 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebugging Tests for Model Explanations
Nov 10, 2020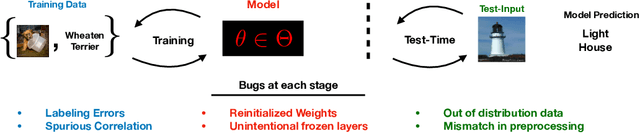
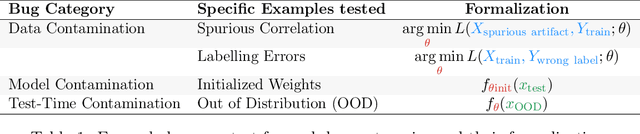


We investigate whether post-hoc model explanations are effective for diagnosing model errors--model debugging. In response to the challenge of explaining a model's prediction, a vast array of explanation methods have been proposed. Despite increasing use, it is unclear if they are effective. To start, we categorize \textit{bugs}, based on their source, into:~\textit{data, model, and test-time} contamination bugs. For several explanation methods, we assess their ability to: detect spurious correlation artifacts (data contamination), diagnose mislabeled training examples (data contamination), differentiate between a (partially) re-initialized model and a trained one (model contamination), and detect out-of-distribution inputs (test-time contamination). We find that the methods tested are able to diagnose a spurious background bug, but not conclusively identify mislabeled training examples. In addition, a class of methods, that modify the back-propagation algorithm are invariant to the higher layer parameters of a deep network; hence, ineffective for diagnosing model contamination. We complement our analysis with a human subject study, and find that subjects fail to identify defective models using attributions, but instead rely, primarily, on model predictions. Taken together, our results provide guidance for practitioners and researchers turning to explanations as tools for model debugging.
Misplaced Trust: Measuring the Interference of Machine Learning in Human Decision-Making
May 22, 2020
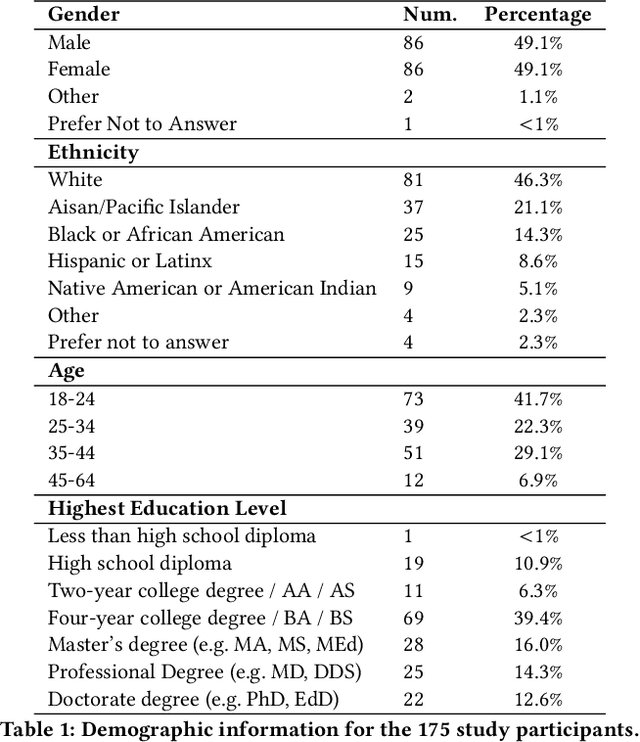
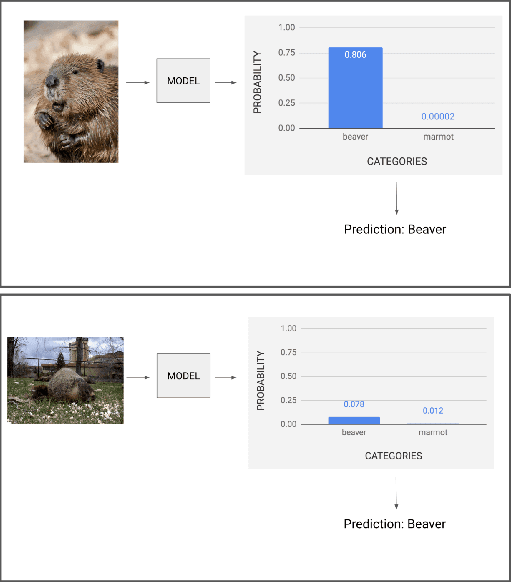

ML decision-aid systems are increasingly common on the web, but their successful integration relies on people trusting them appropriately: they should use the system to fill in gaps in their ability, but recognize signals that the system might be incorrect. We measured how people's trust in ML recommendations differs by expertise and with more system information through a task-based study of 175 adults. We used two tasks that are difficult for humans: comparing large crowd sizes and identifying similar-looking animals. Our results provide three key insights: (1) People trust incorrect ML recommendations for tasks that they perform correctly the majority of the time, even if they have high prior knowledge about ML or are given information indicating the system is not confident in its prediction; (2) Four different types of system information all increased people's trust in recommendations; and (3) Math and logic skills may be as important as ML for decision-makers working with ML recommendations.
* 10 pages