 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Contextual Coherence in Variational Personalized and Empathetic Dialogue Agents
Feb 12, 2022
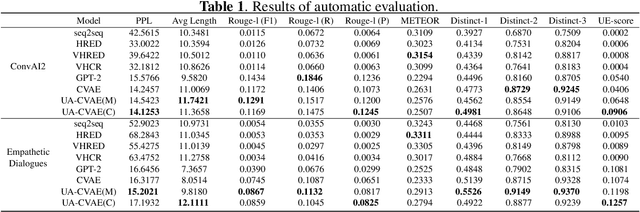

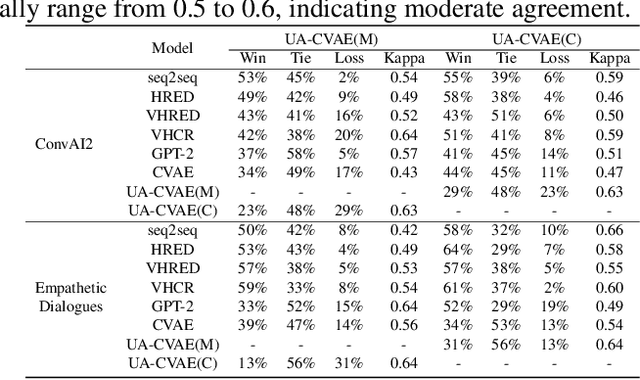
In recent years, latent variable models, such as the Conditional Variational Auto Encoder (CVAE), have been applied to both personalized and empathetic dialogue generation. Prior work have largely focused on generating diverse dialogue responses that exhibit persona consistency and empathy. However, when it comes to the contextual coherence of the generated responses, there is still room for improvement. Hence, to improve the contextual coherence, we propose a novel Uncertainty Aware CVAE (UA-CVAE) framework. The UA-CVAE framework involves approximating and incorporating the aleatoric uncertainty during response generation. We apply our framework to both personalized and empathetic dialogue generation. Empirical results show that our framework significantly improves the contextual coherence of the generated response. Additionally, we introduce a novel automatic metric for measuring contextual coherence, which was found to correlate positively with human judgement.
DLVGen: A Dual Latent Variable Approach to Personalized Dialogue Generation
Nov 22, 2021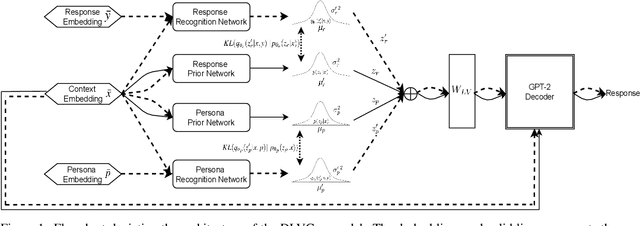
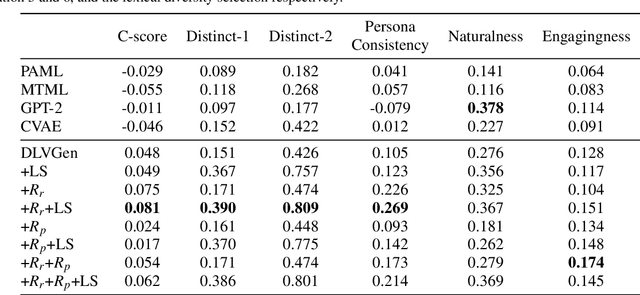
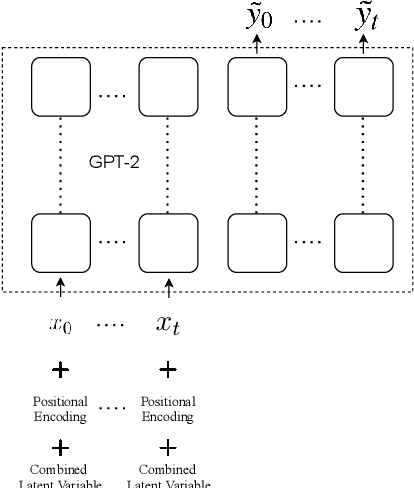

The generation of personalized dialogue is vital to natural and human-like conversation. Typically, personalized dialogue generation models involve conditioning the generated response on the dialogue history and a representation of the persona/personality of the interlocutor. As it is impractical to obtain the persona/personality representations for every interlocutor, recent works have explored the possibility of generating personalized dialogue by finetuning the model with dialogue examples corresponding to a given persona instead. However, in real-world implementations, a sufficient number of corresponding dialogue examples are also rarely available. Hence, in this paper, we propose a Dual Latent Variable Generator (DLVGen) capable of generating personalized dialogue in the absence of any persona/personality information or any corresponding dialogue examples. Unlike prior work, DLVGen models the latent distribution over potential responses as well as the latent distribution over the agent's potential persona. During inference, latent variables are sampled from both distributions and fed into the decoder. Empirical results show that DLVGen is capable of generating diverse responses which accurately incorporate the agent's persona.
Generating Personalized Dialogue via Multi-Task Meta-Learning
Aug 07, 2021
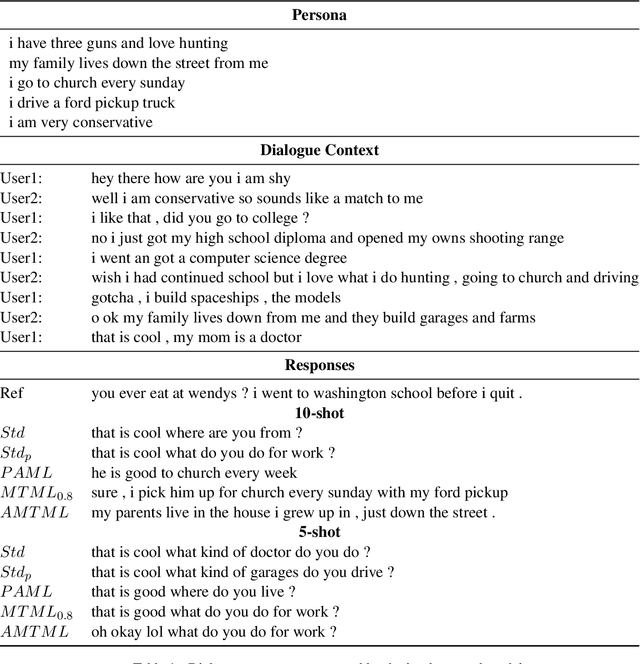
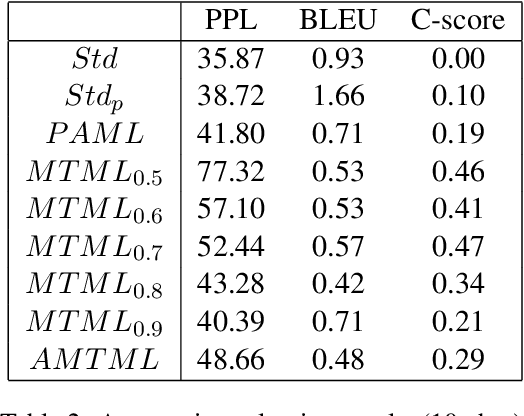
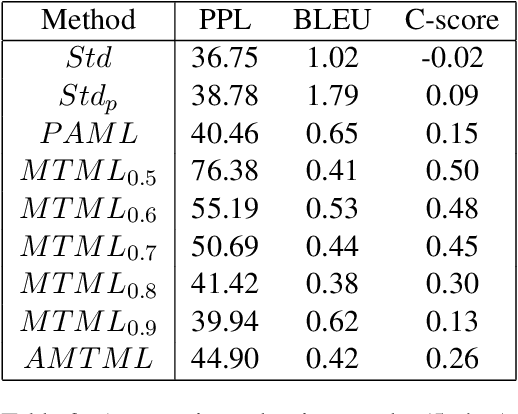
Conventional approaches to personalized dialogue generation typically require a large corpus, as well as predefined persona information. However, in a real-world setting, neither a large corpus of training data nor persona information are readily available. To address these practical limitations, we propose a novel multi-task meta-learning approach which involves training a model to adapt to new personas without relying on a large corpus, or on any predefined persona information. Instead, the model is tasked with generating personalized responses based on only the dialogue context. Unlike prior work, our approach leverages on the provided persona information only during training via the introduction of an auxiliary persona reconstruction task. In this paper, we introduce 2 frameworks that adopt the proposed multi-task meta-learning approach: the Multi-Task Meta-Learning (MTML) framework, and the Alternating Multi-Task Meta-Learning (AMTML) framework. Experimental results show that utilizing MTML and AMTML results in dialogue responses with greater persona consistency.
Improving Polyphonic Sound Event Detection on Multichannel Recordings with the Sørensen-Dice Coefficient Loss and Transfer Learning
Jul 22, 2021
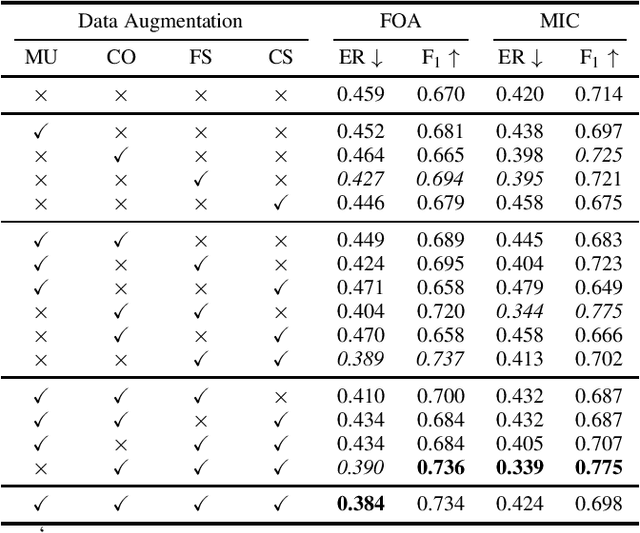
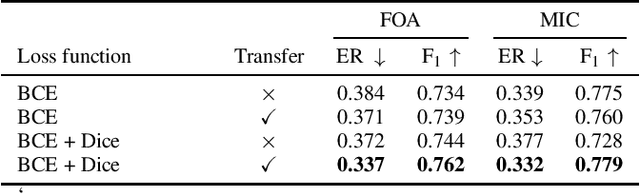

The S{\o}rensen--Dice Coefficient has recently seen rising popularity as a loss function (also known as Dice loss) due to its robustness in tasks where the number of negative samples significantly exceeds that of positive samples, such as semantic segmentation, natural language processing, and sound event detection. Conventional training of polyphonic sound event detection systems with binary cross-entropy loss often results in suboptimal detection performance as the training is often overwhelmed by updates from negative samples. In this paper, we investigated the effect of the Dice loss, intra- and inter-modal transfer learning, data augmentation, and recording formats, on the performance of polyphonic sound event detection systems with multichannel inputs. Our analysis showed that polyphonic sound event detection systems trained with Dice loss consistently outperformed those trained with cross-entropy loss across different training settings and recording formats in terms of F1 score and error rate. We achieved further performance gains via the use of transfer learning and an appropriate combination of different data augmentation techniques.
What Makes Sound Event Localization and Detection Difficult? Insights from Error Analysis
Jul 22, 2021
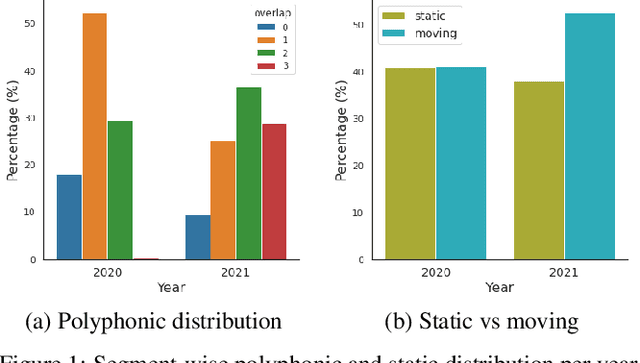
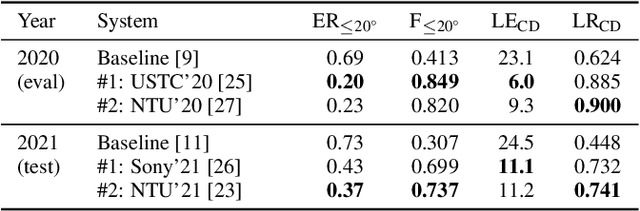
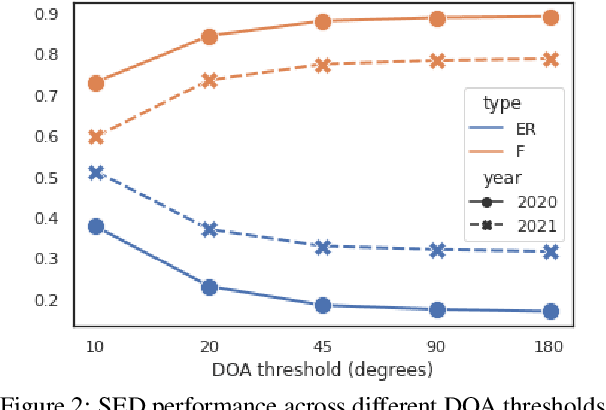
Sound event localization and detection (SELD) is an emerging research topic that aims to unify the tasks of sound event detection and direction-of-arrival estimation. As a result, SELD inherits the challenges of both tasks, such as noise, reverberation, interference, polyphony, and non-stationarity of sound sources. Furthermore, SELD often faces an additional challenge of assigning correct correspondences between the detected sound classes and directions of arrival to multiple overlapping sound events. Previous studies have shown that unknown interferences in reverberant environments often cause major degradation in the performance of SELD systems. To further understand the challenges of the SELD task, we performed a detailed error analysis on two of our SELD systems, which both ranked second in the team category of DCASE SELD Challenge, one in 2020 and one in 2021. Experimental results indicate polyphony as the main challenge in SELD, due to the difficulty in detecting all sound events of interest. In addition, the SELD systems tend to make fewer errors for the polyphonic scenario that is dominant in the training set.
DCASE 2021 Task 3: Spectrotemporally-aligned Features for Polyphonic Sound Event Localization and Detection
Jun 29, 2021
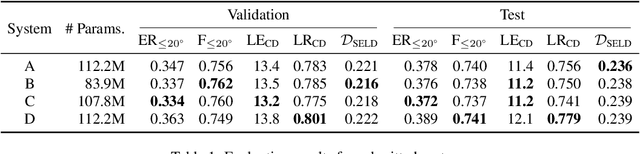
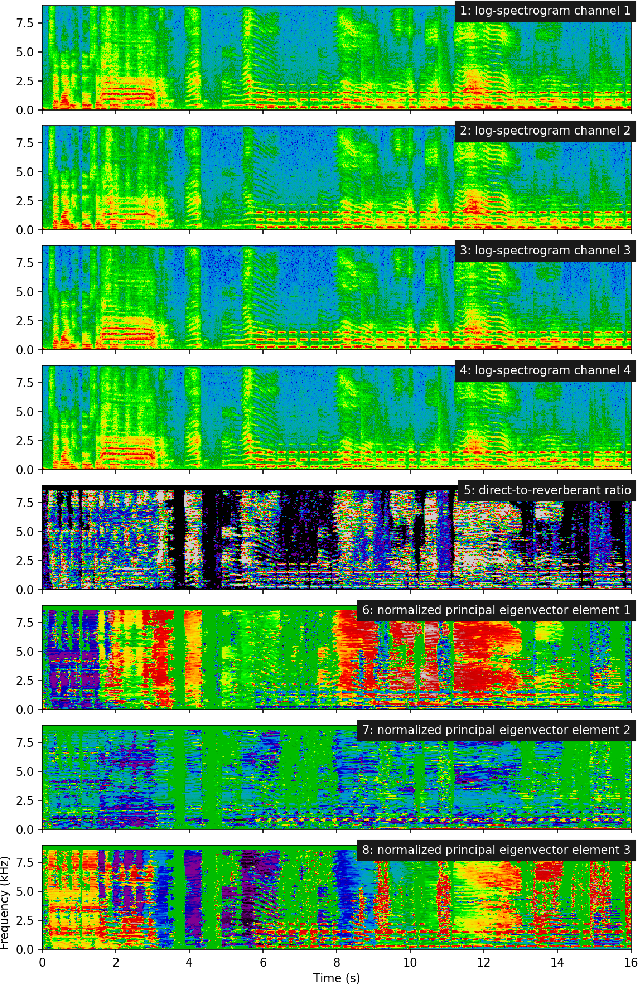
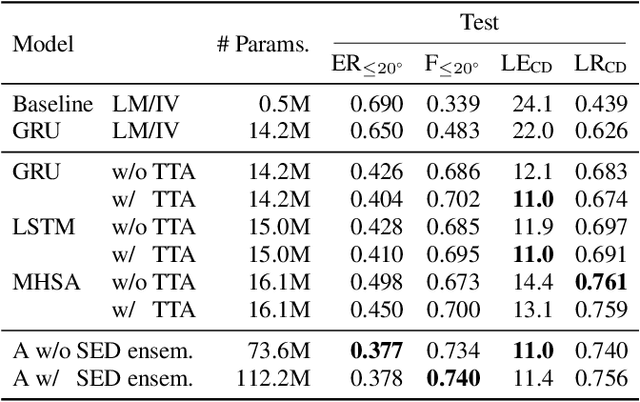
Sound event localization and detection consists of two subtasks which are sound event detection and direction-of-arrival estimation. While sound event detection mainly relies on time-frequency patterns to distinguish different sound classes, direction-of-arrival estimation uses magnitude or phase differences between microphones to estimate source directions. Therefore, it is often difficult to jointly train these two subtasks simultaneously. We propose a novel feature called spatial cue-augmented log-spectrogram (SALSA) with exact time-frequency mapping between the signal power and the source direction-of-arrival. The feature includes multichannel log-spectrograms stacked along with the estimated direct-to-reverberant ratio and a normalized version of the principal eigenvector of the spatial covariance matrix at each time-frequency bin on the spectrograms. Experimental results on the DCASE 2021 dataset for sound event localization and detection with directional interference showed that the deep learning-based models trained on this new feature outperformed the DCASE challenge baseline by a large margin. We combined several models with slightly different architectures that were trained on the new feature to further improve the system performances for the DCASE sound event localization and detection challenge.