 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Preference Optimization with Rating Information: Practical Algorithms and Provable Gains
Jan 31, 2026The class of direct preference optimization (DPO) algorithms has emerged as a promising approach for solving the alignment problem in foundation models. These algorithms work with very limited feedback in the form of pairwise preferences and fine-tune models to align with these preferences without explicitly learning a reward model. While the form of feedback used by these algorithms makes the data collection process easy and relatively more accurate, its ambiguity in terms of the quality of responses could have negative implications. For example, it is not clear if a decrease (increase) in the likelihood of preferred (dispreferred) responses during the execution of these algorithms could be interpreted as a positive or negative phenomenon. In this paper, we study how to design algorithms that can leverage additional information in the form of rating gap, which informs the learner how much the chosen response is better than the rejected one. We present new algorithms that can achieve faster statistical rates than DPO in presence of accurate rating gap information. Moreover, we theoretically prove and empirically show that the performance of our algorithms is robust to inaccuracy in rating gaps. Finally, we demonstrate the solid performance of our methods in comparison to a number of DPO-style algorithms across a wide range of LLMs and evaluation benchmarks.
CESAR: Automatic Induction of Compositional Instructions for Multi-turn Dialogs
Nov 29, 2023Instruction-based multitasking has played a critical role in the success of large language models (LLMs) in multi-turn dialog applications. While publicly available LLMs have shown promising performance, when exposed to complex instructions with multiple constraints, they lag against state-of-the-art models like ChatGPT. In this work, we hypothesize that the availability of large-scale complex demonstrations is crucial in bridging this gap. Focusing on dialog applications, we propose a novel framework, CESAR, that unifies a large number of dialog tasks in the same format and allows programmatic induction of complex instructions without any manual effort. We apply CESAR on InstructDial, a benchmark for instruction-based dialog tasks. We further enhance InstructDial with new datasets and tasks and utilize CESAR to induce complex tasks with compositional instructions. This results in a new benchmark called InstructDial++, which includes 63 datasets with 86 basic tasks and 68 composite tasks. Through rigorous experiments, we demonstrate the scalability of CESAR in providing rich instructions. Models trained on InstructDial++ can follow compositional prompts, such as prompts that ask for multiple stylistic constraints.
Data-Efficient Alignment of Large Language Models with Human Feedback Through Natural Language
Nov 24, 2023



Learning from human feedback is a prominent technique to align the output of large language models (LLMs) with human expectations. Reinforcement learning from human feedback (RLHF) leverages human preference signals that are in the form of ranking of response pairs to perform this alignment. However, human preference on LLM outputs can come in much richer forms including natural language, which may provide detailed feedback on strengths and weaknesses of a given response. In this work we investigate data efficiency of modeling human feedback that is in natural language. Specifically, we fine-tune an open-source LLM, e.g., Falcon-40B-Instruct, on a relatively small amount (1000 records or even less) of human feedback in natural language in the form of critiques and revisions of responses. We show that this model is able to improve the quality of responses from even some of the strongest LLMs such as ChatGPT, BARD, and Vicuna, through critique and revision of those responses. For instance, through one iteration of revision of ChatGPT responses, the revised responses have 56.6% win rate over the original ones, and this win rate can be further improved to 65.9% after applying the revision for five iterations.
"What do others think?": Task-Oriented Conversational Modeling with Subjective Knowledge
May 20, 2023



Task-oriented Dialogue (TOD) Systems aim to build dialogue systems that assist users in accomplishing specific goals, such as booking a hotel or a restaurant. Traditional TODs rely on domain-specific APIs/DBs or external factual knowledge to generate responses, which cannot accommodate subjective user requests (e.g., "Is the WIFI reliable?" or "Does the restaurant have a good atmosphere?"). To address this issue, we propose a novel task of subjective-knowledge-based TOD (SK-TOD). We also propose the first corresponding dataset, which contains subjective knowledge-seeking dialogue contexts and manually annotated responses grounded in subjective knowledge sources. When evaluated with existing TOD approaches, we find that this task poses new challenges such as aggregating diverse opinions from multiple knowledge snippets. We hope this task and dataset can promote further research on TOD and subjective content understanding. The code and the dataset are available at https://github.com/alexa/dstc11-track5.
KILM: Knowledge Injection into Encoder-Decoder Language Models
Feb 17, 2023



Large pre-trained language models (PLMs) have been shown to retain implicit knowledge within their parameters. To enhance this implicit knowledge, we propose Knowledge Injection into Language Models (KILM), a novel approach that injects entity-related knowledge into encoder-decoder PLMs, via a generative knowledge infilling objective through continued pre-training. This is done without architectural modifications to the PLMs or adding additional parameters. Experimental results over a suite of knowledge-intensive tasks spanning numerous datasets show that KILM enables models to retain more knowledge and hallucinate less, while preserving their original performance on general NLU and NLG tasks. KILM also demonstrates improved zero-shot performances on tasks such as entity disambiguation, outperforming state-of-the-art models having 30x more parameters.
Role of Bias Terms in Dot-Product Attention
Feb 16, 2023Dot-product attention is a core module in the present generation of neural network models, particularly transformers, and is being leveraged across numerous areas such as natural language processing and computer vision. This attention module is comprised of three linear transformations, namely query, key, and value linear transformations, each of which has a bias term. In this work, we study the role of these bias terms, and mathematically show that the bias term of the key linear transformation is redundant and could be omitted without any impact on the attention module. Moreover, we argue that the bias term of the value linear transformation has a more prominent role than that of the bias term of the query linear transformation. We empirically verify these findings through multiple experiments on language modeling, natural language understanding, and natural language generation tasks.
Selective In-Context Data Augmentation for Intent Detection using Pointwise V-Information
Feb 10, 2023

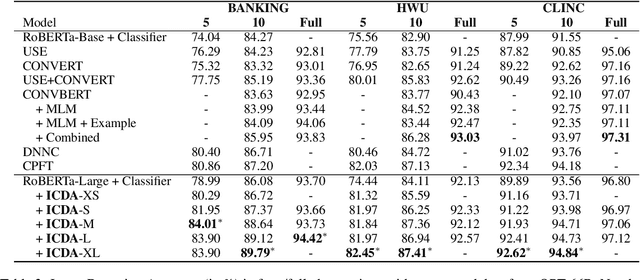
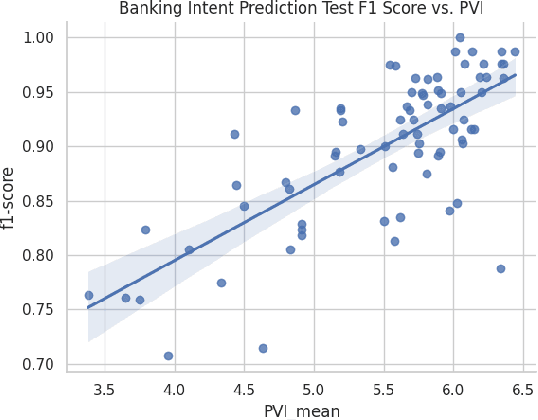
This work focuses on in-context data augmentation for intent detection. Having found that augmentation via in-context prompting of large pre-trained language models (PLMs) alone does not improve performance, we introduce a novel approach based on PLMs and pointwise V-information (PVI), a metric that can measure the usefulness of a datapoint for training a model. Our method first fine-tunes a PLM on a small seed of training data and then synthesizes new datapoints - utterances that correspond to given intents. It then employs intent-aware filtering, based on PVI, to remove datapoints that are not helpful to the downstream intent classifier. Our method is thus able to leverage the expressive power of large language models to produce diverse training data. Empirical results demonstrate that our method can produce synthetic training data that achieve state-of-the-art performance on three challenging intent detection datasets under few-shot settings (1.28% absolute improvement in 5-shot and 1.18% absolute in 10-shot, on average) and perform on par with the state-of-the-art in full-shot settings (within 0.01% absolute, on average).
Inducer-tuning: Connecting Prefix-tuning and Adapter-tuning
Oct 26, 2022



Prefix-tuning, or more generally continuous prompt tuning, has become an essential paradigm of parameter-efficient transfer learning. Using a large pre-trained language model (PLM), prefix-tuning can obtain strong performance by training only a small portion of parameters. In this paper, we propose to understand and further develop prefix-tuning through the kernel lens. Specifically, we make an analogy between \textit{prefixes} and \textit{inducing variables} in kernel methods and hypothesize that \textit{prefixes} serving as \textit{inducing variables} would improve their overall mechanism. From the kernel estimator perspective, we suggest a new variant of prefix-tuning -- \textit{inducer-tuning}, which shares the exact mechanism as prefix-tuning while leveraging the residual form found in adapter-tuning. This mitigates the initialization issue in prefix-tuning. Through comprehensive empirical experiments on natural language understanding and generation tasks, we demonstrate that inducer-tuning can close the performance gap between prefix-tuning and fine-tuning.
Empowering parameter-efficient transfer learning by recognizing the kernel structure in self-attention
May 07, 2022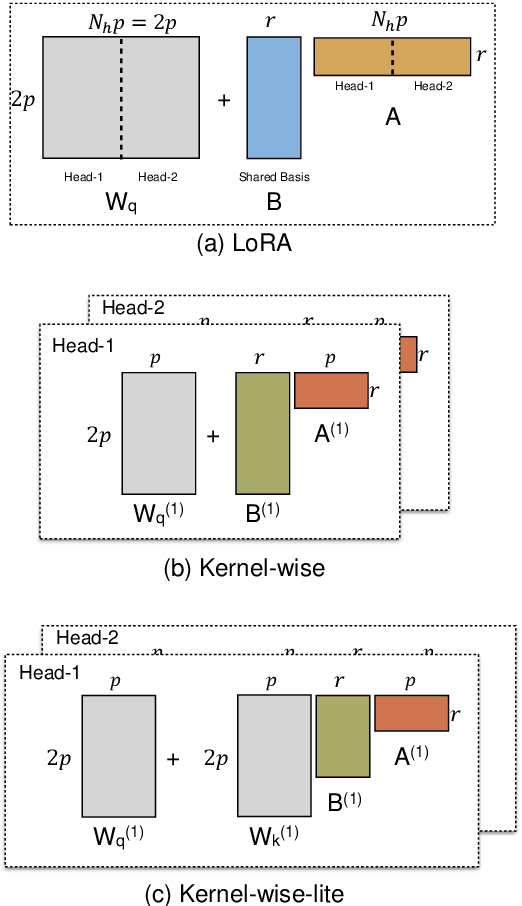
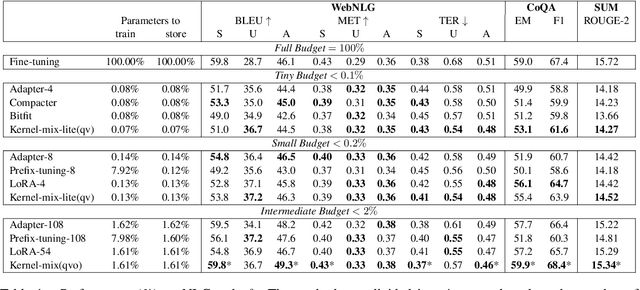
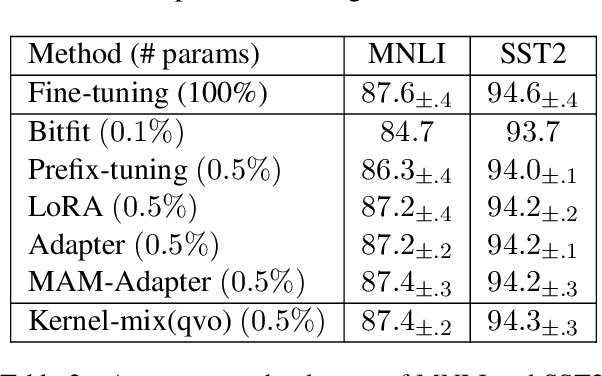
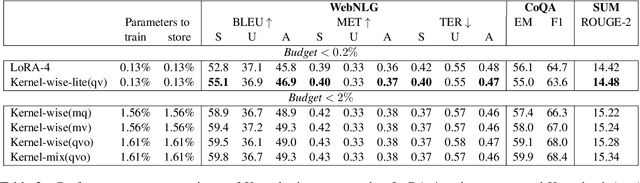
The massive amount of trainable parameters in the pre-trained language models (PLMs) makes them hard to be deployed to multiple downstream tasks. To address this issue, parameter-efficient transfer learning methods have been proposed to tune only a few parameters during fine-tuning while freezing the rest. This paper looks at existing methods along this line through the \textit{kernel lens}. Motivated by the connection between self-attention in transformer-based PLMs and kernel learning, we propose \textit{kernel-wise adapters}, namely \textit{Kernel-mix}, that utilize the kernel structure in self-attention to guide the assignment of the tunable parameters. These adapters use guidelines found in classical kernel learning and enable separate parameter tuning for each attention head. Our empirical results, over a diverse set of natural language generation and understanding tasks, show that our proposed adapters can attain or improve the strong performance of existing baselines.
Zero-Shot Controlled Generation with Encoder-Decoder Transformers
Jun 15, 2021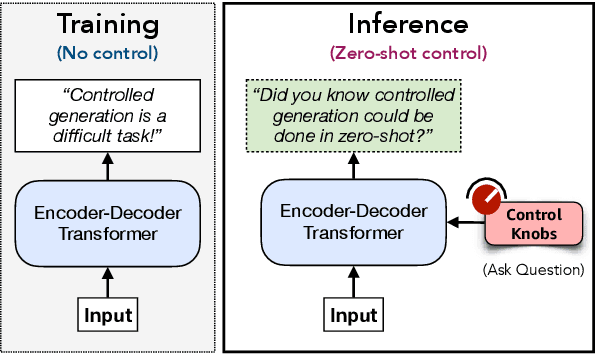

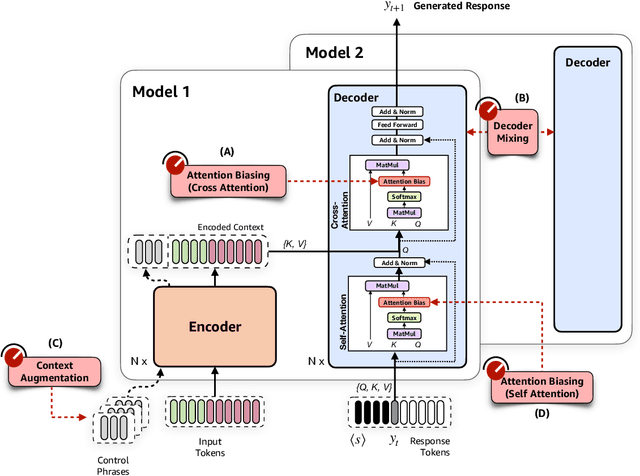

Controlling neural network-based models for natural language generation (NLG) has broad applications in numerous areas such as machine translation, document summarization, and dialog systems. Approaches that enable such control in a zero-shot manner would be of great importance as, among other reasons, they remove the need for additional annotated data and training. In this work, we propose novel approaches for controlling encoder-decoder transformer-based NLG models in zero-shot. This is done by introducing three control knobs, namely, attention biasing, decoder mixing, and context augmentation, that are applied to these models at generation time. These knobs control the generation process by directly manipulating trained NLG models (e.g., biasing cross-attention layers) to realize the desired attributes in the generated outputs. We show that not only are these NLG models robust to such manipulations, but also their behavior could be controlled without an impact on their generation performance. These results, to the best of our knowledge, are the first of their kind. Through these control knobs, we also investigate the role of transformer decoder's self-attention module and show strong evidence that its primary role is maintaining fluency of sentences generated by these models. Based on this hypothesis, we show that alternative architectures for transformer decoders could be viable options. We also study how this hypothesis could lead to more efficient ways for training encoder-decoder transformer models.