 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Error Discovery by Clustering Influence Embeddings
Dec 07, 2023



We present a method for identifying groups of test examples -- slices -- on which a model under-performs, a task now known as slice discovery. We formalize coherence -- a requirement that erroneous predictions, within a slice, should be wrong for the same reason -- as a key property that any slice discovery method should satisfy. We then use influence functions to derive a new slice discovery method, InfEmbed, which satisfies coherence by returning slices whose examples are influenced similarly by the training data. InfEmbed is simple, and consists of applying K-Means clustering to a novel representation we deem influence embeddings. We show InfEmbed outperforms current state-of-the-art methods on 2 benchmarks, and is effective for model debugging across several case studies.
XAIR: A Framework of Explainable AI in Augmented Reality
Mar 28, 2023



Explainable AI (XAI) has established itself as an important component of AI-driven interactive systems. With Augmented Reality (AR) becoming more integrated in daily lives, the role of XAI also becomes essential in AR because end-users will frequently interact with intelligent services. However, it is unclear how to design effective XAI experiences for AR. We propose XAIR, a design framework that addresses "when", "what", and "how" to provide explanations of AI output in AR. The framework was based on a multi-disciplinary literature review of XAI and HCI research, a large-scale survey probing 500+ end-users' preferences for AR-based explanations, and three workshops with 12 experts collecting their insights about XAI design in AR. XAIR's utility and effectiveness was verified via a study with 10 designers and another study with 12 end-users. XAIR can provide guidelines for designers, inspiring them to identify new design opportunities and achieve effective XAI designs in AR.
Bias Mitigation Framework for Intersectional Subgroups in Neural Networks
Dec 26, 2022We propose a fairness-aware learning framework that mitigates intersectional subgroup bias associated with protected attributes. Prior research has primarily focused on mitigating one kind of bias by incorporating complex fairness-driven constraints into optimization objectives or designing additional layers that focus on specific protected attributes. We introduce a simple and generic bias mitigation approach that prevents models from learning relationships between protected attributes and output variable by reducing mutual information between them. We demonstrate that our approach is effective in reducing bias with little or no drop in accuracy. We also show that the models trained with our learning framework become causally fair and insensitive to the values of protected attributes. Finally, we validate our approach by studying feature interactions between protected and non-protected attributes. We demonstrate that these interactions are significantly reduced when applying our bias mitigation.
Extreme Dimension Reduction for Handling Covariate Shift
Mar 12, 2018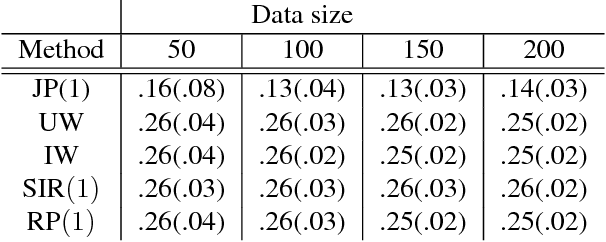
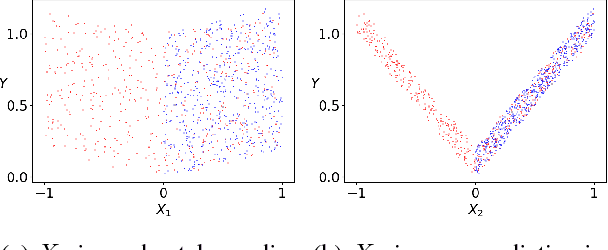
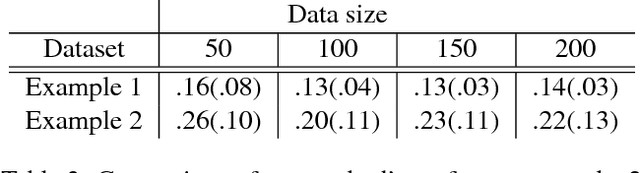
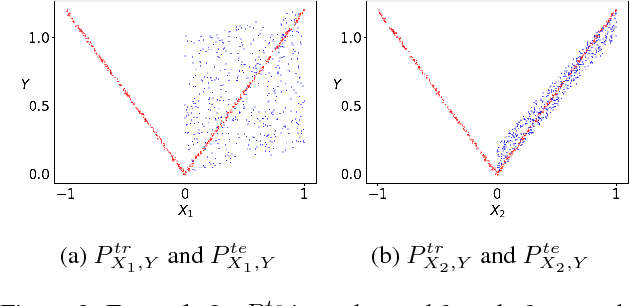
In the covariate shift learning scenario, the training and test covariate distributions differ, so that a predictor's average loss over the training and test distributions also differ. In this work, we explore the potential of extreme dimension reduction, i.e. to very low dimensions, in improving the performance of importance weighting methods for handling covariate shift, which fail in high dimensions due to potentially high train/test covariate divergence and the inability to accurately estimate the requisite density ratios. We first formulate and solve a problem optimizing over linear subspaces a combination of their predictive utility and train/test divergence within. Applying it to simulated and real data, we show extreme dimension reduction helps sometimes but not always, due to a bias introduced by dimension reduction.
Modeling Recovery Curves With Application to Prostatectomy
Mar 05, 2018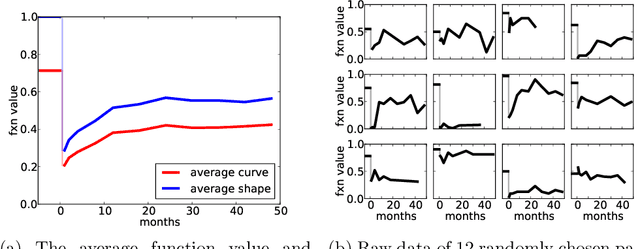

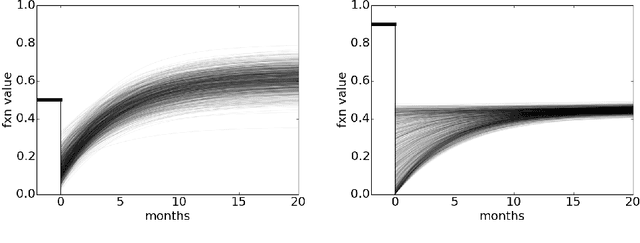
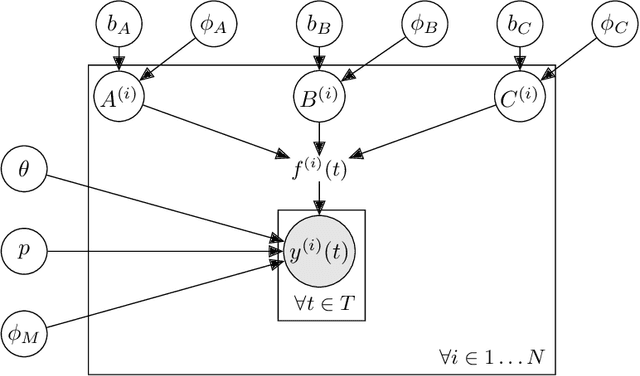
We propose a Bayesian model that predicts recovery curves based on information available before the disruptive event. A recovery curve of interest is the quantified sexual function of prostate cancer patients after prostatectomy surgery. We illustrate the utility of our model as a pre-treatment medical decision aid, producing personalized predictions that are both interpretable and accurate. We uncover covariate relationships that agree with and supplement that in existing medical literature.
Causal Falling Rule Lists
Jul 05, 2017
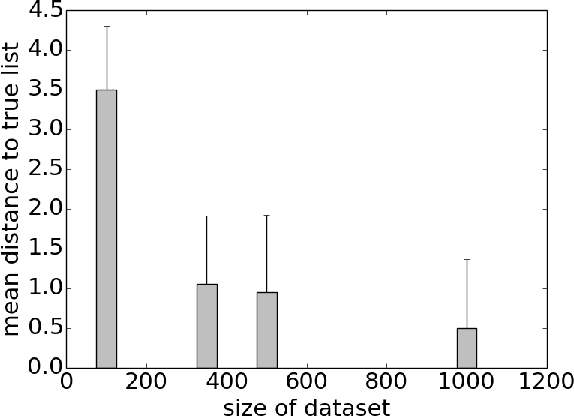
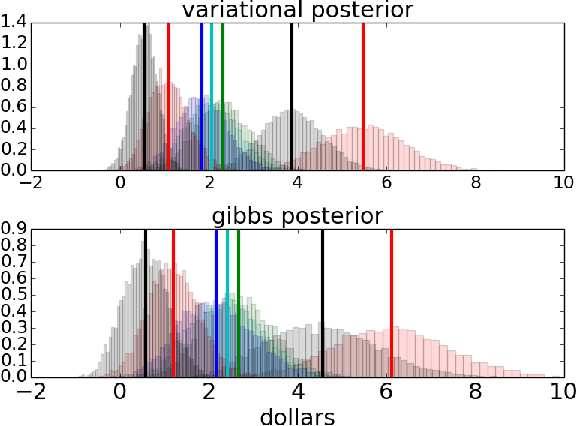
A causal falling rule list (CFRL) is a sequence of if-then rules that specifies heterogeneous treatment effects, where (i) the order of rules determines the treatment effect subgroup a subject belongs to, and (ii) the treatment effect decreases monotonically down the list. A given CFRL parameterizes a hierarchical bayesian regression model in which the treatment effects are incorporated as parameters, and assumed constant within model-specific subgroups. We formulate the search for the CFRL best supported by the data as a Bayesian model selection problem, where we perform a search over the space of CFRL models, and approximate the evidence for a given CFRL model using standard variational techniques. We apply CFRL to a census wage dataset to identify subgroups of differing wage inequalities between men and women.
Falling Rule Lists
Feb 01, 2015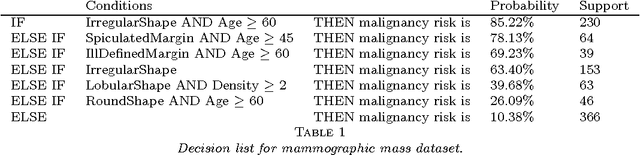
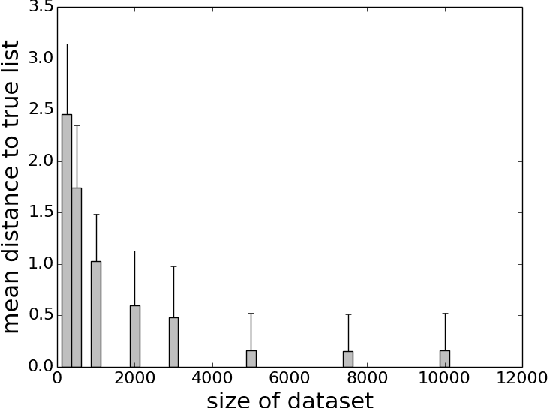
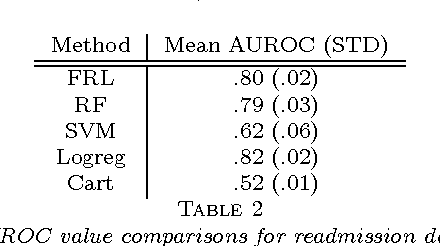
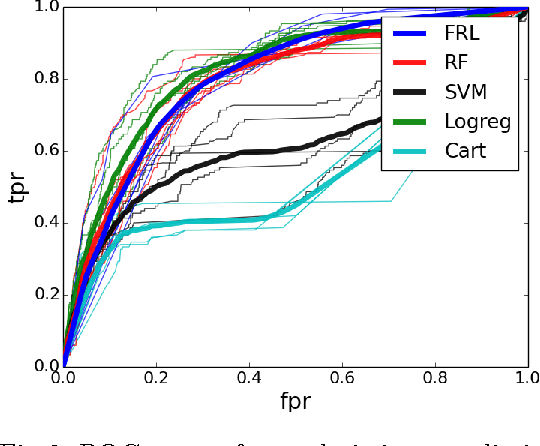
Falling rule lists are classification models consisting of an ordered list of if-then rules, where (i) the order of rules determines which example should be classified by each rule, and (ii) the estimated probability of success decreases monotonically down the list. These kinds of rule lists are inspired by healthcare applications where patients would be stratified into risk sets and the highest at-risk patients should be considered first. We provide a Bayesian framework for learning falling rule lists that does not rely on traditional greedy decision tree learning methods.