 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Controlled Generation with Encoder-Decoder Transformers
Paper and Code
Jun 15, 2021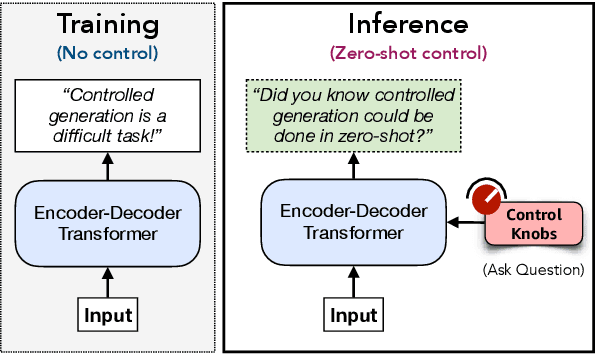

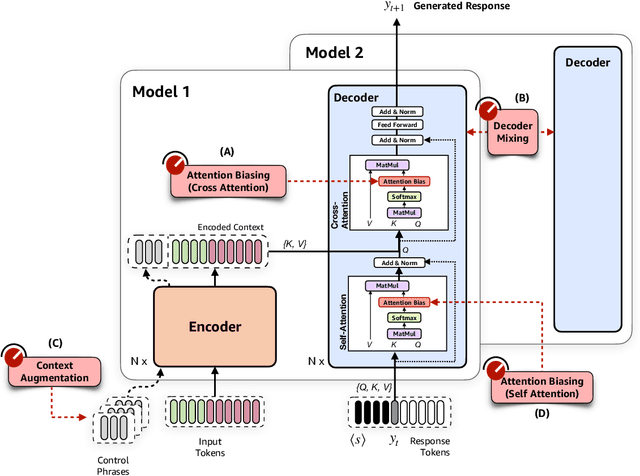

Controlling neural network-based models for natural language generation (NLG) has broad applications in numerous areas such as machine translation, document summarization, and dialog systems. Approaches that enable such control in a zero-shot manner would be of great importance as, among other reasons, they remove the need for additional annotated data and training. In this work, we propose novel approaches for controlling encoder-decoder transformer-based NLG models in zero-shot. This is done by introducing three control knobs, namely, attention biasing, decoder mixing, and context augmentation, that are applied to these models at generation time. These knobs control the generation process by directly manipulating trained NLG models (e.g., biasing cross-attention layers) to realize the desired attributes in the generated outputs. We show that not only are these NLG models robust to such manipulations, but also their behavior could be controlled without an impact on their generation performance. These results, to the best of our knowledge, are the first of their kind. Through these control knobs, we also investigate the role of transformer decoder's self-attention module and show strong evidence that its primary role is maintaining fluency of sentences generated by these models. Based on this hypothesis, we show that alternative architectures for transformer decoders could be viable options. We also study how this hypothesis could lead to more efficient ways for training encoder-decoder transformer models.