 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoirai 2.0: When Less Is More for Time Series Forecasting
Nov 12, 2025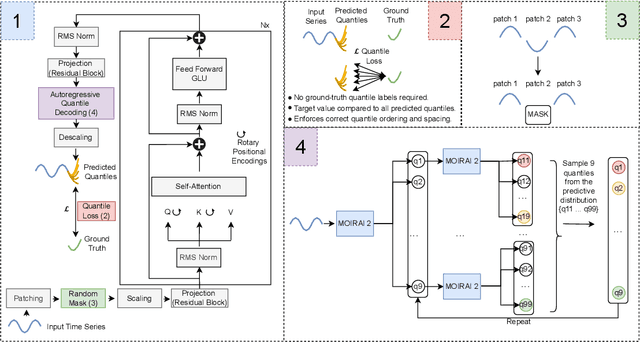
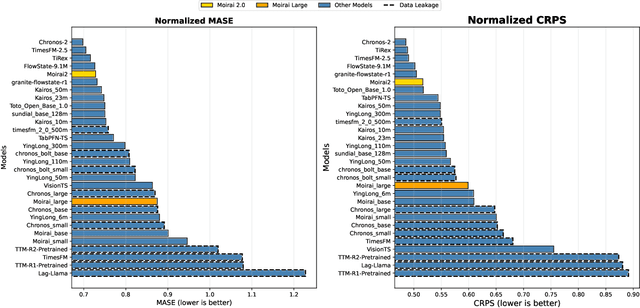

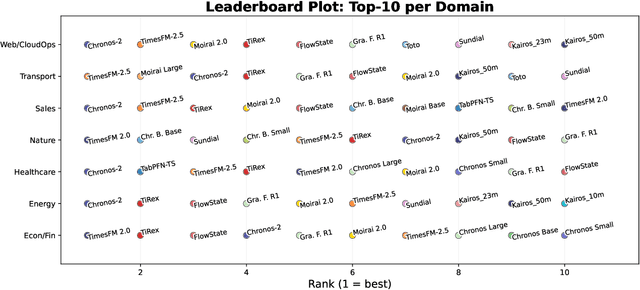
We introduce Moirai 2.0, a decoder-only time-series foundation model trained on a new corpus of 36M series. The model adopts quantile forecasting and multi-token prediction, improving both probabilistic accuracy and inference efficiency. On the Gift-Eval benchmark, it ranks among the top pretrained models while achieving a strong trade-off between accuracy, speed, and model size. Compared to Moirai 1.0, Moirai 2.0 replaces masked-encoder training, multi-patch inputs, and mixture-distribution outputs with a simpler decoder-only architecture, single patch, and quantile loss. Ablation studies isolate these changes -- showing that the decoder-only backbone along with recursive multi-quantile decoding contribute most to the gains. Additional experiments show that Moirai 2.0 outperforms larger models from the same family and exhibits robust domain-level results. In terms of efficiency and model size, Moirai 2.0 is twice as fast and thirty times smaller than its prior best version, Moirai 1.0-Large, while also performing better. Model performance plateaus with increasing parameter count and declines at longer horizons, motivating future work on data scaling and long-horizon modeling. We release code and evaluation details to support further research.
Empowering Time Series Analysis with Synthetic Data: A Survey and Outlook in the Era of Foundation Models
Mar 14, 2025



Time series analysis is crucial for understanding dynamics of complex systems. Recent advances in foundation models have led to task-agnostic Time Series Foundation Models (TSFMs) and Large Language Model-based Time Series Models (TSLLMs), enabling generalized learning and integrating contextual information. However, their success depends on large, diverse, and high-quality datasets, which are challenging to build due to regulatory, diversity, quality, and quantity constraints. Synthetic data emerge as a viable solution, addressing these challenges by offering scalable, unbiased, and high-quality alternatives. This survey provides a comprehensive review of synthetic data for TSFMs and TSLLMs, analyzing data generation strategies, their role in model pretraining, fine-tuning, and evaluation, and identifying future research directions.
XForecast: Evaluating Natural Language Explanations for Time Series Forecasting
Oct 21, 2024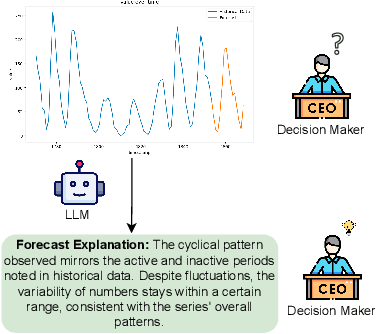
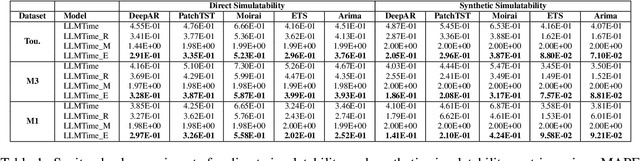
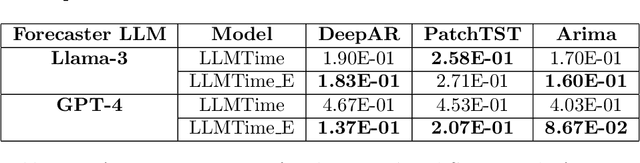
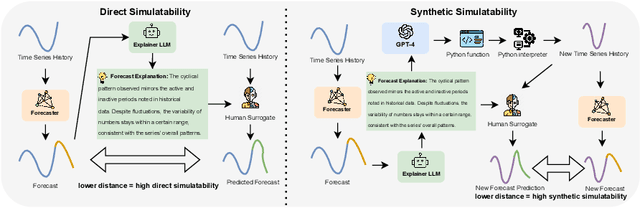
Time series forecasting aids decision-making, especially for stakeholders who rely on accurate predictions, making it very important to understand and explain these models to ensure informed decisions. Traditional explainable AI (XAI) methods, which underline feature or temporal importance, often require expert knowledge. In contrast, natural language explanations (NLEs) are more accessible to laypeople. However, evaluating forecast NLEs is difficult due to the complex causal relationships in time series data. To address this, we introduce two new performance metrics based on simulatability, assessing how well a human surrogate can predict model forecasts using the explanations. Experiments show these metrics differentiate good from poor explanations and align with human judgments. Utilizing these metrics, we further evaluate the ability of state-of-the-art large language models (LLMs) to generate explanations for time series data, finding that numerical reasoning, rather than model size, is the main factor influencing explanation quality.
GIFT-Eval: A Benchmark For General Time Series Forecasting Model Evaluation
Oct 14, 2024



Time series foundation models excel in zero-shot forecasting, handling diverse tasks without explicit training. However, the advancement of these models has been hindered by the lack of comprehensive benchmarks. To address this gap, we introduce the General Time Series Forecasting Model Evaluation, GIFT-Eval, a pioneering benchmark aimed at promoting evaluation across diverse datasets. GIFT-Eval encompasses 28 datasets over 144,000 time series and 177 million data points, spanning seven domains, 10 frequencies, multivariate inputs, and prediction lengths ranging from short to long-term forecasts. To facilitate the effective pretraining and evaluation of foundation models, we also provide a non-leaking pretraining dataset containing approximately 230 billion data points. Additionally, we provide a comprehensive analysis of 17 baselines, which includes statistical models, deep learning models, and foundation models. We discuss each model in the context of various benchmark characteristics and offer a qualitative analysis that spans both deep learning and foundation models. We believe the insights from this analysis, along with access to this new standard zero-shot time series forecasting benchmark, will guide future developments in time series foundation models. The codebase, datasets, and a leaderboard showing all the results in detail will be available soon.
Moirai-MoE: Empowering Time Series Foundation Models with Sparse Mixture of Experts
Oct 14, 2024



Time series foundation models have demonstrated impressive performance as zero-shot forecasters. However, achieving effectively unified training on time series remains an open challenge. Existing approaches introduce some level of model specialization to account for the highly heterogeneous nature of time series data. For instance, Moirai pursues unified training by employing multiple input/output projection layers, each tailored to handle time series at a specific frequency. Similarly, TimesFM maintains a frequency embedding dictionary for this purpose. We identify two major drawbacks to this human-imposed frequency-level model specialization: (1) Frequency is not a reliable indicator of the underlying patterns in time series. For example, time series with different frequencies can display similar patterns, while those with the same frequency may exhibit varied patterns. (2) Non-stationarity is an inherent property of real-world time series, leading to varied distributions even within a short context window of a single time series. Frequency-level specialization is too coarse-grained to capture this level of diversity. To address these limitations, this paper introduces Moirai-MoE, using a single input/output projection layer while delegating the modeling of diverse time series patterns to the sparse mixture of experts (MoE) within Transformers. With these designs, Moirai-MoE reduces reliance on human-defined heuristics and enables automatic token-level specialization. Extensive experiments on 39 datasets demonstrate the superiority of Moirai-MoE over existing foundation models in both in-distribution and zero-shot scenarios. Furthermore, this study conducts comprehensive model analyses to explore the inner workings of time series MoE foundation models and provides valuable insights for future research.
Granular Change Accuracy: A More Accurate Performance Metric for Dialogue State Tracking
Mar 17, 2024



Current metrics for evaluating Dialogue State Tracking (DST) systems exhibit three primary limitations. They: i) erroneously presume a uniform distribution of slots throughout the dialog, ii) neglect to assign partial scores for individual turns, iii) frequently overestimate or underestimate performance by repeatedly counting the models' successful or failed predictions. To address these shortcomings, we introduce a novel metric: Granular Change Accuracy (GCA). GCA focuses on evaluating the predicted changes in dialogue state over the entire dialogue history. Benchmarking reveals that GCA effectively reduces biases arising from distribution uniformity and the positioning of errors across turns, resulting in a more precise evaluation. Notably, we find that these biases are particularly pronounced when evaluating few-shot or zero-shot trained models, becoming even more evident as the model's error rate increases. Hence, GCA offers significant promise, particularly for assessing models trained with limited resources. Our GCA implementation is a useful addition to the pool of DST metrics.
CESAR: Automatic Induction of Compositional Instructions for Multi-turn Dialogs
Nov 29, 2023Instruction-based multitasking has played a critical role in the success of large language models (LLMs) in multi-turn dialog applications. While publicly available LLMs have shown promising performance, when exposed to complex instructions with multiple constraints, they lag against state-of-the-art models like ChatGPT. In this work, we hypothesize that the availability of large-scale complex demonstrations is crucial in bridging this gap. Focusing on dialog applications, we propose a novel framework, CESAR, that unifies a large number of dialog tasks in the same format and allows programmatic induction of complex instructions without any manual effort. We apply CESAR on InstructDial, a benchmark for instruction-based dialog tasks. We further enhance InstructDial with new datasets and tasks and utilize CESAR to induce complex tasks with compositional instructions. This results in a new benchmark called InstructDial++, which includes 63 datasets with 86 basic tasks and 68 composite tasks. Through rigorous experiments, we demonstrate the scalability of CESAR in providing rich instructions. Models trained on InstructDial++ can follow compositional prompts, such as prompts that ask for multiple stylistic constraints.
Prompter: Zero-shot Adaptive Prefixes for Dialogue State Tracking Domain Adaptation
Jun 07, 2023



A challenge in the Dialogue State Tracking (DST) field is adapting models to new domains without using any supervised data, zero-shot domain adaptation. Parameter-Efficient Transfer Learning (PETL) has the potential to address this problem due to its robustness. However, it has yet to be applied to the zero-shot scenarios, as it is not clear how to apply it unsupervisedly. Our method, Prompter, uses descriptions of target domain slots to generate dynamic prefixes that are concatenated to the key and values at each layer's self-attention mechanism. This allows for the use of prefix-tuning in zero-shot. Prompter outperforms previous methods on both the MultiWOZ and SGD benchmarks. In generating prefixes, our analyses find that Prompter not only utilizes the semantics of slot descriptions but also how often the slots appear together in conversation. Moreover, Prompter's gains are due to its improved ability to distinguish "none"-valued dialogue slots, compared against baselines.
A Simple But Effective Approach to n-shot Task-Oriented Dialogue Augmentation
Mar 02, 2021
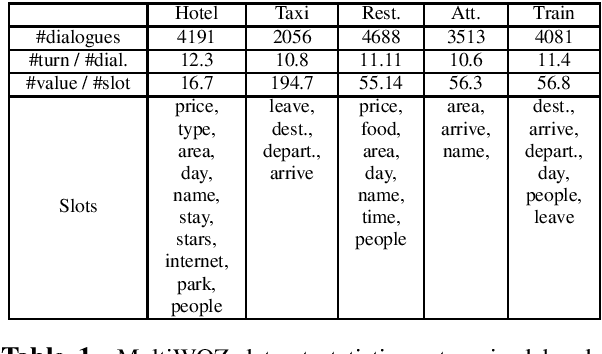

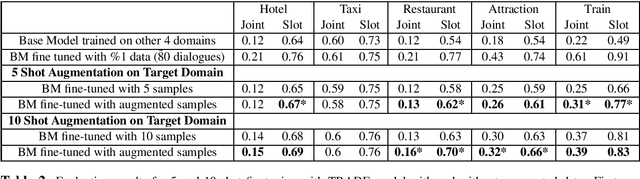
The collection and annotation of task-oriented conversational data is a costly and time-consuming manner. Many augmentation techniques have been proposed to improve the performance of state-of-the-art (SOTA) systems in new domains that lack the necessary amount of data for training. However, these augmentation techniques (e.g. paraphrasing) also require some mediocre amount of data since they use learning-based approaches. This makes using SOTA systems in emerging low-resource domains infeasible. We, to tackle this problem, introduce a framework, that creates synthetic task-oriented dialogues in a fully automatic manner, which operates with input sizes of as small as a few dialogues. Our framework uses the simple idea that each turn-pair in a task-oriented dialogue has a certain function and exploits this idea to mix them creating new dialogues. We evaluate our framework within a low-resource setting by integrating it with a SOTA model TRADE in the dialogue state tracking task and observe significant improvements in the fine-tuning scenarios in several domains. We conclude that this end-to-end dialogue augmentation framework can be a crucial tool for natural language understanding performance in emerging task-oriented dialogue domains.