 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCASE 2021 Task 3: Spectrotemporally-aligned Features for Polyphonic Sound Event Localization and Detection
Jun 29, 2021
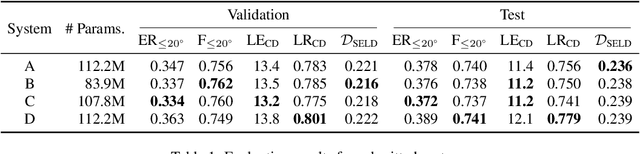
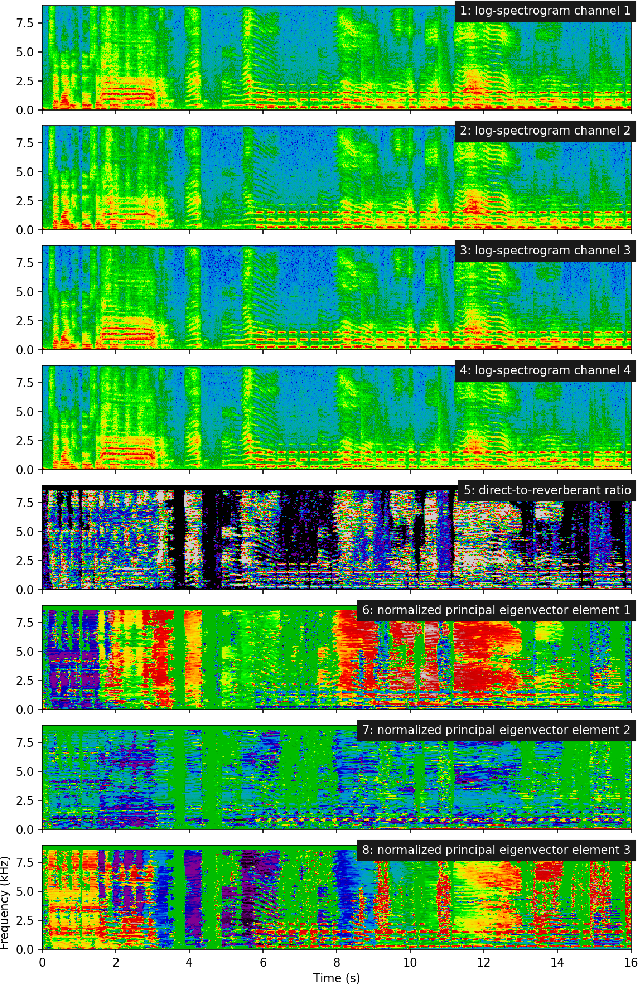
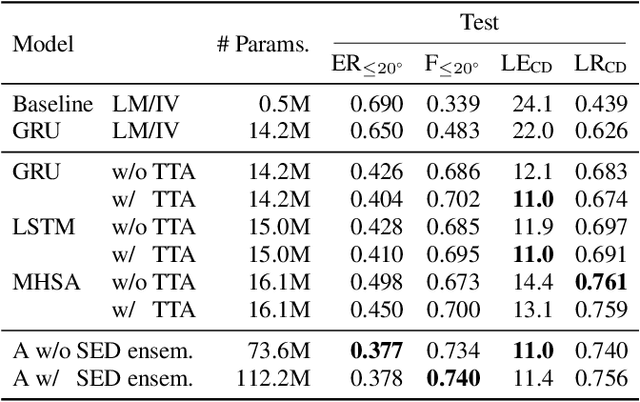
Sound event localization and detection consists of two subtasks which are sound event detection and direction-of-arrival estimation. While sound event detection mainly relies on time-frequency patterns to distinguish different sound classes, direction-of-arrival estimation uses magnitude or phase differences between microphones to estimate source directions. Therefore, it is often difficult to jointly train these two subtasks simultaneously. We propose a novel feature called spatial cue-augmented log-spectrogram (SALSA) with exact time-frequency mapping between the signal power and the source direction-of-arrival. The feature includes multichannel log-spectrograms stacked along with the estimated direct-to-reverberant ratio and a normalized version of the principal eigenvector of the spatial covariance matrix at each time-frequency bin on the spectrograms. Experimental results on the DCASE 2021 dataset for sound event localization and detection with directional interference showed that the deep learning-based models trained on this new feature outperformed the DCASE challenge baseline by a large margin. We combined several models with slightly different architectures that were trained on the new feature to further improve the system performances for the DCASE sound event localization and detection challenge.
Directional Sparse Filtering using Weighted Lehmer Mean for Blind Separation of Unbalanced Speech Mixtures
Feb 02, 2021
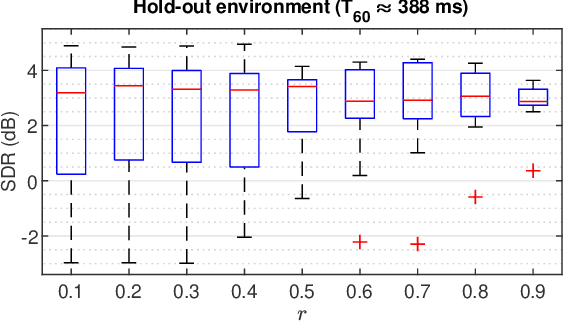
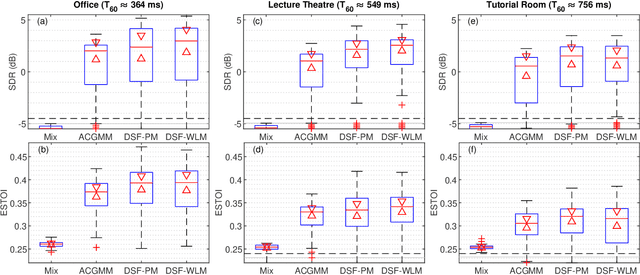
In blind source separation of speech signals, the inherent imbalance in the source spectrum poses a challenge for methods that rely on single-source dominance for the estimation of the mixing matrix. We propose an algorithm based on the directional sparse filtering (DSF) framework that utilizes the Lehmer mean with learnable weights to adaptively account for source imbalance. Performance evaluation in multiple real acoustic environments show improvements in source separation compared to the baseline methods.
Visual Attention for Musical Instrument Recognition
Jun 21, 2020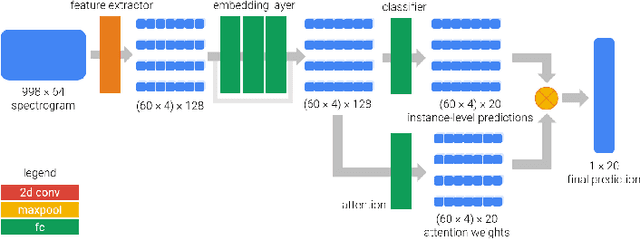
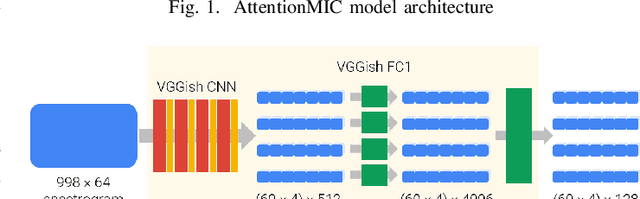
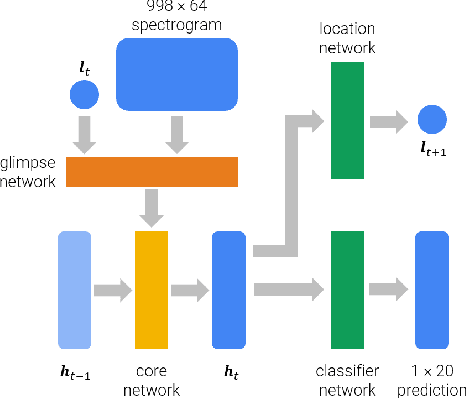
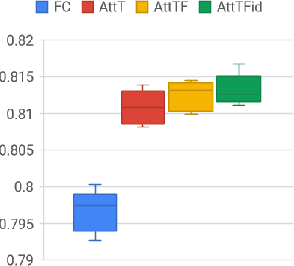
In the field of music information retrieval, the task of simultaneously identifying the presence or absence of multiple musical instruments in a polyphonic recording remains a hard problem. Previous works have seen some success in improving instrument classification by applying temporal attention in a multi-instance multi-label setting, while another series of work has also suggested the role of pitch and timbre in improving instrument recognition performance. In this project, we further explore the use of attention mechanism in a timbral-temporal sense, \`a la visual attention, to improve the performance of musical instrument recognition using weakly-labeled data. Two approaches to this task have been explored. The first approach applies attention mechanism to the sliding-window paradigm, where a prediction based on each timbral-temporal `instance' is given an attention weight, before aggregation to produce the final prediction. The second approach is based on a recurrent model of visual attention where the network only attends to parts of the spectrogram and decide where to attend to next, given a limited number of `glimpses'.