 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Bottleneck Language Models For protein design
Nov 09, 2024



We introduce Concept Bottleneck Protein Language Models (CB-pLM), a generative masked language model with a layer where each neuron corresponds to an interpretable concept. Our architecture offers three key benefits: i) Control: We can intervene on concept values to precisely control the properties of generated proteins, achieving a 3 times larger change in desired concept values compared to baselines. ii) Interpretability: A linear mapping between concept values and predicted tokens allows transparent analysis of the model's decision-making process. iii) Debugging: This transparency facilitates easy debugging of trained models. Our models achieve pre-training perplexity and downstream task performance comparable to traditional masked protein language models, demonstrating that interpretability does not compromise performance. While adaptable to any language model, we focus on masked protein language models due to their importance in drug discovery and the ability to validate our model's capabilities through real-world experiments and expert knowledge. We scale our CB-pLM from 24 million to 3 billion parameters, making them the largest Concept Bottleneck Models trained and the first capable of generative language modeling.
How Aligned are Generative Models to Humans in High-Stakes Decision-Making?
Oct 20, 2024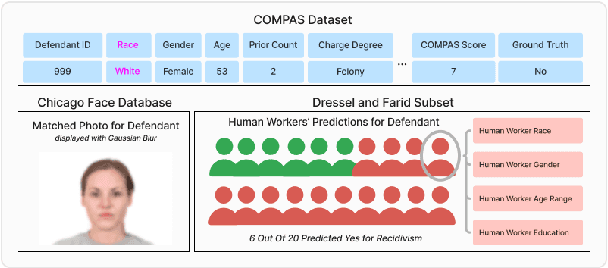


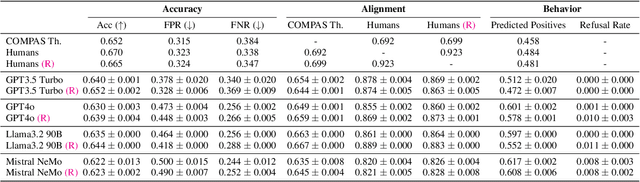
Large generative models (LMs) are increasingly being considered for high-stakes decision-making. This work considers how such models compare to humans and predictive AI models on a specific case of recidivism prediction. We combine three datasets -- COMPAS predictive AI risk scores, human recidivism judgements, and photos -- into a dataset on which we study the properties of several state-of-the-art, multimodal LMs. Beyond accuracy and bias, we focus on studying human-LM alignment on the task of recidivism prediction. We investigate if these models can be steered towards human decisions, the impact of adding photos, and whether anti-discimination prompting is effective. We find that LMs can be steered to outperform humans and COMPAS using in context-learning. We find anti-discrimination prompting to have unintended effects, causing some models to inhibit themselves and significantly reduce their number of positive predictions.
Error Discovery by Clustering Influence Embeddings
Dec 07, 2023



We present a method for identifying groups of test examples -- slices -- on which a model under-performs, a task now known as slice discovery. We formalize coherence -- a requirement that erroneous predictions, within a slice, should be wrong for the same reason -- as a key property that any slice discovery method should satisfy. We then use influence functions to derive a new slice discovery method, InfEmbed, which satisfies coherence by returning slices whose examples are influenced similarly by the training data. InfEmbed is simple, and consists of applying K-Means clustering to a novel representation we deem influence embeddings. We show InfEmbed outperforms current state-of-the-art methods on 2 benchmarks, and is effective for model debugging across several case studies.
Quantifying and mitigating the impact of label errors on model disparity metrics
Oct 04, 2023



Errors in labels obtained via human annotation adversely affect a model's performance. Existing approaches propose ways to mitigate the effect of label error on a model's downstream accuracy, yet little is known about its impact on a model's disparity metrics. Here we study the effect of label error on a model's disparity metrics. We empirically characterize how varying levels of label error, in both training and test data, affect these disparity metrics. We find that group calibration and other metrics are sensitive to train-time and test-time label error -- particularly for minority groups. This disparate effect persists even for models trained with noise-aware algorithms. To mitigate the impact of training-time label error, we present an approach to estimate the influence of a training input's label on a model's group disparity metric. We empirically assess the proposed approach on a variety of datasets and find significant improvement, compared to alternative approaches, in identifying training inputs that improve a model's disparity metric. We complement the approach with an automatic relabel-and-finetune scheme that produces updated models with, provably, improved group calibration error.
Post hoc Explanations may be Ineffective for Detecting Unknown Spurious Correlation
Dec 09, 2022



We investigate whether three types of post hoc model explanations--feature attribution, concept activation, and training point ranking--are effective for detecting a model's reliance on spurious signals in the training data. Specifically, we consider the scenario where the spurious signal to be detected is unknown, at test-time, to the user of the explanation method. We design an empirical methodology that uses semi-synthetic datasets along with pre-specified spurious artifacts to obtain models that verifiably rely on these spurious training signals. We then provide a suite of metrics that assess an explanation method's reliability for spurious signal detection under various conditions. We find that the post hoc explanation methods tested are ineffective when the spurious artifact is unknown at test-time especially for non-visible artifacts like a background blur. Further, we find that feature attribution methods are susceptible to erroneously indicating dependence on spurious signals even when the model being explained does not rely on spurious artifacts. This finding casts doubt on the utility of these approaches, in the hands of a practitioner, for detecting a model's reliance on spurious signals.
Debugging Tests for Model Explanations
Nov 10, 2020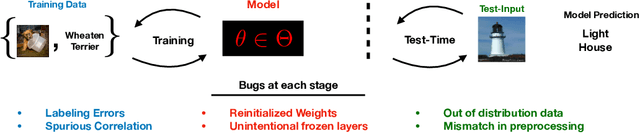
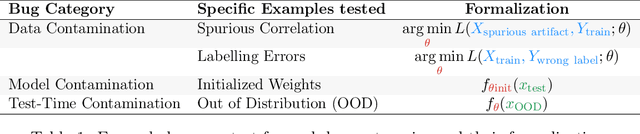


We investigate whether post-hoc model explanations are effective for diagnosing model errors--model debugging. In response to the challenge of explaining a model's prediction, a vast array of explanation methods have been proposed. Despite increasing use, it is unclear if they are effective. To start, we categorize \textit{bugs}, based on their source, into:~\textit{data, model, and test-time} contamination bugs. For several explanation methods, we assess their ability to: detect spurious correlation artifacts (data contamination), diagnose mislabeled training examples (data contamination), differentiate between a (partially) re-initialized model and a trained one (model contamination), and detect out-of-distribution inputs (test-time contamination). We find that the methods tested are able to diagnose a spurious background bug, but not conclusively identify mislabeled training examples. In addition, a class of methods, that modify the back-propagation algorithm are invariant to the higher layer parameters of a deep network; hence, ineffective for diagnosing model contamination. We complement our analysis with a human subject study, and find that subjects fail to identify defective models using attributions, but instead rely, primarily, on model predictions. Taken together, our results provide guidance for practitioners and researchers turning to explanations as tools for model debugging.
Assessing the (Un)Trustworthiness of Saliency Maps for Localizing Abnormalities in Medical Imaging
Aug 06, 2020Saliency maps have become a widely used method to make deep learning models more interpretable by providing post-hoc explanations of classifiers through identification of the most pertinent areas of the input medical image. They are increasingly being used in medical imaging to provide clinically plausible explanations for the decisions the neural network makes. However, the utility and robustness of these visualization maps has not yet been rigorously examined in the context of medical imaging. We posit that trustworthiness in this context requires 1) localization utility, 2) sensitivity to model weight randomization, 3) repeatability, and 4) reproducibility. Using the localization information available in two large public radiology datasets, we quantify the performance of eight commonly used saliency map approaches for the above criteria using area under the precision-recall curves (AUPRC) and structural similarity index (SSIM), comparing their performance to various baseline measures. Using our framework to quantify the trustworthiness of saliency maps, we show that all eight saliency map techniques fail at least one of the criteria and are, in most cases, less trustworthy when compared to the baselines. We suggest that their usage in the high-risk domain of medical imaging warrants additional scrutiny and recommend that detection or segmentation models be used if localization is the desired output of the network. Additionally, to promote reproducibility of our findings, we provide the code we used for all tests performed in this work at this link: https://github.com/QTIM-Lab/Assessing-Saliency-Maps.
Explaining Explanations to Society
Jan 19, 2019
There is a disconnect between explanatory artificial intelligence (XAI) methods and the types of explanations that are useful for and demanded by society (policy makers, government officials, etc.) Questions that experts in artificial intelligence (AI) ask opaque systems provide inside explanations, focused on debugging, reliability, and validation. These are different from those that society will ask of these systems to build trust and confidence in their decisions. Although explanatory AI systems can answer many questions that experts desire, they often don't explain why they made decisions in a way that is precise (true to the model) and understandable to humans. These outside explanations can be used to build trust, comply with regulatory and policy changes, and act as external validation. In this paper, we focus on XAI methods for deep neural networks (DNNs) because of DNNs' use in decision-making and inherent opacity. We explore the types of questions that explanatory DNN systems can answer and discuss challenges in building explanatory systems that provide outside explanations for societal requirements and benefit.
Sanity Checks for Saliency Maps
Oct 28, 2018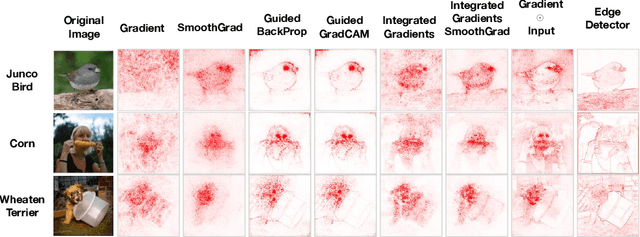
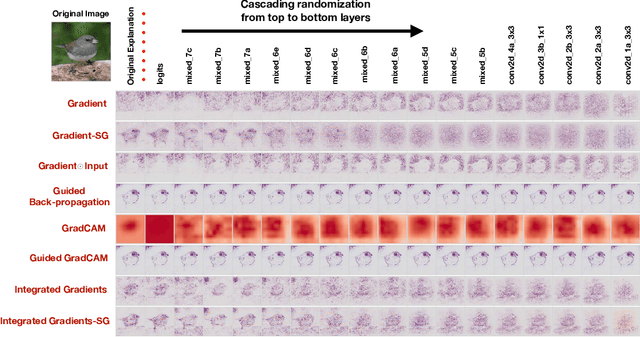
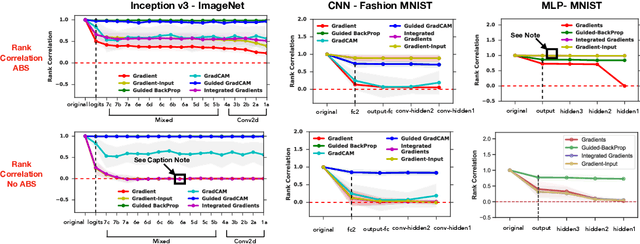
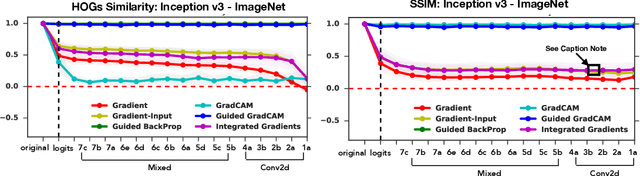
Saliency methods have emerged as a popular tool to highlight features in an input deemed relevant for the prediction of a learned model. Several saliency methods have been proposed, often guided by visual appeal on image data. In this work, we propose an actionable methodology to evaluate what kinds of explanations a given method can and cannot provide. We find that reliance, solely, on visual assessment can be misleading. Through extensive experiments we show that some existing saliency methods are independent both of the model and of the data generating process. Consequently, methods that fail the proposed tests are inadequate for tasks that are sensitive to either data or model, such as, finding outliers in the data, explaining the relationship between inputs and outputs that the model learned, and debugging the model. We interpret our findings through an analogy with edge detection in images, a technique that requires neither training data nor model. Theory in the case of a linear model and a single-layer convolutional neural network supports our experimental findings.
Local Explanation Methods for Deep Neural Networks Lack Sensitivity to Parameter Values
Oct 08, 2018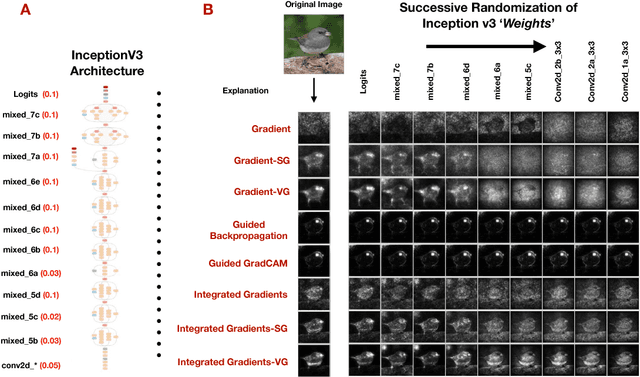
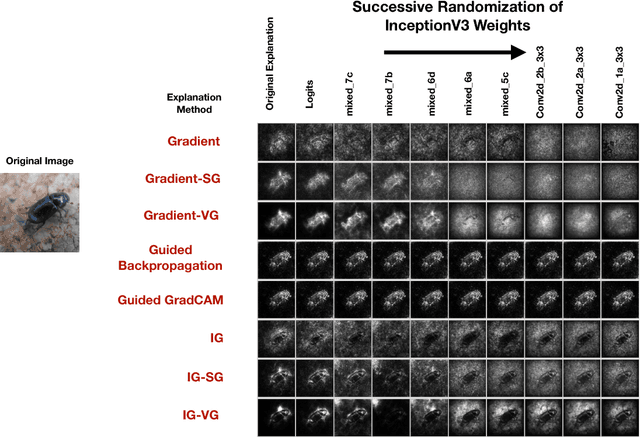
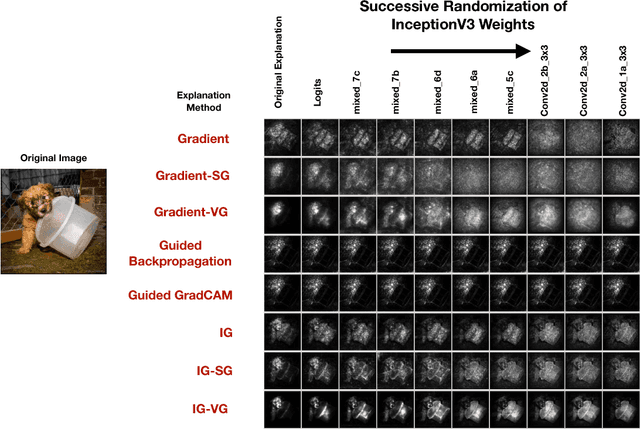
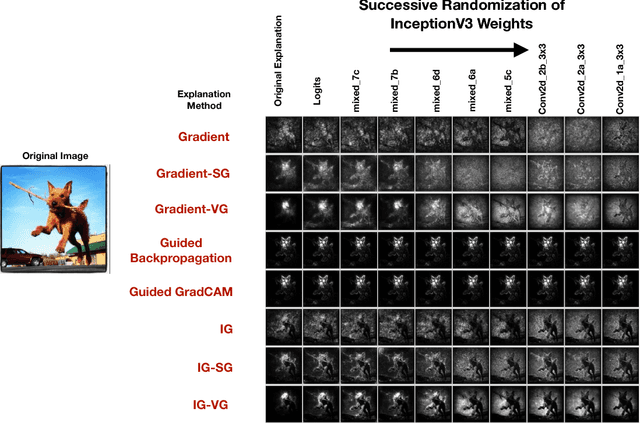
Explaining the output of a complicated machine learning model like a deep neural network (DNN) is a central challenge in machine learning. Several proposed local explanation methods address this issue by identifying what dimensions of a single input are most responsible for a DNN's output. The goal of this work is to assess the sensitivity of local explanations to DNN parameter values. Somewhat surprisingly, we find that DNNs with randomly-initialized weights produce explanations that are both visually and quantitatively similar to those produced by DNNs with learned weights. Our conjecture is that this phenomenon occurs because these explanations are dominated by the lower level features of a DNN, and that a DNN's architecture provides a strong prior which significantly affects the representations learned at these lower layers. NOTE: This work is now subsumed by our recent manuscript, Sanity Checks for Saliency Maps (to appear NIPS 2018), where we expand on findings and address concerns raised in Sundararajan et. al. (2018).