 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Cultural and Social Awareness of LLM Web Agents
Oct 30, 2024As large language models (LLMs) expand into performing as agents for real-world applications beyond traditional NLP tasks, evaluating their robustness becomes increasingly important. However, existing benchmarks often overlook critical dimensions like cultural and social awareness. To address these, we introduce CASA, a benchmark designed to assess LLM agents' sensitivity to cultural and social norms across two web-based tasks: online shopping and social discussion forums. Our approach evaluates LLM agents' ability to detect and appropriately respond to norm-violating user queries and observations. Furthermore, we propose a comprehensive evaluation framework that measures awareness coverage, helpfulness in managing user queries, and the violation rate when facing misleading web content. Experiments show that current LLMs perform significantly better in non-agent than in web-based agent environments, with agents achieving less than 10% awareness coverage and over 40% violation rates. To improve performance, we explore two methods: prompting and fine-tuning, and find that combining both methods can offer complementary advantages -- fine-tuning on culture-specific datasets significantly enhances the agents' ability to generalize across different regions, while prompting boosts the agents' ability to navigate complex tasks. These findings highlight the importance of constantly benchmarking LLM agents' cultural and social awareness during the development cycle.
XForecast: Evaluating Natural Language Explanations for Time Series Forecasting
Oct 21, 2024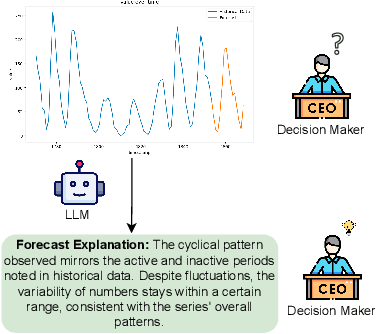
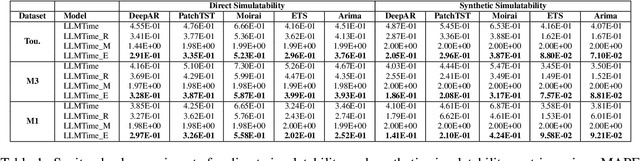
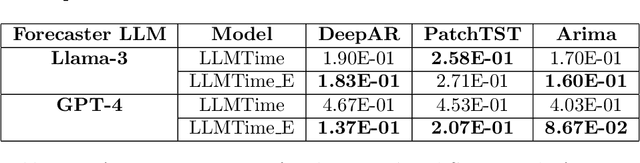
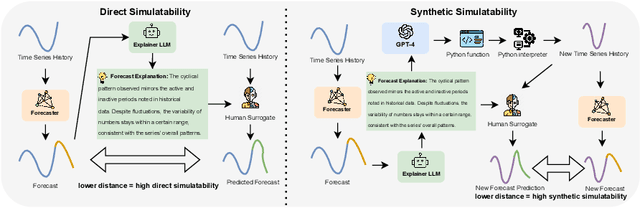
Time series forecasting aids decision-making, especially for stakeholders who rely on accurate predictions, making it very important to understand and explain these models to ensure informed decisions. Traditional explainable AI (XAI) methods, which underline feature or temporal importance, often require expert knowledge. In contrast, natural language explanations (NLEs) are more accessible to laypeople. However, evaluating forecast NLEs is difficult due to the complex causal relationships in time series data. To address this, we introduce two new performance metrics based on simulatability, assessing how well a human surrogate can predict model forecasts using the explanations. Experiments show these metrics differentiate good from poor explanations and align with human judgments. Utilizing these metrics, we further evaluate the ability of state-of-the-art large language models (LLMs) to generate explanations for time series data, finding that numerical reasoning, rather than model size, is the main factor influencing explanation quality.
How Aligned are Generative Models to Humans in High-Stakes Decision-Making?
Oct 20, 2024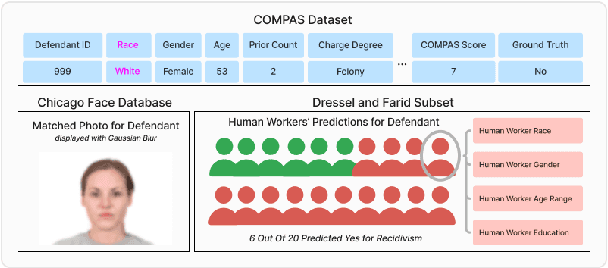


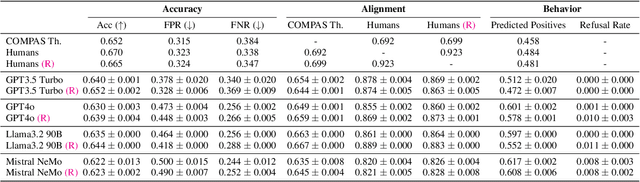
Large generative models (LMs) are increasingly being considered for high-stakes decision-making. This work considers how such models compare to humans and predictive AI models on a specific case of recidivism prediction. We combine three datasets -- COMPAS predictive AI risk scores, human recidivism judgements, and photos -- into a dataset on which we study the properties of several state-of-the-art, multimodal LMs. Beyond accuracy and bias, we focus on studying human-LM alignment on the task of recidivism prediction. We investigate if these models can be steered towards human decisions, the impact of adding photos, and whether anti-discimination prompting is effective. We find that LMs can be steered to outperform humans and COMPAS using in context-learning. We find anti-discrimination prompting to have unintended effects, causing some models to inhibit themselves and significantly reduce their number of positive predictions.
MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases
Jun 12, 2024



The deployment of Large Language Models (LLMs) and Large Multimodal Models (LMMs) on mobile devices has gained significant attention due to the benefits of enhanced privacy, stability, and personalization. However, the hardware constraints of mobile devices necessitate the use of models with fewer parameters and model compression techniques like quantization. Currently, there is limited understanding of quantization's impact on various task performances, including LLM tasks, LMM tasks, and, critically, trust and safety. There is a lack of adequate tools for systematically testing these models on mobile devices. To address these gaps, we introduce MobileAIBench, a comprehensive benchmarking framework for evaluating mobile-optimized LLMs and LMMs. MobileAIBench assesses models across different sizes, quantization levels, and tasks, measuring latency and resource consumption on real devices. Our two-part open-source framework includes a library for running evaluations on desktops and an iOS app for on-device latency and hardware utilization measurements. Our thorough analysis aims to accelerate mobile AI research and deployment by providing insights into the performance and feasibility of deploying LLMs and LMMs on mobile platforms.
Error Discovery by Clustering Influence Embeddings
Dec 07, 2023



We present a method for identifying groups of test examples -- slices -- on which a model under-performs, a task now known as slice discovery. We formalize coherence -- a requirement that erroneous predictions, within a slice, should be wrong for the same reason -- as a key property that any slice discovery method should satisfy. We then use influence functions to derive a new slice discovery method, InfEmbed, which satisfies coherence by returning slices whose examples are influenced similarly by the training data. InfEmbed is simple, and consists of applying K-Means clustering to a novel representation we deem influence embeddings. We show InfEmbed outperforms current state-of-the-art methods on 2 benchmarks, and is effective for model debugging across several case studies.
Missing Values and Imputation in Healthcare Data: Can Interpretable Machine Learning Help?
Apr 23, 2023



Missing values are a fundamental problem in data science. Many datasets have missing values that must be properly handled because the way missing values are treated can have large impact on the resulting machine learning model. In medical applications, the consequences may affect healthcare decisions. There are many methods in the literature for dealing with missing values, including state-of-the-art methods which often depend on black-box models for imputation. In this work, we show how recent advances in interpretable machine learning provide a new perspective for understanding and tackling the missing value problem. We propose methods based on high-accuracy glass-box Explainable Boosting Machines (EBMs) that can help users (1) gain new insights on missingness mechanisms and better understand the causes of missingness, and (2) detect -- or even alleviate -- potential risks introduced by imputation algorithms. Experiments on real-world medical datasets illustrate the effectiveness of the proposed methods.
Practical Policy Optimization with Personalized Experimentation
Mar 30, 2023

Many organizations measure treatment effects via an experimentation platform to evaluate the casual effect of product variations prior to full-scale deployment. However, standard experimentation platforms do not perform optimally for end user populations that exhibit heterogeneous treatment effects (HTEs). Here we present a personalized experimentation framework, Personalized Experiments (PEX), which optimizes treatment group assignment at the user level via HTE modeling and sequential decision policy optimization to optimize multiple short-term and long-term outcomes simultaneously. We describe an end-to-end workflow that has proven to be successful in practice and can be readily implemented using open-source software.
Efficient Heterogeneous Treatment Effect Estimation With Multiple Experiments and Multiple Outcomes
Jun 10, 2022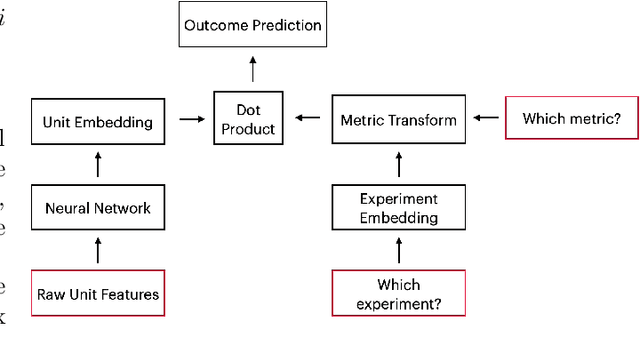
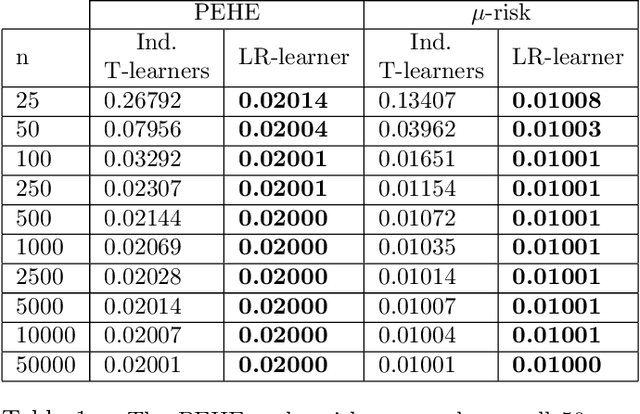
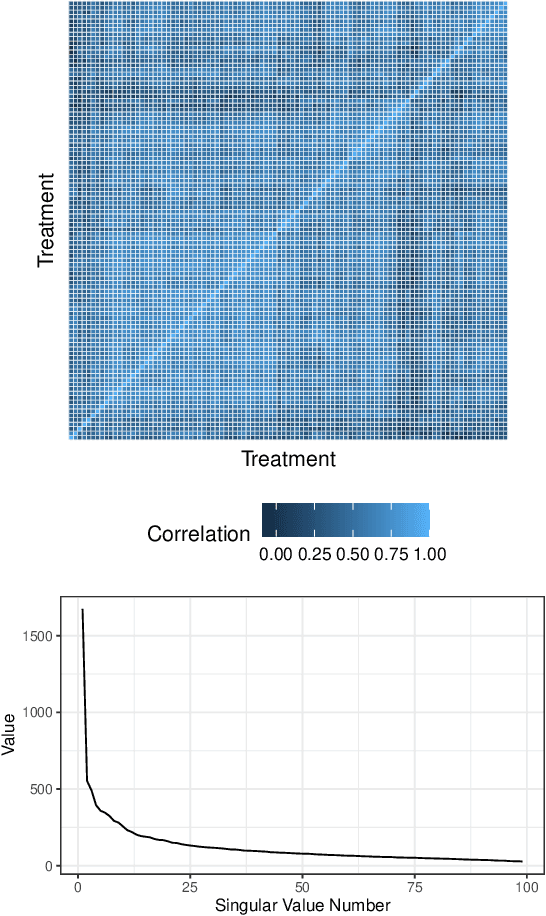
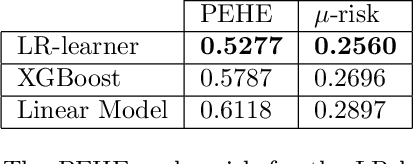
Learning heterogeneous treatment effects (HTEs) is an important problem across many fields. Most existing methods consider the setting with a single treatment arm and a single outcome metric. However, in many real world domains, experiments are run consistently - for example, in internet companies, A/B tests are run every day to measure the impacts of potential changes across many different metrics of interest. We show that even if an analyst cares only about the HTEs in one experiment for one metric, precision can be improved greatly by analyzing all of the data together to take advantage of cross-experiment and cross-outcome metric correlations. We formalize this idea in a tensor factorization framework and propose a simple and scalable model which we refer to as the low rank or LR-learner. Experiments in both synthetic and real data suggest that the LR-learner can be much more precise than independent HTE estimation.
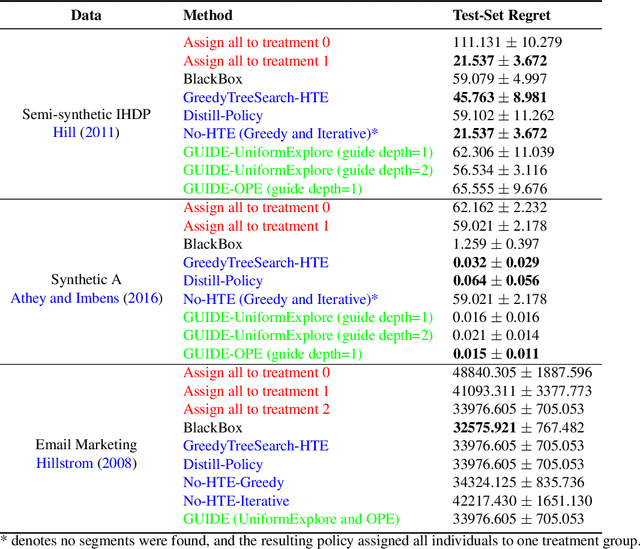
Distilling Heterogeneity: From Explanations of Heterogeneous Treatment Effect Models to Interpretable Policies
Nov 05, 2021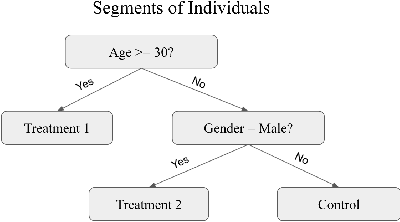
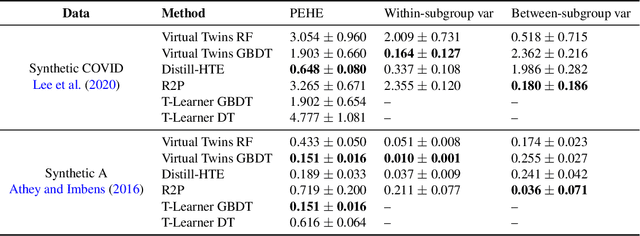
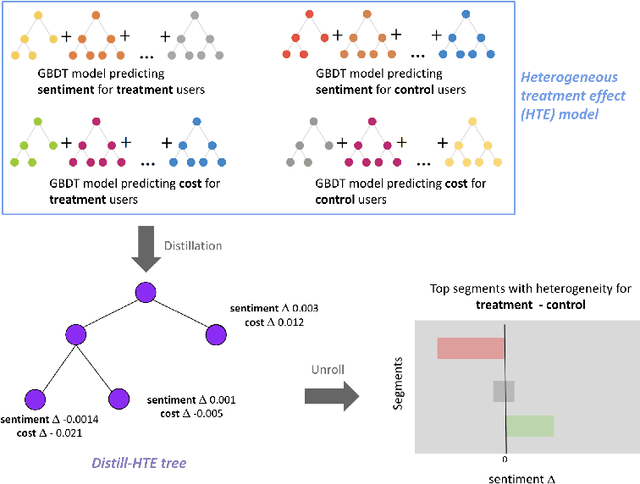
Internet companies are increasingly using machine learning models to create personalized policies which assign, for each individual, the best predicted treatment for that individual. They are frequently derived from black-box heterogeneous treatment effect (HTE) models that predict individual-level treatment effects. In this paper, we focus on (1) learning explanations for HTE models; (2) learning interpretable policies that prescribe treatment assignments. We also propose guidance trees, an approach to ensemble multiple interpretable policies without the loss of interpretability. These rule-based interpretable policies are easy to deploy and avoid the need to maintain a HTE model in a production environment.
How Interpretable and Trustworthy are GAMs?
Jun 11, 2020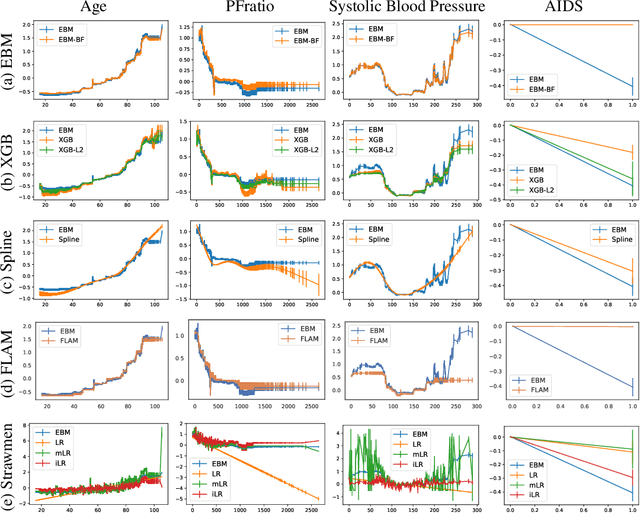
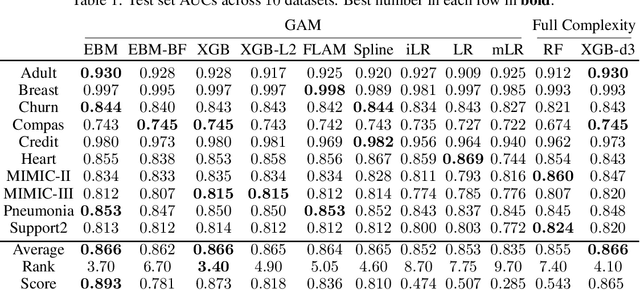

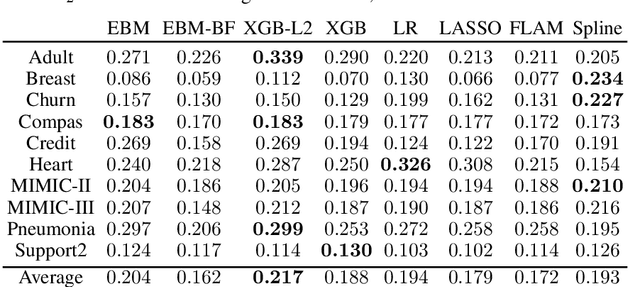
Generalized additive models (GAMs) have become a leading model class for data bias discovery and model auditing. However, there are a variety of algorithms for training GAMs, and these do not always learn the same things. Statisticians originally used splines to train GAMs, but more recently GAMs are being trained with boosted decision trees. It is unclear which GAM model(s) to believe, particularly when their explanations are contradictory. In this paper, we investigate a variety of different GAM algorithms both qualitatively and quantitatively on real and simulated datasets. Our results suggest that inductive bias plays a crucial role in model explanations and tree-based GAMs are to be recommended for the kinds of problems and dataset sizes we worked with.