 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALSA: Spatial Cue-Augmented Log-Spectrogram Features for Polyphonic Sound Event Localization and Detection
Oct 01, 2021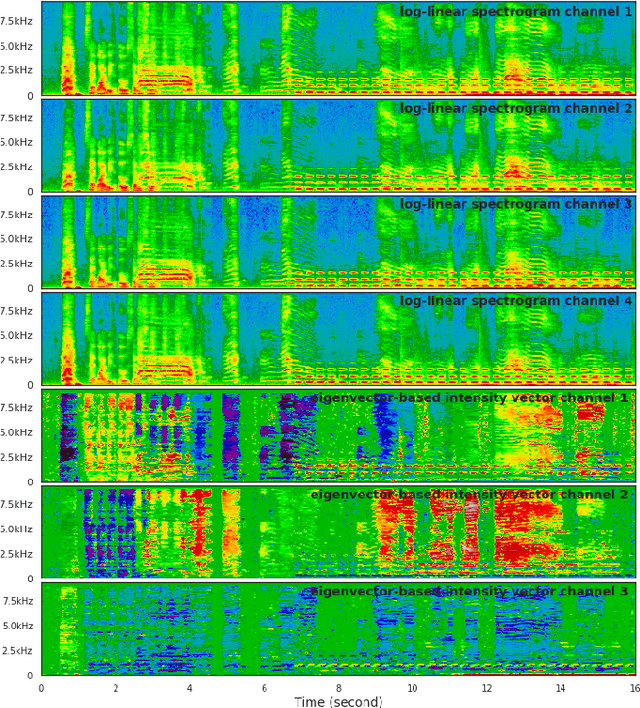
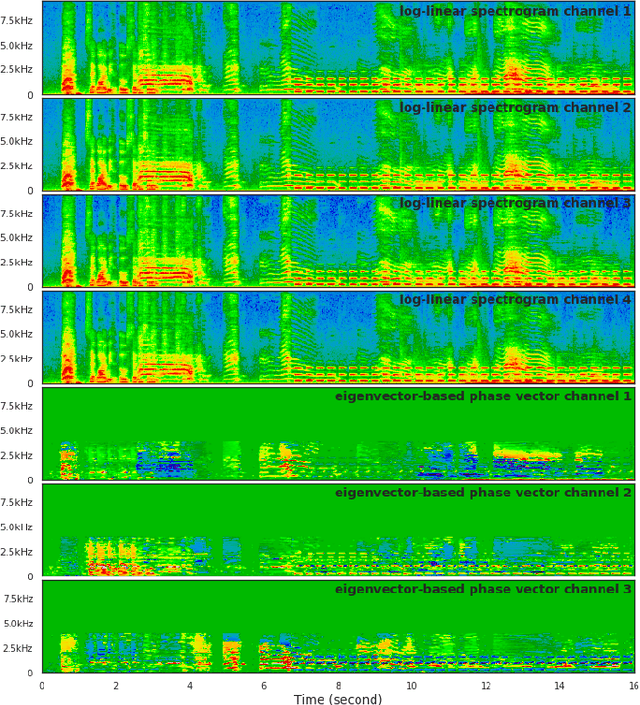
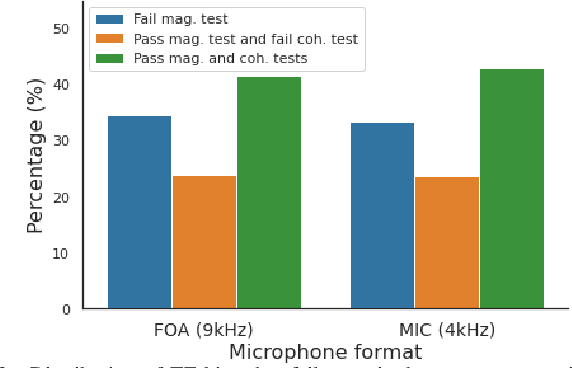
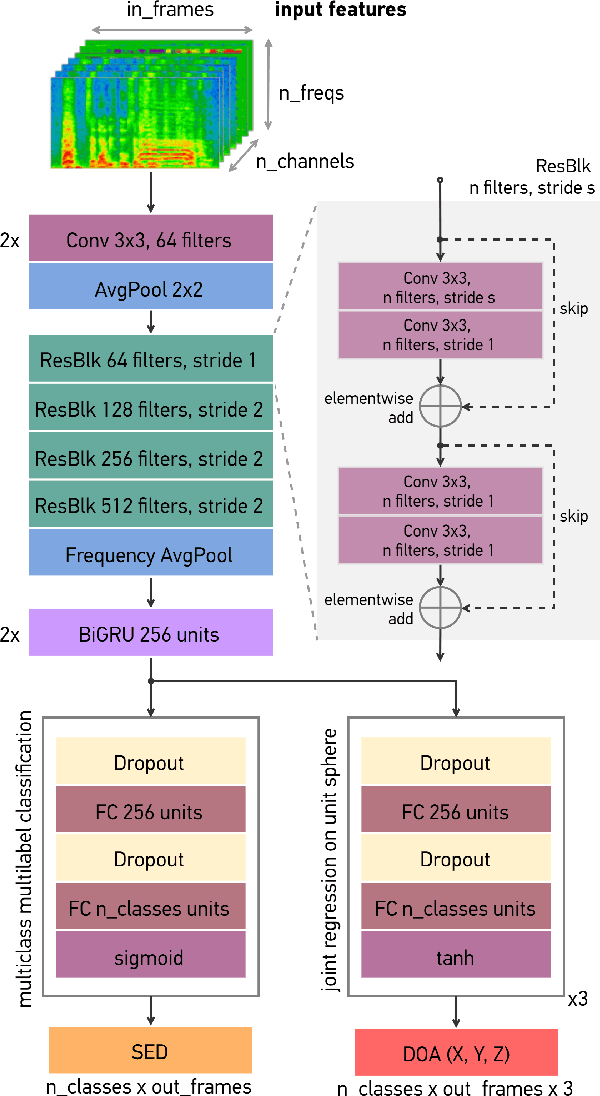
Sound event localization and detection (SELD) consists of two subtasks, which are sound event detection and direction-of-arrival estimation. While sound event detection mainly relies on time-frequency patterns to distinguish different sound classes, direction-of-arrival estimation uses amplitude and/or phase differences between microphones to estimate source directions. As a result, it is often difficult to jointly optimize these two subtasks. We propose a novel feature called Spatial cue-Augmented Log-SpectrogrAm (SALSA) with exact time-frequency mapping between the signal power and the source directional cues, which is crucial for resolving overlapping sound sources. The SALSA feature consists of multichannel log-spectrograms stacked along with the normalized principal eigenvector of the spatial covariance matrix at each corresponding time-frequency bin. Depending on the microphone array format, the principal eigenvector can be normalized differently to extract amplitude and/or phase differences between the microphones. As a result, SALSA features are applicable for different microphone array formats such as first-order ambisonics (FOA) and multichannel microphone array (MIC). Experimental results on the TAU-NIGENS Spatial Sound Events 2021 dataset with directional interferences showed that SALSA features outperformed other state-of-the-art features. Specifically, the use of SALSA features in the FOA format increased the F1 score and localization recall by 6% each, compared to the multichannel log-mel spectrograms with intensity vectors. For the MIC format, using SALSA features increased F1 score and localization recall by 16% and 7%, respectively, compared to using multichannel log-mel spectrograms with generalized cross-correlation spectra. Our ensemble model trained on SALSA features ranked second in the team category of the SELD task in the 2021 DCASE Challenge.
Improving Polyphonic Sound Event Detection on Multichannel Recordings with the Sørensen-Dice Coefficient Loss and Transfer Learning
Jul 22, 2021
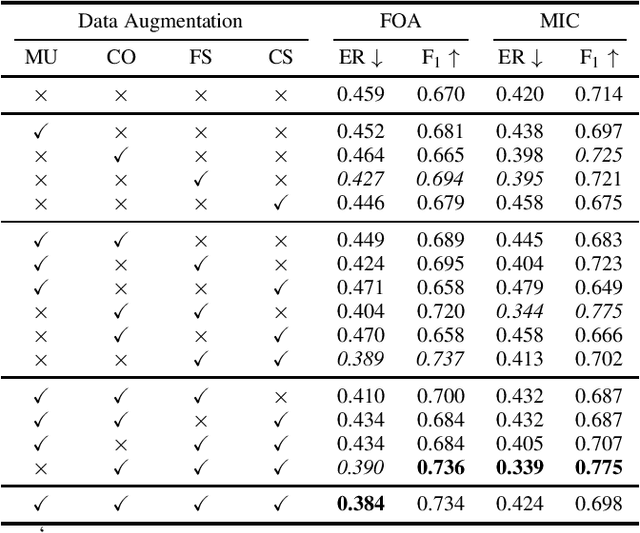
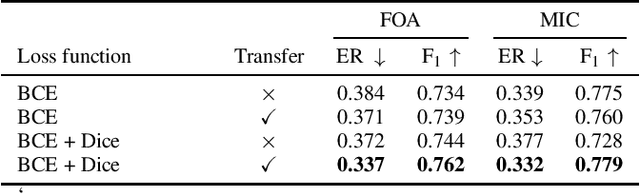

The S{\o}rensen--Dice Coefficient has recently seen rising popularity as a loss function (also known as Dice loss) due to its robustness in tasks where the number of negative samples significantly exceeds that of positive samples, such as semantic segmentation, natural language processing, and sound event detection. Conventional training of polyphonic sound event detection systems with binary cross-entropy loss often results in suboptimal detection performance as the training is often overwhelmed by updates from negative samples. In this paper, we investigated the effect of the Dice loss, intra- and inter-modal transfer learning, data augmentation, and recording formats, on the performance of polyphonic sound event detection systems with multichannel inputs. Our analysis showed that polyphonic sound event detection systems trained with Dice loss consistently outperformed those trained with cross-entropy loss across different training settings and recording formats in terms of F1 score and error rate. We achieved further performance gains via the use of transfer learning and an appropriate combination of different data augmentation techniques.
What Makes Sound Event Localization and Detection Difficult? Insights from Error Analysis
Jul 22, 2021
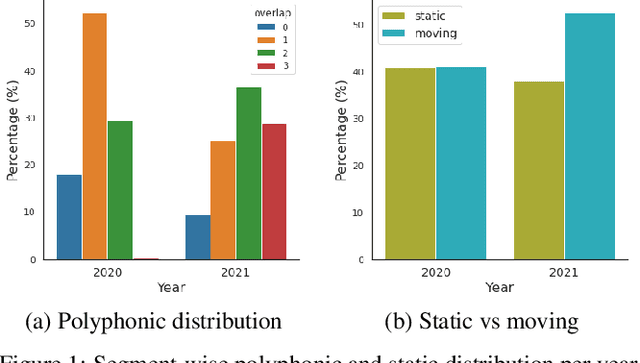
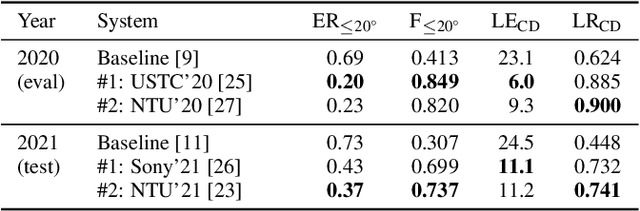
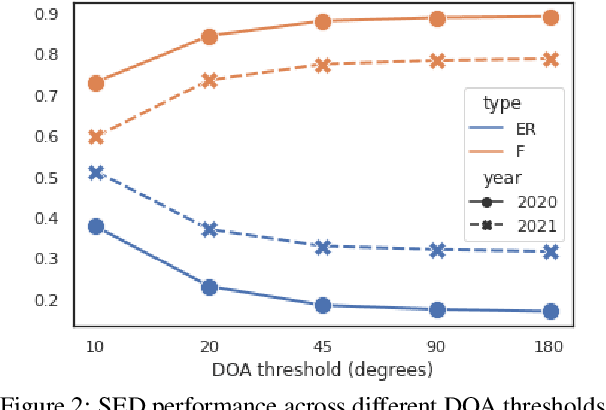
Sound event localization and detection (SELD) is an emerging research topic that aims to unify the tasks of sound event detection and direction-of-arrival estimation. As a result, SELD inherits the challenges of both tasks, such as noise, reverberation, interference, polyphony, and non-stationarity of sound sources. Furthermore, SELD often faces an additional challenge of assigning correct correspondences between the detected sound classes and directions of arrival to multiple overlapping sound events. Previous studies have shown that unknown interferences in reverberant environments often cause major degradation in the performance of SELD systems. To further understand the challenges of the SELD task, we performed a detailed error analysis on two of our SELD systems, which both ranked second in the team category of DCASE SELD Challenge, one in 2020 and one in 2021. Experimental results indicate polyphony as the main challenge in SELD, due to the difficulty in detecting all sound events of interest. In addition, the SELD systems tend to make fewer errors for the polyphonic scenario that is dominant in the training set.
DCASE 2021 Task 3: Spectrotemporally-aligned Features for Polyphonic Sound Event Localization and Detection
Jun 29, 2021
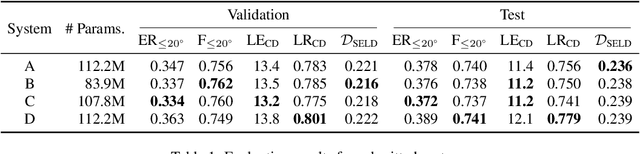
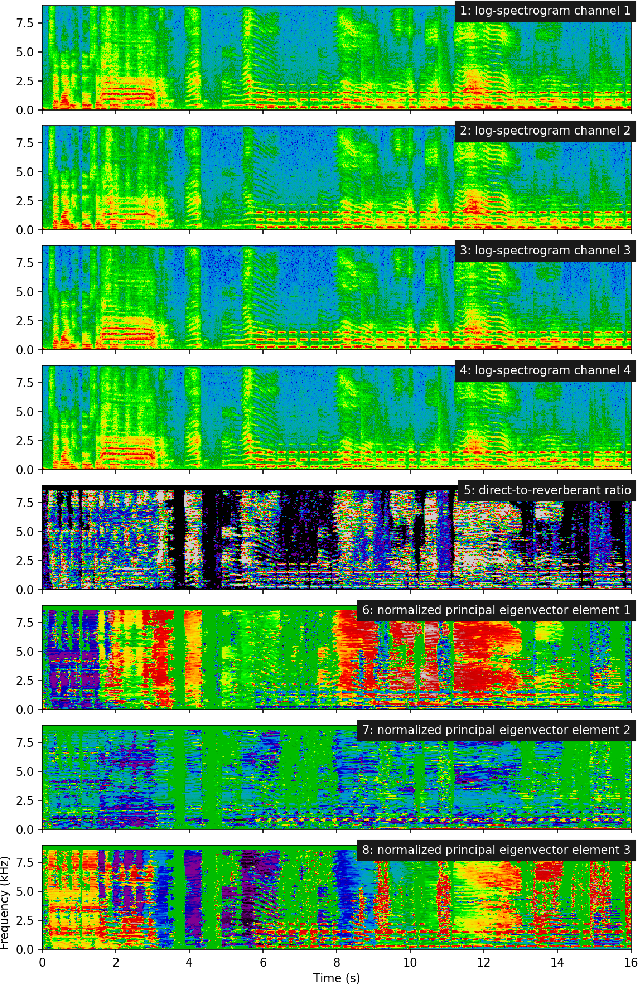
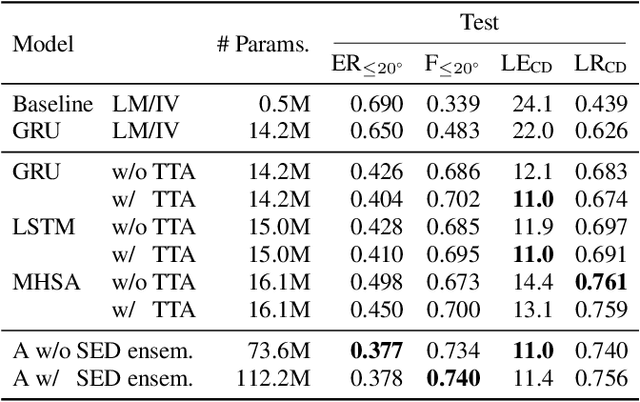
Sound event localization and detection consists of two subtasks which are sound event detection and direction-of-arrival estimation. While sound event detection mainly relies on time-frequency patterns to distinguish different sound classes, direction-of-arrival estimation uses magnitude or phase differences between microphones to estimate source directions. Therefore, it is often difficult to jointly train these two subtasks simultaneously. We propose a novel feature called spatial cue-augmented log-spectrogram (SALSA) with exact time-frequency mapping between the signal power and the source direction-of-arrival. The feature includes multichannel log-spectrograms stacked along with the estimated direct-to-reverberant ratio and a normalized version of the principal eigenvector of the spatial covariance matrix at each time-frequency bin on the spectrograms. Experimental results on the DCASE 2021 dataset for sound event localization and detection with directional interference showed that the deep learning-based models trained on this new feature outperformed the DCASE challenge baseline by a large margin. We combined several models with slightly different architectures that were trained on the new feature to further improve the system performances for the DCASE sound event localization and detection challenge.