 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Polyphonic Sound Event Detection on Multichannel Recordings with the Sørensen-Dice Coefficient Loss and Transfer Learning
Jul 22, 2021
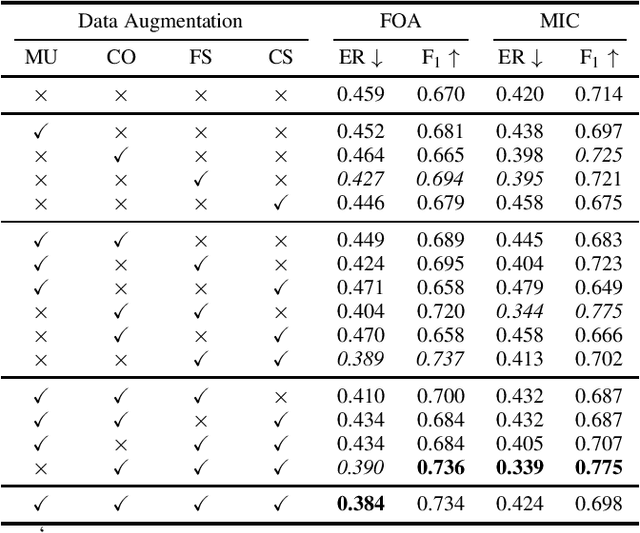
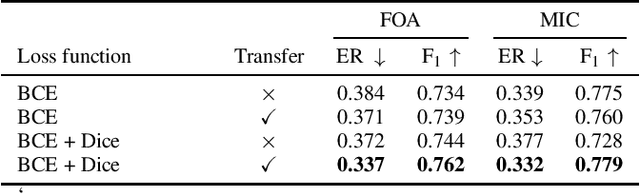

The S{\o}rensen--Dice Coefficient has recently seen rising popularity as a loss function (also known as Dice loss) due to its robustness in tasks where the number of negative samples significantly exceeds that of positive samples, such as semantic segmentation, natural language processing, and sound event detection. Conventional training of polyphonic sound event detection systems with binary cross-entropy loss often results in suboptimal detection performance as the training is often overwhelmed by updates from negative samples. In this paper, we investigated the effect of the Dice loss, intra- and inter-modal transfer learning, data augmentation, and recording formats, on the performance of polyphonic sound event detection systems with multichannel inputs. Our analysis showed that polyphonic sound event detection systems trained with Dice loss consistently outperformed those trained with cross-entropy loss across different training settings and recording formats in terms of F1 score and error rate. We achieved further performance gains via the use of transfer learning and an appropriate combination of different data augmentation techniques.
What Makes Sound Event Localization and Detection Difficult? Insights from Error Analysis
Jul 22, 2021
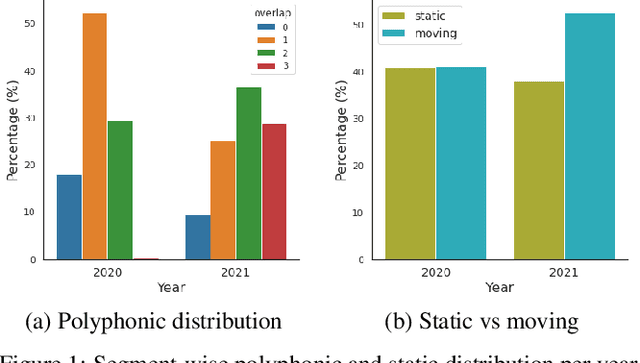
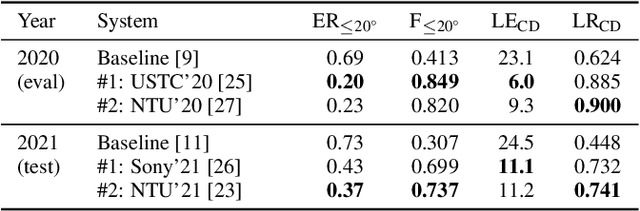
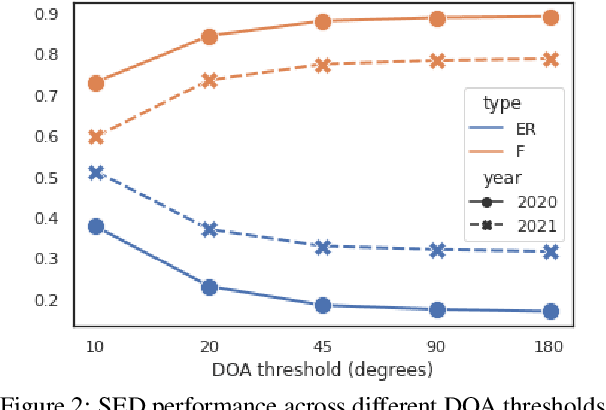
Sound event localization and detection (SELD) is an emerging research topic that aims to unify the tasks of sound event detection and direction-of-arrival estimation. As a result, SELD inherits the challenges of both tasks, such as noise, reverberation, interference, polyphony, and non-stationarity of sound sources. Furthermore, SELD often faces an additional challenge of assigning correct correspondences between the detected sound classes and directions of arrival to multiple overlapping sound events. Previous studies have shown that unknown interferences in reverberant environments often cause major degradation in the performance of SELD systems. To further understand the challenges of the SELD task, we performed a detailed error analysis on two of our SELD systems, which both ranked second in the team category of DCASE SELD Challenge, one in 2020 and one in 2021. Experimental results indicate polyphony as the main challenge in SELD, due to the difficulty in detecting all sound events of interest. In addition, the SELD systems tend to make fewer errors for the polyphonic scenario that is dominant in the training set.