 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving performance of real-time full-band blind packet-loss concealment with predictive network
Nov 10, 2022Packet loss concealment (PLC) is a tool for enhancing speech degradation caused by poor network conditions or underflow/overflow in audio processing pipelines. We propose a real-time recurrent method that leverages previous outputs to mitigate artefact of lost packets without the prior knowledge of loss mask. The proposed full-band recurrent network (FRN) model operates at 48 kHz, which is suitable for high-quality telecommunication applications. Experiment results highlight the superiority of FRN over an offline non-causal baseline and a top performer in a recent PLC challenge.
TUNet: A Block-online Bandwidth Extension Model based on Transformers and Self-supervised Pretraining
Oct 26, 2021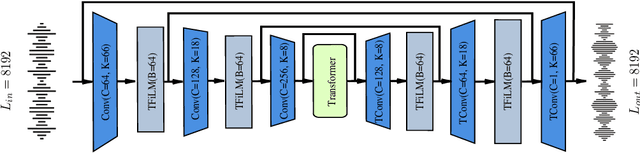

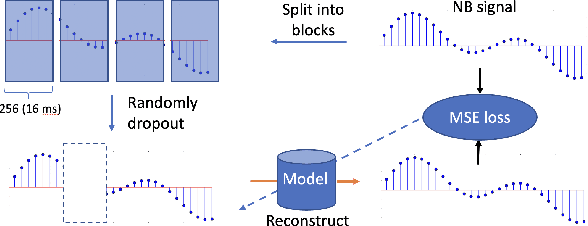
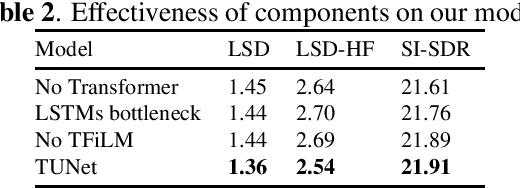
We introduce a block-online variant of the temporal feature-wise linear modulation (TFiLM) model to achieve bandwidth extension. The proposed architecture simplifies the UNet backbone of the TFiLM to reduce inference time and employs an efficient transformer at the bottleneck to alleviate performance degradation. We also utilize self-supervised pretraining and data augmentation to enhance the quality of bandwidth extended signals and reduce the sensitivity with respect to downsampling methods. Experiment results on the VCTK dataset show that the proposed method outperforms several recent baselines in terms of spectral distance and source-to-distortion ratio. Pretraining and filter augmentation also help stabilize and enhance the overall performance.
Directional Sparse Filtering using Weighted Lehmer Mean for Blind Separation of Unbalanced Speech Mixtures
Feb 02, 2021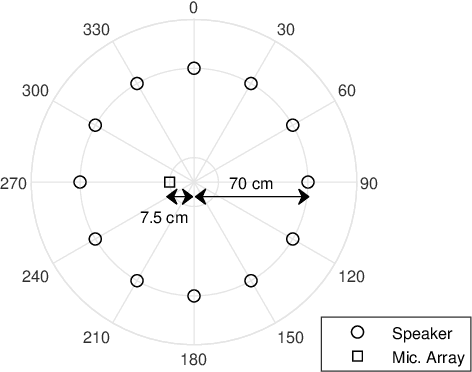
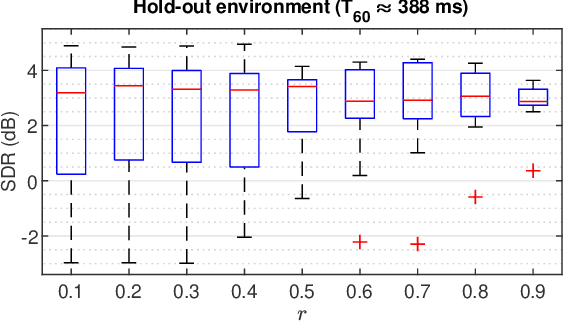
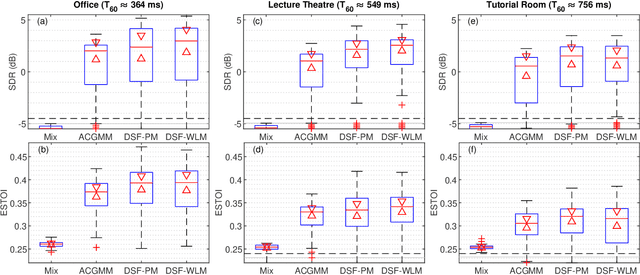
In blind source separation of speech signals, the inherent imbalance in the source spectrum poses a challenge for methods that rely on single-source dominance for the estimation of the mixing matrix. We propose an algorithm based on the directional sparse filtering (DSF) framework that utilizes the Lehmer mean with learnable weights to adaptively account for source imbalance. Performance evaluation in multiple real acoustic environments show improvements in source separation compared to the baseline methods.