 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXForecast: Evaluating Natural Language Explanations for Time Series Forecasting
Paper and Code
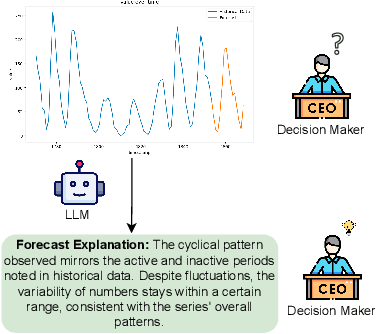
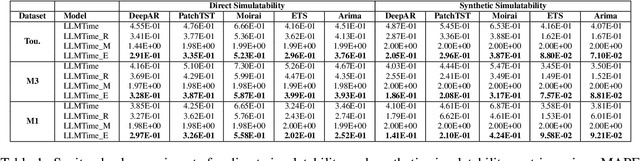
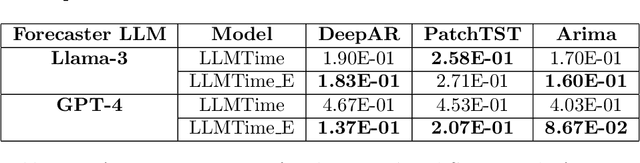
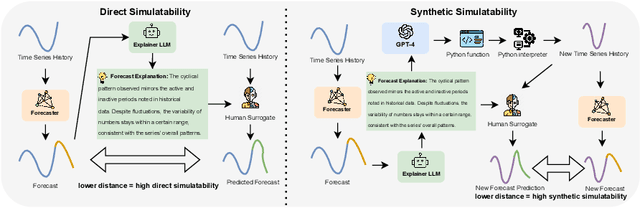
Time series forecasting aids decision-making, especially for stakeholders who rely on accurate predictions, making it very important to understand and explain these models to ensure informed decisions. Traditional explainable AI (XAI) methods, which underline feature or temporal importance, often require expert knowledge. In contrast, natural language explanations (NLEs) are more accessible to laypeople. However, evaluating forecast NLEs is difficult due to the complex causal relationships in time series data. To address this, we introduce two new performance metrics based on simulatability, assessing how well a human surrogate can predict model forecasts using the explanations. Experiments show these metrics differentiate good from poor explanations and align with human judgments. Utilizing these metrics, we further evaluate the ability of state-of-the-art large language models (LLMs) to generate explanations for time series data, finding that numerical reasoning, rather than model size, is the main factor influencing explanation quality.