 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoadSocial: A Diverse VideoQA Dataset and Benchmark for Road Event Understanding from Social Video Narratives
Mar 27, 2025
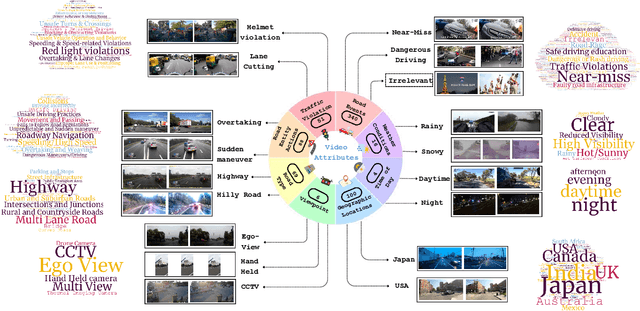
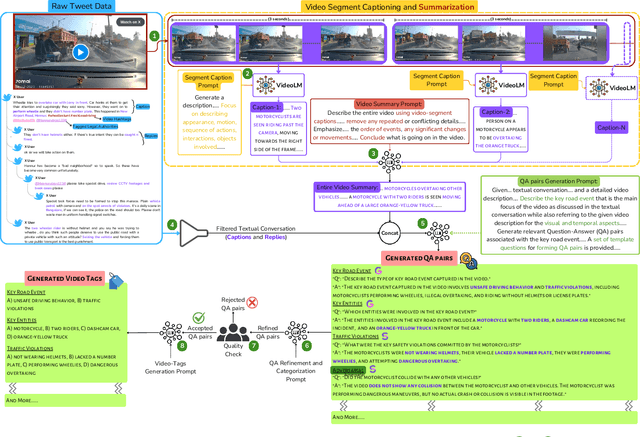
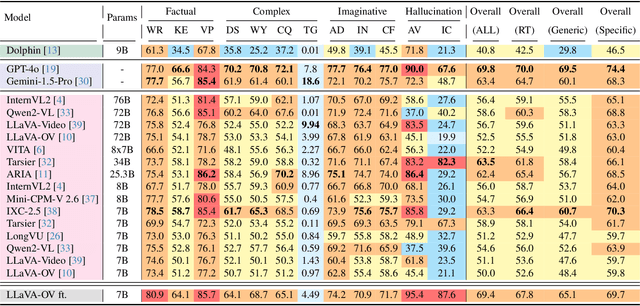
We introduce RoadSocial, a large-scale, diverse VideoQA dataset tailored for generic road event understanding from social media narratives. Unlike existing datasets limited by regional bias, viewpoint bias and expert-driven annotations, RoadSocial captures the global complexity of road events with varied geographies, camera viewpoints (CCTV, handheld, drones) and rich social discourse. Our scalable semi-automatic annotation framework leverages Text LLMs and Video LLMs to generate comprehensive question-answer pairs across 12 challenging QA tasks, pushing the boundaries of road event understanding. RoadSocial is derived from social media videos spanning 14M frames and 414K social comments, resulting in a dataset with 13.2K videos, 674 tags and 260K high-quality QA pairs. We evaluate 18 Video LLMs (open-source and proprietary, driving-specific and general-purpose) on our road event understanding benchmark. We also demonstrate RoadSocial's utility in improving road event understanding capabilities of general-purpose Video LLMs.
Transfer-LMR: Heavy-Tail Driving Behavior Recognition in Diverse Traffic Scenarios
May 08, 2024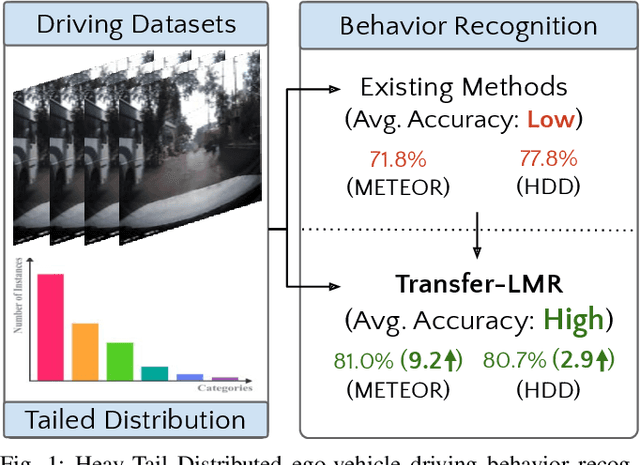
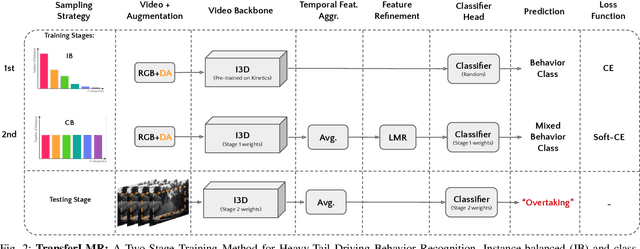

Recognizing driving behaviors is important for downstream tasks such as reasoning, planning, and navigation. Existing video recognition approaches work well for common behaviors (e.g. "drive straight", "brake", "turn left/right"). However, the performance is sub-par for underrepresented/rare behaviors typically found in tail of the behavior class distribution. To address this shortcoming, we propose Transfer-LMR, a modular training routine for improving the recognition performance across all driving behavior classes. We extensively evaluate our approach on METEOR and HDD datasets that contain rich yet heavy-tailed distribution of driving behaviors and span diverse traffic scenarios. The experimental results demonstrate the efficacy of our approach, especially for recognizing underrepresented/rare driving behaviors.
IDD-X: A Multi-View Dataset for Ego-relative Important Object Localization and Explanation in Dense and Unstructured Traffic
Apr 12, 2024Intelligent vehicle systems require a deep understanding of the interplay between road conditions, surrounding entities, and the ego vehicle's driving behavior for safe and efficient navigation. This is particularly critical in developing countries where traffic situations are often dense and unstructured with heterogeneous road occupants. Existing datasets, predominantly geared towards structured and sparse traffic scenarios, fall short of capturing the complexity of driving in such environments. To fill this gap, we present IDD-X, a large-scale dual-view driving video dataset. With 697K bounding boxes, 9K important object tracks, and 1-12 objects per video, IDD-X offers comprehensive ego-relative annotations for multiple important road objects covering 10 categories and 19 explanation label categories. The dataset also incorporates rearview information to provide a more complete representation of the driving environment. We also introduce custom-designed deep networks aimed at multiple important object localization and per-object explanation prediction. Overall, our dataset and introduced prediction models form the foundation for studying how road conditions and surrounding entities affect driving behavior in complex traffic situations.
A Fine-Grained Vehicle Detection Dataset for Unconstrained Roads
Dec 30, 2022


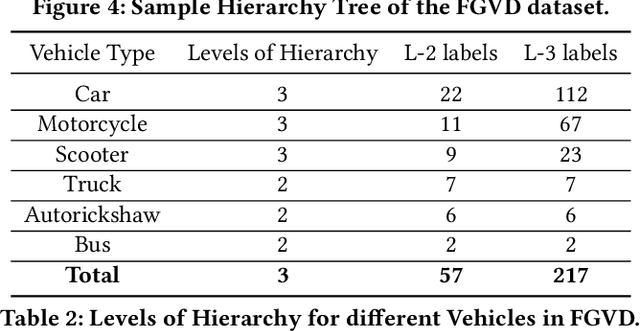
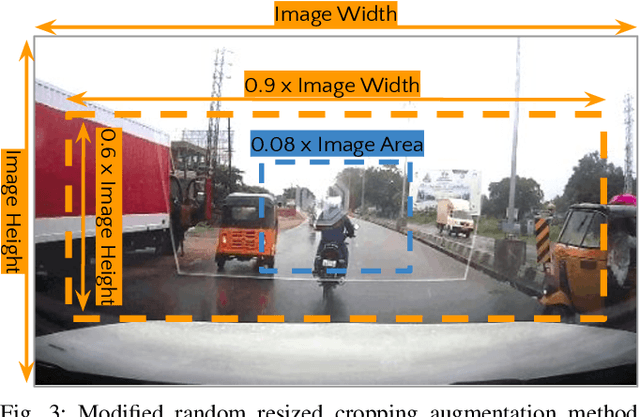
The previous fine-grained datasets mainly focus on classification and are often captured in a controlled setup, with the camera focusing on the objects. We introduce the first Fine-Grained Vehicle Detection (FGVD) dataset in the wild, captured from a moving camera mounted on a car. It contains 5502 scene images with 210 unique fine-grained labels of multiple vehicle types organized in a three-level hierarchy. While previous classification datasets also include makes for different kinds of cars, the FGVD dataset introduces new class labels for categorizing two-wheelers, autorickshaws, and trucks. The FGVD dataset is challenging as it has vehicles in complex traffic scenarios with intra-class and inter-class variations in types, scale, pose, occlusion, and lighting conditions. The current object detectors like yolov5 and faster RCNN perform poorly on our dataset due to a lack of hierarchical modeling. Along with providing baseline results for existing object detectors on FGVD Dataset, we also present the results of a combination of an existing detector and the recent Hierarchical Residual Network (HRN) classifier for the FGVD task. Finally, we show that FGVD vehicle images are the most challenging to classify among the fine-grained datasets.