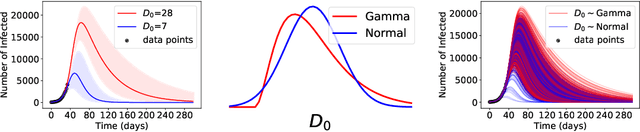

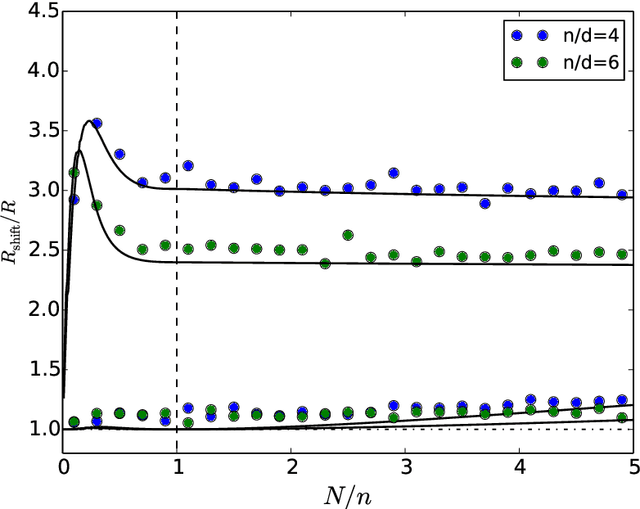

ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.