 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer-LMR: Heavy-Tail Driving Behavior Recognition in Diverse Traffic Scenarios
May 08, 2024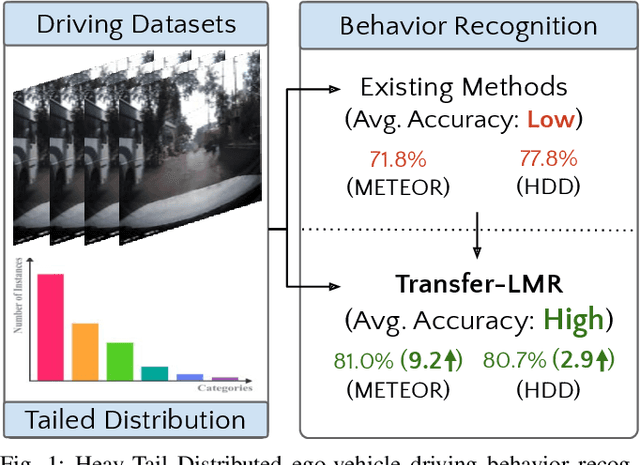
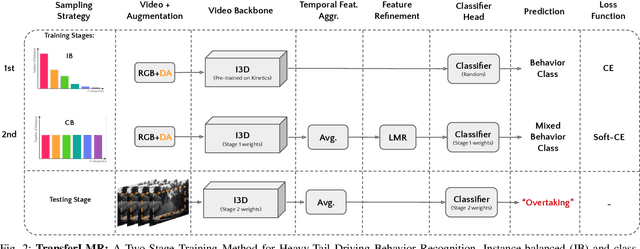
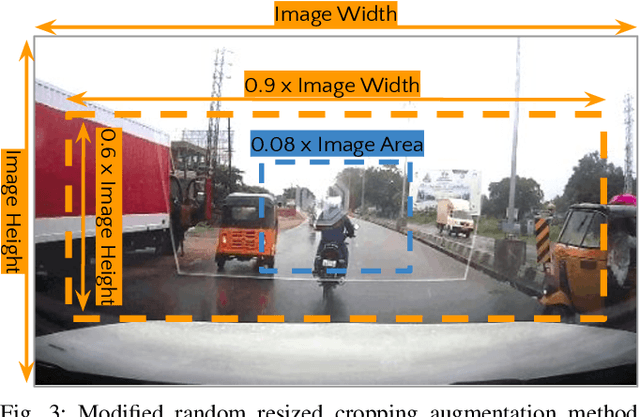

Recognizing driving behaviors is important for downstream tasks such as reasoning, planning, and navigation. Existing video recognition approaches work well for common behaviors (e.g. "drive straight", "brake", "turn left/right"). However, the performance is sub-par for underrepresented/rare behaviors typically found in tail of the behavior class distribution. To address this shortcoming, we propose Transfer-LMR, a modular training routine for improving the recognition performance across all driving behavior classes. We extensively evaluate our approach on METEOR and HDD datasets that contain rich yet heavy-tailed distribution of driving behaviors and span diverse traffic scenarios. The experimental results demonstrate the efficacy of our approach, especially for recognizing underrepresented/rare driving behaviors.
Scalable Approach for Normalizing E-commerce Text Attributes (SANTA)
Jun 12, 2021
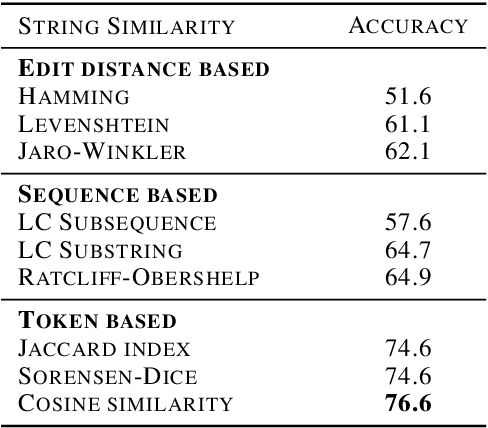
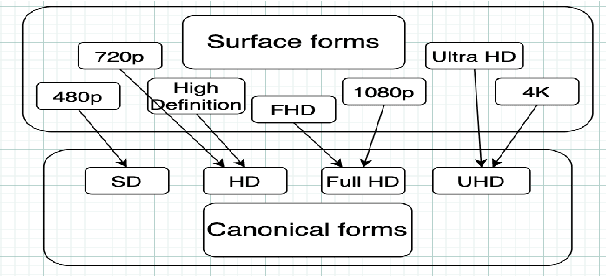

In this paper, we present SANTA, a scalable framework to automatically normalize E-commerce attribute values (e.g. "Win 10 Pro") to a fixed set of pre-defined canonical values (e.g. "Windows 10"). Earlier works on attribute normalization focused on fuzzy string matching (also referred as syntactic matching in this paper). In this work, we first perform an extensive study of nine syntactic matching algorithms and establish that 'cosine' similarity leads to best results, showing 2.7% improvement over commonly used Jaccard index. Next, we argue that string similarity alone is not sufficient for attribute normalization as many surface forms require going beyond syntactic matching (e.g. "720p" and "HD" are synonyms). While semantic techniques like unsupervised embeddings (e.g. word2vec/fastText) have shown good results in word similarity tasks, we observed that they perform poorly to distinguish between close canonical forms, as these close forms often occur in similar contexts. We propose to learn token embeddings using a twin network with triplet loss. We propose an embedding learning task leveraging raw attribute values and product titles to learn these embeddings in a self-supervised fashion. We show that providing supervision using our proposed task improves over both syntactic and unsupervised embeddings based techniques for attribute normalization. Experiments on a real-world attribute normalization dataset of 50 attributes show that the embeddings trained using our proposed approach obtain 2.3% improvement over best string matching and 19.3% improvement over best unsupervised embeddings.