 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling the One-to-Many Property in Open-Domain Dialogue with LLMs
Jun 18, 2025Open-domain Dialogue (OD) exhibits a one-to-many (o2m) property, whereby multiple appropriate responses exist for a single dialogue context. Despite prior research showing that modeling this property boosts response diversity, most modern LLM-based dialogue agents do not explicitly do so. In this work, we model the o2m property of OD in LLMs by decomposing OD generation into two key tasks: Multi-Response Generation (MRG) and Preference-based Selection (PS), which entail generating a set of n semantically and lexically diverse high-quality responses for a given dialogue context, followed by selecting a single response based on human preference, respectively. To facilitate MRG and PS, we introduce o2mDial, a dialogue corpus explicitly designed to capture the o2m property by featuring multiple plausible responses for each context. Leveraging o2mDial, we propose new in-context learning and instruction-tuning strategies, as well as novel evaluation metrics for MRG, alongside a model-based approach for PS. Empirical results demonstrate that applying the proposed two-stage framework to smaller LLMs for OD generation enhances overall response diversity while maintaining contextual coherence, improving response quality by up to 90%, bringing them closer to the performance of larger models.
Redefining Proactivity for Information Seeking Dialogue
Oct 20, 2024



Information-Seeking Dialogue (ISD) agents aim to provide accurate responses to user queries. While proficient in directly addressing user queries, these agents, as well as LLMs in general, predominantly exhibit reactive behavior, lacking the ability to generate proactive responses that actively engage users in sustained conversations. However, existing definitions of proactive dialogue in this context do not focus on how each response actively engages the user and sustains the conversation. Hence, we present a new definition of proactivity that focuses on enhancing the `proactiveness' of each generated response via the introduction of new information related to the initial query. To this end, we construct a proactive dialogue dataset comprising 2,000 single-turn conversations, and introduce several automatic metrics to evaluate response `proactiveness' which achieved high correlation with human annotation. Additionally, we introduce two innovative Chain-of-Thought (CoT) prompts, the 3-step CoT and the 3-in-1 CoT prompts, which consistently outperform standard prompts by up to 90% in the zero-shot setting.
Partially Randomizing Transformer Weights for Dialogue Response Diversity
Nov 18, 2023Despite recent progress in generative open-domain dialogue, the issue of low response diversity persists. Prior works have addressed this issue via either novel objective functions, alternative learning approaches such as variational frameworks, or architectural extensions such as the Randomized Link (RL) Transformer. However, these approaches typically entail either additional difficulties during training/inference, or a significant increase in model size and complexity. Hence, we propose the \underline{Pa}rtially \underline{Ra}ndomized trans\underline{Former} (PaRaFormer), a simple extension of the transformer which involves freezing the weights of selected layers after random initialization. Experimental results reveal that the performance of the PaRaformer is comparable to that of the aforementioned approaches, despite not entailing any additional training difficulty or increase in model complexity.
An Empirical Bayes Framework for Open-Domain Dialogue Generation
Nov 18, 2023To engage human users in meaningful conversation, open-domain dialogue agents are required to generate diverse and contextually coherent dialogue. Despite recent advancements, which can be attributed to the usage of pretrained language models, the generation of diverse and coherent dialogue remains an open research problem. A popular approach to address this issue involves the adaptation of variational frameworks. However, while these approaches successfully improve diversity, they tend to compromise on contextual coherence. Hence, we propose the Bayesian Open-domain Dialogue with Empirical Bayes (BODEB) framework, an empirical bayes framework for constructing an Bayesian open-domain dialogue agent by leveraging pretrained parameters to inform the prior and posterior parameter distributions. Empirical results show that BODEB achieves better results in terms of both diversity and coherence compared to variational frameworks.
Improving Contextual Coherence in Variational Personalized and Empathetic Dialogue Agents
Feb 12, 2022
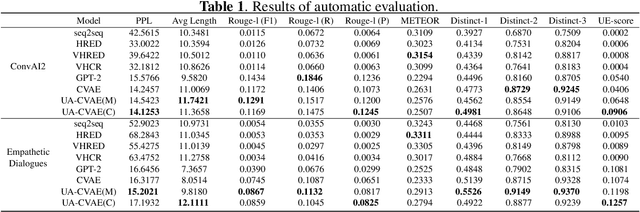

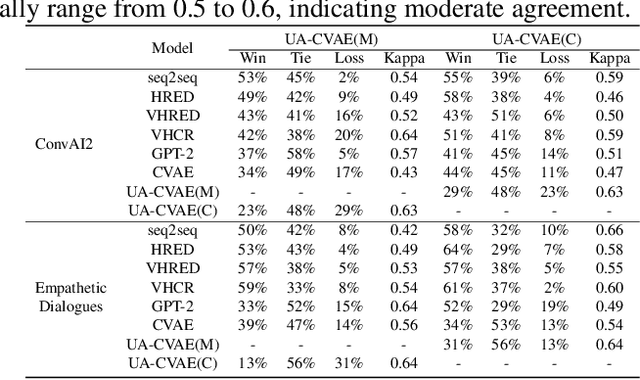
In recent years, latent variable models, such as the Conditional Variational Auto Encoder (CVAE), have been applied to both personalized and empathetic dialogue generation. Prior work have largely focused on generating diverse dialogue responses that exhibit persona consistency and empathy. However, when it comes to the contextual coherence of the generated responses, there is still room for improvement. Hence, to improve the contextual coherence, we propose a novel Uncertainty Aware CVAE (UA-CVAE) framework. The UA-CVAE framework involves approximating and incorporating the aleatoric uncertainty during response generation. We apply our framework to both personalized and empathetic dialogue generation. Empirical results show that our framework significantly improves the contextual coherence of the generated response. Additionally, we introduce a novel automatic metric for measuring contextual coherence, which was found to correlate positively with human judgement.
DLVGen: A Dual Latent Variable Approach to Personalized Dialogue Generation
Nov 22, 2021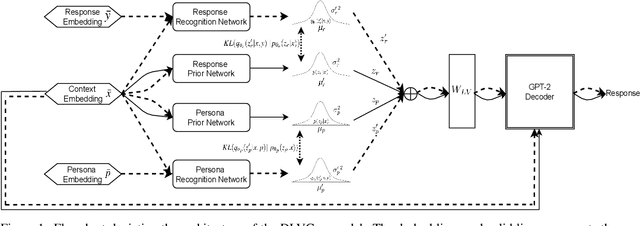
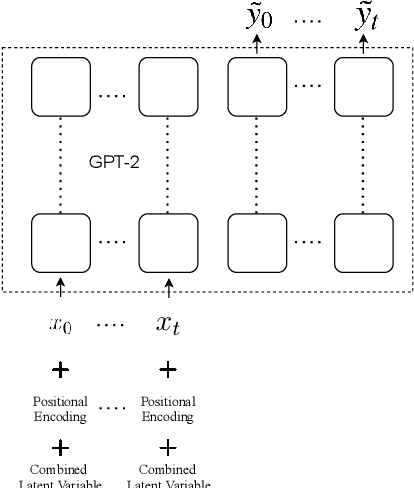

The generation of personalized dialogue is vital to natural and human-like conversation. Typically, personalized dialogue generation models involve conditioning the generated response on the dialogue history and a representation of the persona/personality of the interlocutor. As it is impractical to obtain the persona/personality representations for every interlocutor, recent works have explored the possibility of generating personalized dialogue by finetuning the model with dialogue examples corresponding to a given persona instead. However, in real-world implementations, a sufficient number of corresponding dialogue examples are also rarely available. Hence, in this paper, we propose a Dual Latent Variable Generator (DLVGen) capable of generating personalized dialogue in the absence of any persona/personality information or any corresponding dialogue examples. Unlike prior work, DLVGen models the latent distribution over potential responses as well as the latent distribution over the agent's potential persona. During inference, latent variables are sampled from both distributions and fed into the decoder. Empirical results show that DLVGen is capable of generating diverse responses which accurately incorporate the agent's persona.
Generating Personalized Dialogue via Multi-Task Meta-Learning
Aug 07, 2021
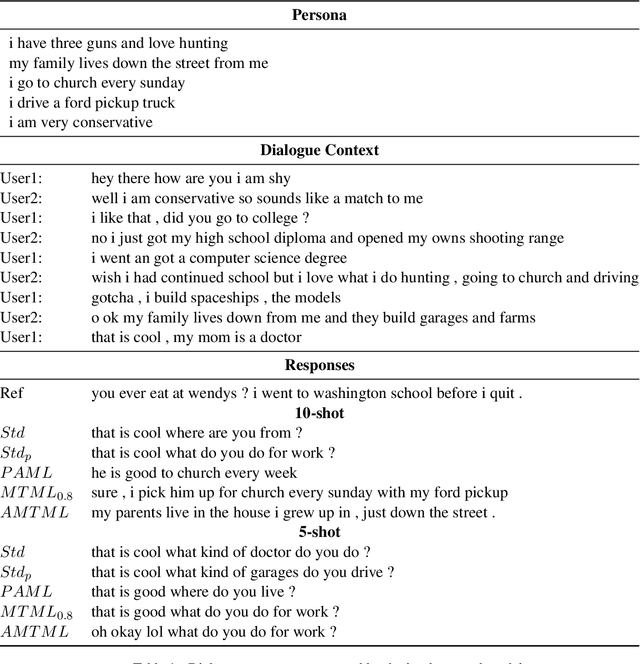
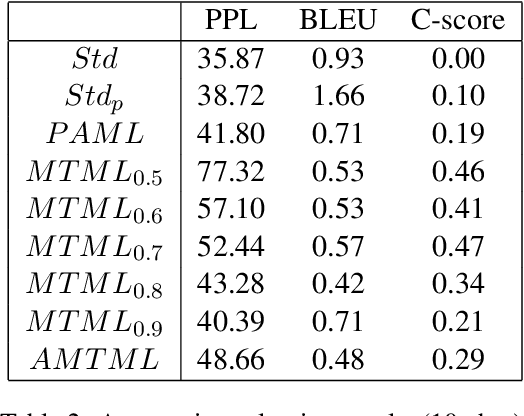
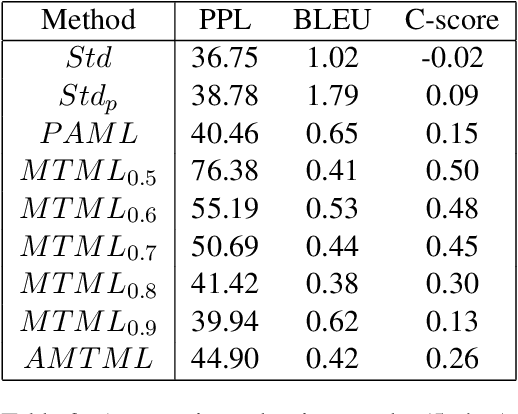
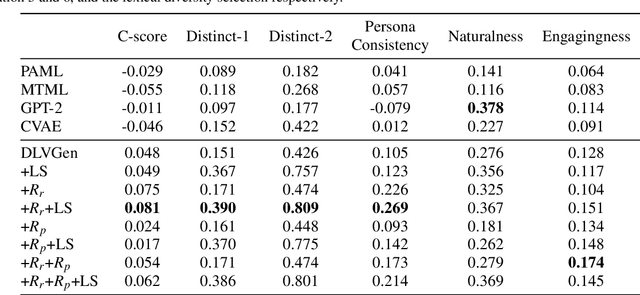
Conventional approaches to personalized dialogue generation typically require a large corpus, as well as predefined persona information. However, in a real-world setting, neither a large corpus of training data nor persona information are readily available. To address these practical limitations, we propose a novel multi-task meta-learning approach which involves training a model to adapt to new personas without relying on a large corpus, or on any predefined persona information. Instead, the model is tasked with generating personalized responses based on only the dialogue context. Unlike prior work, our approach leverages on the provided persona information only during training via the introduction of an auxiliary persona reconstruction task. In this paper, we introduce 2 frameworks that adopt the proposed multi-task meta-learning approach: the Multi-Task Meta-Learning (MTML) framework, and the Alternating Multi-Task Meta-Learning (AMTML) framework. Experimental results show that utilizing MTML and AMTML results in dialogue responses with greater persona consistency.