 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedefining Proactivity for Information Seeking Dialogue
Oct 20, 2024



Information-Seeking Dialogue (ISD) agents aim to provide accurate responses to user queries. While proficient in directly addressing user queries, these agents, as well as LLMs in general, predominantly exhibit reactive behavior, lacking the ability to generate proactive responses that actively engage users in sustained conversations. However, existing definitions of proactive dialogue in this context do not focus on how each response actively engages the user and sustains the conversation. Hence, we present a new definition of proactivity that focuses on enhancing the `proactiveness' of each generated response via the introduction of new information related to the initial query. To this end, we construct a proactive dialogue dataset comprising 2,000 single-turn conversations, and introduce several automatic metrics to evaluate response `proactiveness' which achieved high correlation with human annotation. Additionally, we introduce two innovative Chain-of-Thought (CoT) prompts, the 3-step CoT and the 3-in-1 CoT prompts, which consistently outperform standard prompts by up to 90% in the zero-shot setting.
CESAR: Automatic Induction of Compositional Instructions for Multi-turn Dialogs
Nov 29, 2023Instruction-based multitasking has played a critical role in the success of large language models (LLMs) in multi-turn dialog applications. While publicly available LLMs have shown promising performance, when exposed to complex instructions with multiple constraints, they lag against state-of-the-art models like ChatGPT. In this work, we hypothesize that the availability of large-scale complex demonstrations is crucial in bridging this gap. Focusing on dialog applications, we propose a novel framework, CESAR, that unifies a large number of dialog tasks in the same format and allows programmatic induction of complex instructions without any manual effort. We apply CESAR on InstructDial, a benchmark for instruction-based dialog tasks. We further enhance InstructDial with new datasets and tasks and utilize CESAR to induce complex tasks with compositional instructions. This results in a new benchmark called InstructDial++, which includes 63 datasets with 86 basic tasks and 68 composite tasks. Through rigorous experiments, we demonstrate the scalability of CESAR in providing rich instructions. Models trained on InstructDial++ can follow compositional prompts, such as prompts that ask for multiple stylistic constraints.
"What do others think?": Task-Oriented Conversational Modeling with Subjective Knowledge
May 20, 2023



Task-oriented Dialogue (TOD) Systems aim to build dialogue systems that assist users in accomplishing specific goals, such as booking a hotel or a restaurant. Traditional TODs rely on domain-specific APIs/DBs or external factual knowledge to generate responses, which cannot accommodate subjective user requests (e.g., "Is the WIFI reliable?" or "Does the restaurant have a good atmosphere?"). To address this issue, we propose a novel task of subjective-knowledge-based TOD (SK-TOD). We also propose the first corresponding dataset, which contains subjective knowledge-seeking dialogue contexts and manually annotated responses grounded in subjective knowledge sources. When evaluated with existing TOD approaches, we find that this task poses new challenges such as aggregating diverse opinions from multiple knowledge snippets. We hope this task and dataset can promote further research on TOD and subjective content understanding. The code and the dataset are available at https://github.com/alexa/dstc11-track5.
PLACES: Prompting Language Models for Social Conversation Synthesis
Feb 17, 2023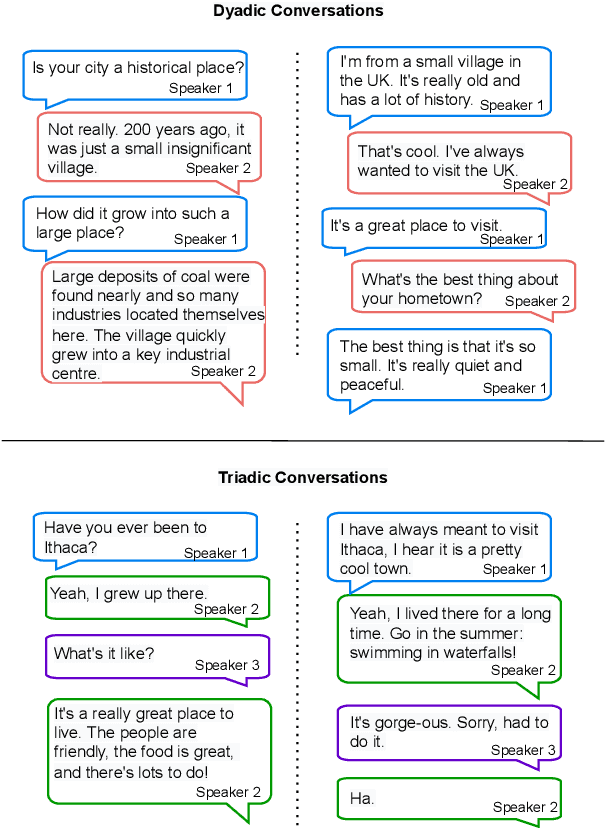
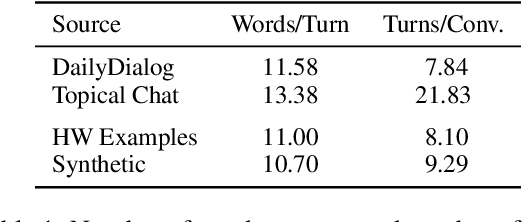
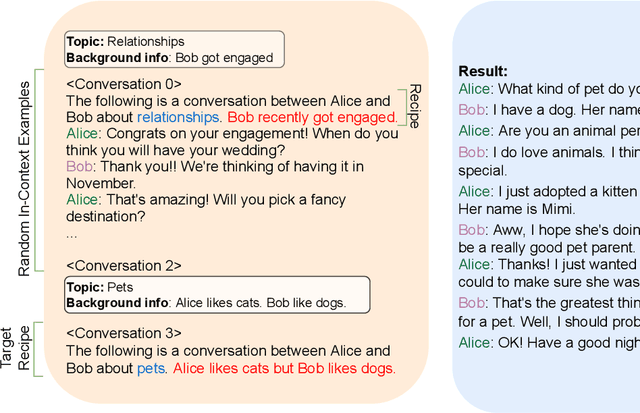
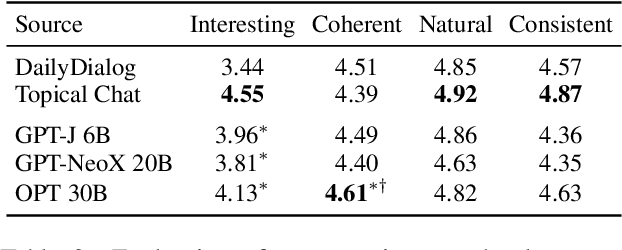
Collecting high quality conversational data can be very expensive for most applications and infeasible for others due to privacy, ethical, or similar concerns. A promising direction to tackle this problem is to generate synthetic dialogues by prompting large language models. In this work, we use a small set of expert-written conversations as in-context examples to synthesize a social conversation dataset using prompting. We perform several thorough evaluations of our synthetic conversations compared to human-collected conversations. This includes various dimensions of conversation quality with human evaluation directly on the synthesized conversations, and interactive human evaluation of chatbots fine-tuned on the synthetically generated dataset. We additionally demonstrate that this prompting approach is generalizable to multi-party conversations, providing potential to create new synthetic data for multi-party tasks. Our synthetic multi-party conversations were rated more favorably across all measured dimensions compared to conversation excerpts sampled from a human-collected multi-party dataset.
Selective In-Context Data Augmentation for Intent Detection using Pointwise V-Information
Feb 10, 2023

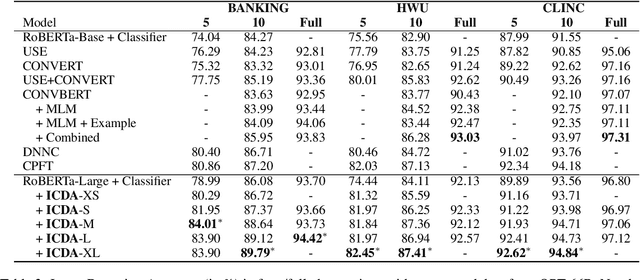
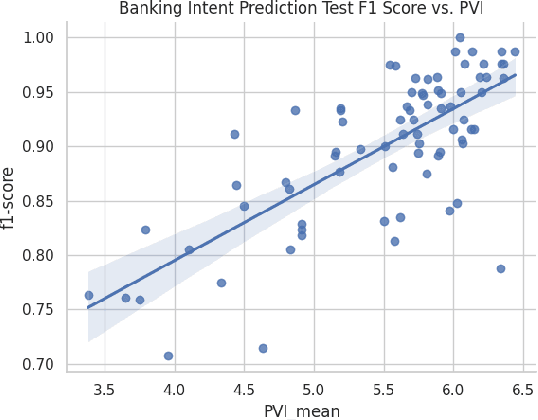
This work focuses on in-context data augmentation for intent detection. Having found that augmentation via in-context prompting of large pre-trained language models (PLMs) alone does not improve performance, we introduce a novel approach based on PLMs and pointwise V-information (PVI), a metric that can measure the usefulness of a datapoint for training a model. Our method first fine-tunes a PLM on a small seed of training data and then synthesizes new datapoints - utterances that correspond to given intents. It then employs intent-aware filtering, based on PVI, to remove datapoints that are not helpful to the downstream intent classifier. Our method is thus able to leverage the expressive power of large language models to produce diverse training data. Empirical results demonstrate that our method can produce synthetic training data that achieve state-of-the-art performance on three challenging intent detection datasets under few-shot settings (1.28% absolute improvement in 5-shot and 1.18% absolute in 10-shot, on average) and perform on par with the state-of-the-art in full-shot settings (within 0.01% absolute, on average).
Weakly Supervised Data Augmentation Through Prompting for Dialogue Understanding
Nov 02, 2022



Dialogue understanding tasks often necessitate abundant annotated data to achieve good performance and that presents challenges in low-resource settings. To alleviate this barrier, we explore few-shot data augmentation for dialogue understanding by prompting large pre-trained language models and present a novel approach that iterates on augmentation quality by applying weakly-supervised filters. We evaluate our methods on the emotion and act classification tasks in DailyDialog and the intent classification task in Facebook Multilingual Task-Oriented Dialogue. Models fine-tuned on our augmented data mixed with few-shot ground truth data are able to approach or surpass existing state-of-the-art performance on both datasets. For DailyDialog specifically, using 10% of the ground truth data we outperform the current state-of-the-art model which uses 100% of the data.
Knowledge-Grounded Conversational Data Augmentation with Generative Conversational Networks
Jul 22, 2022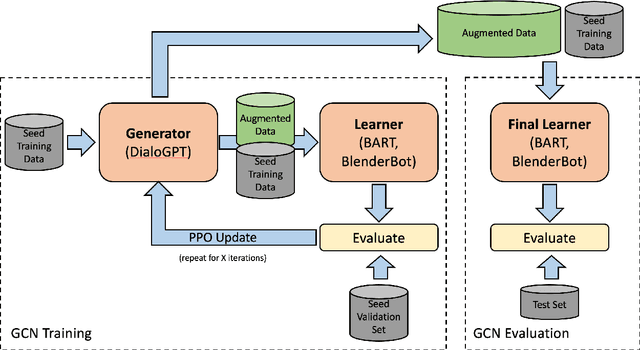
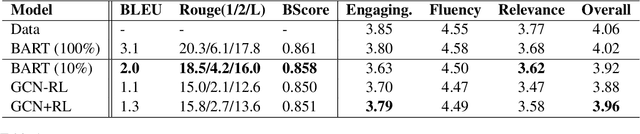
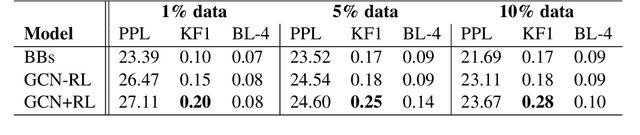

While rich, open-domain textual data are generally available and may include interesting phenomena (humor, sarcasm, empathy, etc.) most are designed for language processing tasks, and are usually in a non-conversational format. In this work, we take a step towards automatically generating conversational data using Generative Conversational Networks, aiming to benefit from the breadth of available language and knowledge data, and train open domain social conversational agents. We evaluate our approach on conversations with and without knowledge on the Topical Chat dataset using automatic metrics and human evaluators. Our results show that for conversations without knowledge grounding, GCN can generalize from the seed data, producing novel conversations that are less relevant but more engaging and for knowledge-grounded conversations, it can produce more knowledge-focused, fluent, and engaging conversations. Specifically, we show that for open-domain conversations with 10\% of seed data, our approach performs close to the baseline that uses 100% of the data, while for knowledge-grounded conversations, it achieves the same using only 1% of the data, on human ratings of engagingness, fluency, and relevance.
Towards Textual Out-of-Domain Detection without In-Domain Labels
Mar 22, 2022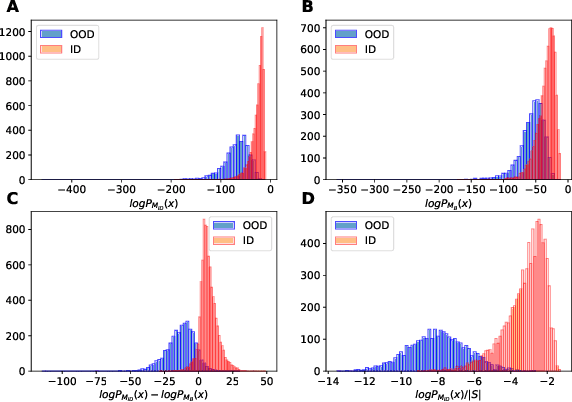
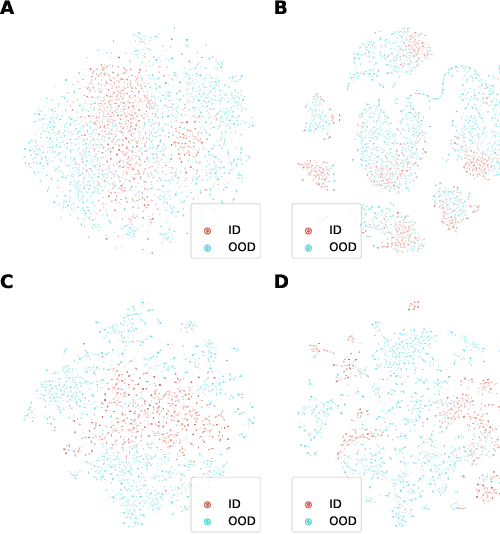
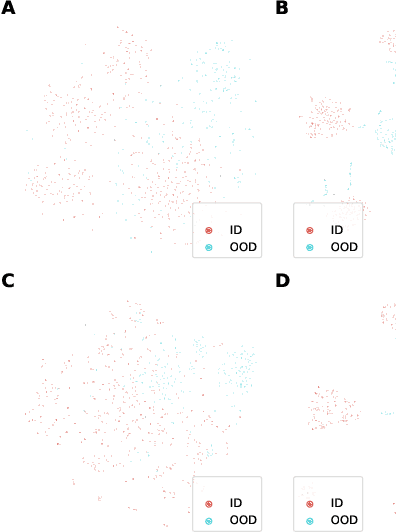
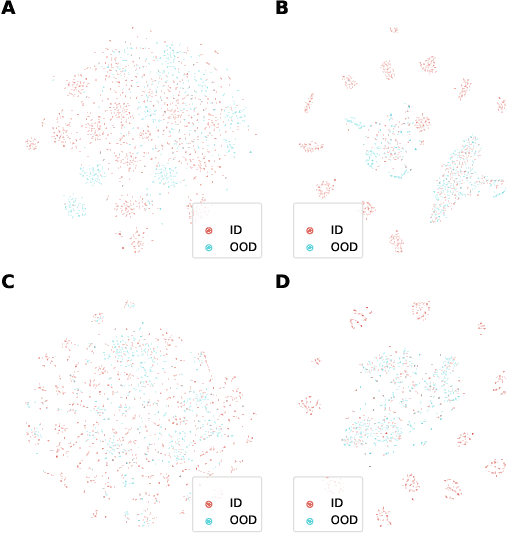
In many real-world settings, machine learning models need to identify user inputs that are out-of-domain (OOD) so as to avoid performing wrong actions. This work focuses on a challenging case of OOD detection, where no labels for in-domain data are accessible (e.g., no intent labels for the intent classification task). To this end, we first evaluate different language model based approaches that predict likelihood for a sequence of tokens. Furthermore, we propose a novel representation learning based method by combining unsupervised clustering and contrastive learning so that better data representations for OOD detection can be learned. Through extensive experiments, we demonstrate that this method can significantly outperform likelihood-based methods and can be even competitive to the state-of-the-art supervised approaches with label information.
Think Before You Speak: Using Self-talk to Generate Implicit Commonsense Knowledge for Response Generation
Oct 16, 2021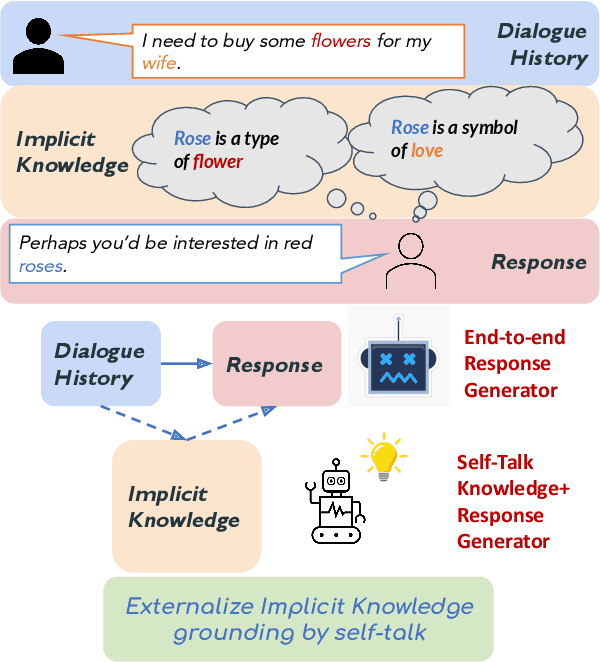
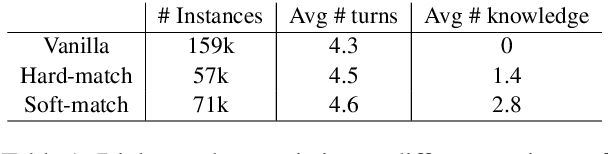
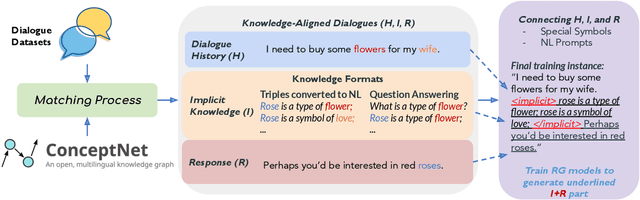

Implicit knowledge, such as common sense, is key to fluid human conversations. Current neural response generation (RG) models are trained end-to-end, omitting unstated implicit knowledge. In this paper, we present a self-talk approach that first generates the implicit commonsense knowledge and then generates response by referencing the externalized knowledge, all using one generative model. We analyze different choices to collect knowledge-aligned dialogues, represent implicit knowledge, and elicit knowledge and responses. We introduce three evaluation aspects: knowledge quality, knowledge-response connection, and response quality and perform extensive human evaluations. Our experimental results show that compared with end-to-end RG models, self-talk models that externalize the knowledge grounding process by explicitly generating implicit knowledge also produce responses that are more informative, specific, and follow common sense. We also find via human evaluation that self-talk models generate high-quality knowledge around 75% of the time. We hope that our findings encourage further work on different approaches to modeling implicit commonsense knowledge and training knowledgeable RG models.
Training Conversational Agents with Generative Conversational Networks
Oct 15, 2021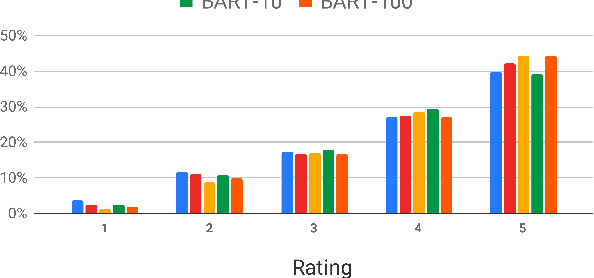

Rich, open-domain textual data available on the web resulted in great advancements for language processing. However, while that data may be suitable for language processing tasks, they are mostly non-conversational, lacking many phenomena that appear in human interactions and this is one of the reasons why we still have many unsolved challenges in conversational AI. In this work, we attempt to address this by using Generative Conversational Networks to automatically generate data and train social conversational agents. We evaluate our approach on TopicalChat with automatic metrics and human evaluators, showing that with 10% of seed data it performs close to the baseline that uses 100% of the data.