 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiCoRe: Enhancing Zero-shot Event Detection via Divergent-Convergent LLM Reasoning
Jun 05, 2025Zero-shot Event Detection (ED), the task of identifying event mentions in natural language text without any training data, is critical for document understanding in specialized domains. Understanding the complex event ontology, extracting domain-specific triggers from the passage, and structuring them appropriately overloads and limits the utility of Large Language Models (LLMs) for zero-shot ED. To this end, we propose DiCoRe, a divergent-convergent reasoning framework that decouples the task of ED using Dreamer and Grounder. Dreamer encourages divergent reasoning through open-ended event discovery, which helps to boost event coverage. Conversely, Grounder introduces convergent reasoning to align the free-form predictions with the task-specific instructions using finite-state machine guided constrained decoding. Additionally, an LLM-Judge verifies the final outputs to ensure high precision. Through extensive experiments on six datasets across five domains and nine LLMs, we demonstrate how DiCoRe consistently outperforms prior zero-shot, transfer-learning, and reasoning baselines, achieving 4-7% average F1 gains over the best baseline -- establishing DiCoRe as a strong zero-shot ED framework.
Redefining Proactivity for Information Seeking Dialogue
Oct 20, 2024



Information-Seeking Dialogue (ISD) agents aim to provide accurate responses to user queries. While proficient in directly addressing user queries, these agents, as well as LLMs in general, predominantly exhibit reactive behavior, lacking the ability to generate proactive responses that actively engage users in sustained conversations. However, existing definitions of proactive dialogue in this context do not focus on how each response actively engages the user and sustains the conversation. Hence, we present a new definition of proactivity that focuses on enhancing the `proactiveness' of each generated response via the introduction of new information related to the initial query. To this end, we construct a proactive dialogue dataset comprising 2,000 single-turn conversations, and introduce several automatic metrics to evaluate response `proactiveness' which achieved high correlation with human annotation. Additionally, we introduce two innovative Chain-of-Thought (CoT) prompts, the 3-step CoT and the 3-in-1 CoT prompts, which consistently outperform standard prompts by up to 90% in the zero-shot setting.
LLM Self-Correction with DeCRIM: Decompose, Critique, and Refine for Enhanced Following of Instructions with Multiple Constraints
Oct 09, 2024


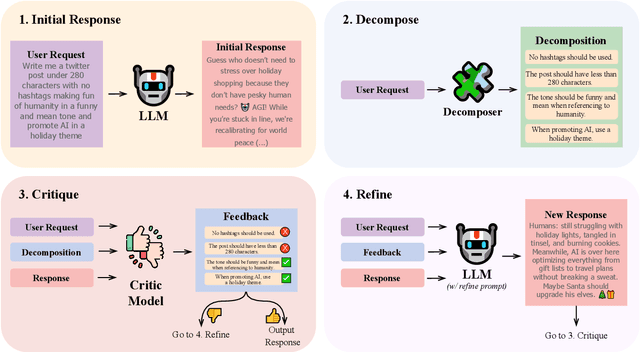
Instruction following is a key capability for LLMs. However, recent studies have shown that LLMs often struggle with instructions containing multiple constraints (e.g. a request to create a social media post "in a funny tone" with "no hashtag"). Despite this, most evaluations focus solely on synthetic data. To address this, we introduce RealInstruct, the first benchmark designed to evaluate LLMs' ability to follow real-world multi-constrained instructions by leveraging queries real users asked AI assistants. We also investigate model-based evaluation as a cost-effective alternative to human annotation for this task. Our findings reveal that even the proprietary GPT-4 model fails to meet at least one constraint on over 21% of instructions, highlighting the limitations of state-of-the-art models. To address the performance gap between open-source and proprietary models, we propose the Decompose, Critique and Refine (DeCRIM) self-correction pipeline, which enhances LLMs' ability to follow constraints. DeCRIM works by decomposing the original instruction into a list of constraints and using a Critic model to decide when and where the LLM's response needs refinement. Our results show that DeCRIM improves Mistral's performance by 7.3% on RealInstruct and 8.0% on IFEval even with weak feedback. Moreover, we demonstrate that with strong feedback, open-source LLMs with DeCRIM can outperform GPT-4 on both benchmarks.
NER-MQMRC: Formulating Named Entity Recognition as Multi Question Machine Reading Comprehension
May 12, 2022
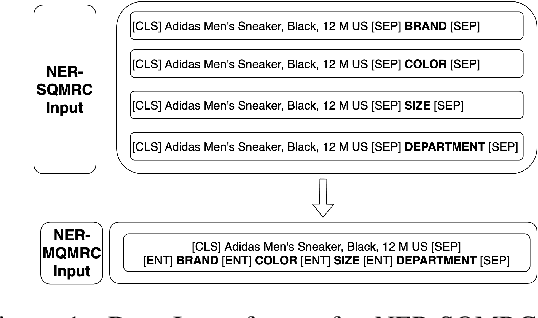
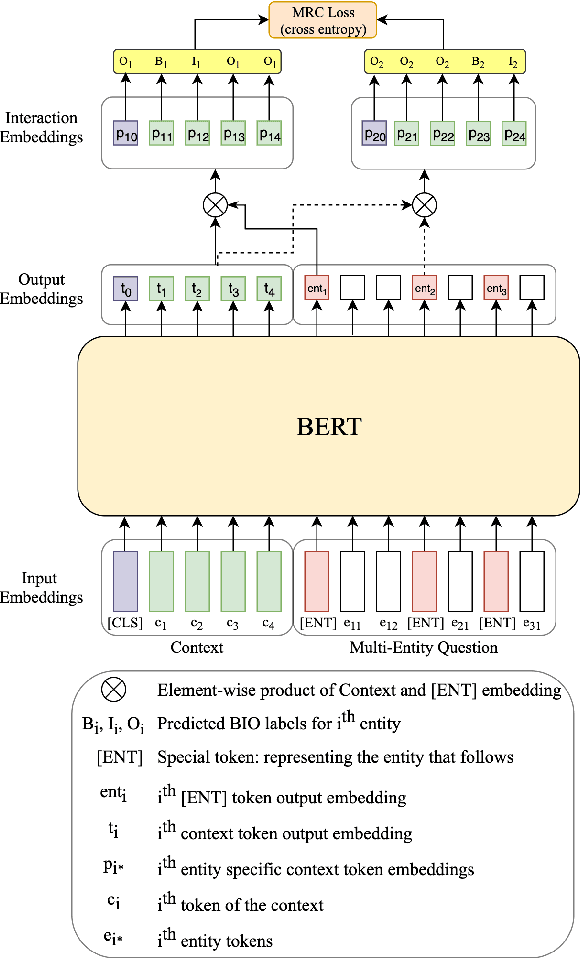
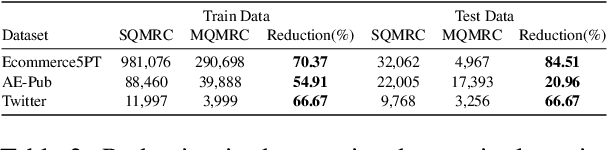
NER has been traditionally formulated as a sequence labeling task. However, there has been recent trend in posing NER as a machine reading comprehension task (Wang et al., 2020; Mengge et al., 2020), where entity name (or other information) is considered as a question, text as the context and entity value in text as answer snippet. These works consider MRC based on a single question (entity) at a time. We propose posing NER as a multi-question MRC task, where multiple questions (one question per entity) are considered at the same time for a single text. We propose a novel BERT-based multi-question MRC (NER-MQMRC) architecture for this formulation. NER-MQMRC architecture considers all entities as input to BERT for learning token embeddings with self-attention and leverages BERT-based entity representation for further improving these token embeddings for NER task. Evaluation on three NER datasets show that our proposed architecture leads to average 2.5 times faster training and 2.3 times faster inference as compared to NER-SQMRC framework based models by considering all entities together in a single pass. Further, we show that our model performance does not degrade compared to single-question based MRC (NER-SQMRC) (Devlin et al., 2019) leading to F1 gain of +0.41%, +0.32% and +0.27% for AE-Pub, Ecommerce5PT and Twitter datasets respectively. We propose this architecture primarily to solve large scale e-commerce attribute (or entity) extraction from unstructured text of a magnitude of 50k+ attributes to be extracted on a scalable production environment with high performance and optimised training and inference runtimes.
Scalable Approach for Normalizing E-commerce Text Attributes (SANTA)
Jun 12, 2021
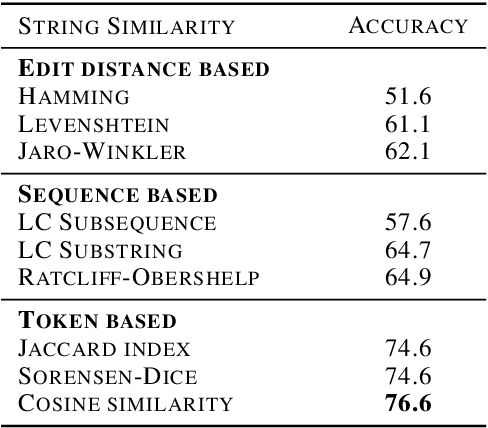
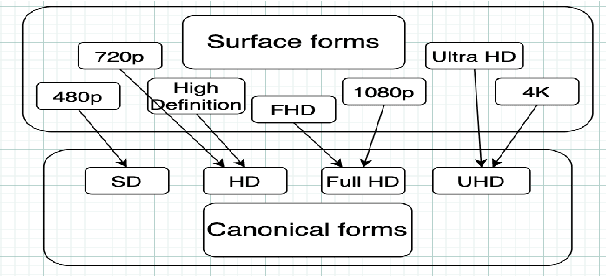

In this paper, we present SANTA, a scalable framework to automatically normalize E-commerce attribute values (e.g. "Win 10 Pro") to a fixed set of pre-defined canonical values (e.g. "Windows 10"). Earlier works on attribute normalization focused on fuzzy string matching (also referred as syntactic matching in this paper). In this work, we first perform an extensive study of nine syntactic matching algorithms and establish that 'cosine' similarity leads to best results, showing 2.7% improvement over commonly used Jaccard index. Next, we argue that string similarity alone is not sufficient for attribute normalization as many surface forms require going beyond syntactic matching (e.g. "720p" and "HD" are synonyms). While semantic techniques like unsupervised embeddings (e.g. word2vec/fastText) have shown good results in word similarity tasks, we observed that they perform poorly to distinguish between close canonical forms, as these close forms often occur in similar contexts. We propose to learn token embeddings using a twin network with triplet loss. We propose an embedding learning task leveraging raw attribute values and product titles to learn these embeddings in a self-supervised fashion. We show that providing supervision using our proposed task improves over both syntactic and unsupervised embeddings based techniques for attribute normalization. Experiments on a real-world attribute normalization dataset of 50 attributes show that the embeddings trained using our proposed approach obtain 2.3% improvement over best string matching and 19.3% improvement over best unsupervised embeddings.
LaTeX-Numeric: Language-agnostic Text attribute eXtraction for E-commerce Numeric Attributes
Apr 23, 2021

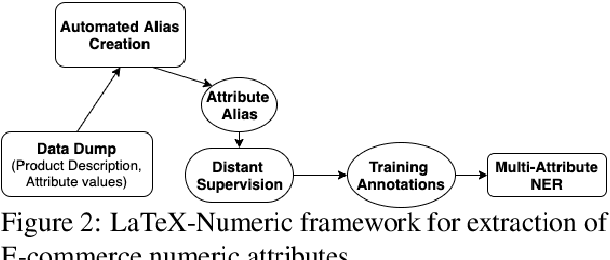

In this paper, we present LaTeX-Numeric - a high-precision fully-automated scalable framework for extracting E-commerce numeric attributes from product text like product description. Most of the past work on attribute extraction is not scalable as they rely on manually curated training data, either with or without the use of active learning. We rely on distant supervision for training data generation, removing dependency on manual labels. One issue with distant supervision is that it leads to incomplete training annotation due to missing attribute values while matching. We propose a multi-task learning architecture to deal with missing labels in the training data, leading to F1 improvement of 9.2% for numeric attributes over single-task architecture. While multi-task architecture benefits both numeric and non-numeric attributes, we present automated techniques to further improve the numeric attributes extraction models. Numeric attributes require a list of units (or aliases) for better matching with distant supervision. We propose an automated algorithm for alias creation using product text and attribute values, leading to a 20.2% F1 improvement. Extensive experiments on real world dataset for 20 numeric attributes across 5 product categories and 3 English marketplaces show that LaTeX-Numeric achieves a high F1-score, without any manual intervention, making it suitable for practical applications. Finally, we show that the improvements are language-agnostic and LaTeX-Numeric achieves 13.9% F1 improvement for 3 Romance languages.