 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINDIC DIALECT: A Multi Task Benchmark to Evaluate and Translate in Indian Language Dialects
Jan 15, 2026Recent NLP advances focus primarily on standardized languages, leaving most low-resource dialects under-served especially in Indian scenarios. In India, the issue is particularly important: despite Hindi being the third most spoken language globally (over 600 million speakers), its numerous dialects remain underrepresented. The situation is similar for Odia, which has around 45 million speakers. While some datasets exist which contain standard Hindi and Odia languages, their regional dialects have almost no web presence. We introduce INDIC-DIALECT, a human-curated parallel corpus of 13k sentence pairs spanning 11 dialects and 2 languages: Hindi and Odia. Using this corpus, we construct a multi-task benchmark with three tasks: dialect classification, multiple-choice question (MCQ) answering, and machine translation (MT). Our experiments show that LLMs like GPT-4o and Gemini 2.5 perform poorly on the classification task. While fine-tuned transformer based models pretrained on Indian languages substantially improve performance e.g., improving F1 from 19.6\% to 89.8\% on dialect classification. For dialect to language translation, we find that hybrid AI model achieves highest BLEU score of 61.32 compared to the baseline score of 23.36. Interestingly, due to complexity in generating dialect sentences, we observe that for language to dialect translation the ``rule-based followed by AI" approach achieves best BLEU score of 48.44 compared to the baseline score of 27.59. INDIC-DIALECT thus is a new benchmark for dialect-aware Indic NLP, and we plan to release it as open source to support further work on low-resource Indian dialects.
Improving Video Question Answering through query-based frame selection
Jan 12, 2026Video Question Answering (VideoQA) models enhance understanding and interaction with audiovisual content, making it more accessible, searchable, and useful for a wide range of fields such as education, surveillance, entertainment, and content creation. Due to heavy compute requirements, most large visual language models (VLMs) for VideoQA rely on a fixed number of frames by uniformly sampling the video. However, this process does not pick important frames or capture the context of the video. We present a novel query-based selection of frames relevant to the questions based on the submodular mutual Information (SMI) functions. By replacing uniform frame sampling with query-based selection, our method ensures that the chosen frames provide complementary and essential visual information for accurate VideoQA. We evaluate our approach on the MVBench dataset, which spans a diverse set of multi-action video tasks. VideoQA accuracy on this dataset was assessed using two VLMs, namely Video-LLaVA and LLaVA-NeXT, both of which originally employed uniform frame sampling. Experiments were conducted using both uniform and query-based sampling strategies. An accuracy improvement of up to \textbf{4\%} was observed when using query-based frame selection over uniform sampling. Qualitative analysis further highlights that query-based selection, using SMI functions, consistently picks frames better aligned with the question. We opine that such query-based frame selection can enhance accuracy in a wide range of tasks that rely on only a subset of video frames.
MorphTok: Morphologically Grounded Tokenization for Indian Languages
Apr 14, 2025



Tokenization is a crucial step in NLP, especially with the rise of large language models (LLMs), impacting downstream performance, computational cost, and efficiency. Existing LLMs rely on the classical Byte-pair Encoding (BPE) algorithm for subword tokenization that greedily merges frequent character bigrams. This often leads to segmentation that does not align with linguistically meaningful units. To address this, we propose morphology-aware segmentation as a pre-tokenization step prior to applying BPE. To facilitate morphology-aware segmentation, we create a novel dataset for Hindi and Marathi, incorporating sandhi splitting to enhance the subword tokenization. Experiments on downstream tasks show that morphologically grounded tokenization improves performance for machine translation and language modeling. Additionally, to handle the ambiguity in the Unicode characters for diacritics, particularly dependent vowels in syllable-based writing systems, we introduce Constrained BPE (CBPE), an extension to the traditional BPE algorithm that incorporates script-specific constraints. Specifically, CBPE handles dependent vowels. Our results show that CBPE achieves a 1.68\% reduction in fertility scores while maintaining comparable or improved downstream performance in machine translation, offering a computationally efficient alternative to standard BPE. Moreover, to evaluate segmentation across different tokenization algorithms, we introduce a new human evaluation metric, \textit{EvalTok}, enabling more human-grounded assessment.
IDD-X: A Multi-View Dataset for Ego-relative Important Object Localization and Explanation in Dense and Unstructured Traffic
Apr 12, 2024Intelligent vehicle systems require a deep understanding of the interplay between road conditions, surrounding entities, and the ego vehicle's driving behavior for safe and efficient navigation. This is particularly critical in developing countries where traffic situations are often dense and unstructured with heterogeneous road occupants. Existing datasets, predominantly geared towards structured and sparse traffic scenarios, fall short of capturing the complexity of driving in such environments. To fill this gap, we present IDD-X, a large-scale dual-view driving video dataset. With 697K bounding boxes, 9K important object tracks, and 1-12 objects per video, IDD-X offers comprehensive ego-relative annotations for multiple important road objects covering 10 categories and 19 explanation label categories. The dataset also incorporates rearview information to provide a more complete representation of the driving environment. We also introduce custom-designed deep networks aimed at multiple important object localization and per-object explanation prediction. Overall, our dataset and introduced prediction models form the foundation for studying how road conditions and surrounding entities affect driving behavior in complex traffic situations.
CueCAn: Cue Driven Contextual Attention For Identifying Missing Traffic Signs on Unconstrained Roads
Mar 05, 2023



Unconstrained Asian roads often involve poor infrastructure, affecting overall road safety. Missing traffic signs are a regular part of such roads. Missing or non-existing object detection has been studied for locating missing curbs and estimating reasonable regions for pedestrians on road scene images. Such methods involve analyzing task-specific single object cues. In this paper, we present the first and most challenging video dataset for missing objects, with multiple types of traffic signs for which the cues are visible without the signs in the scenes. We refer to it as the Missing Traffic Signs Video Dataset (MTSVD). MTSVD is challenging compared to the previous works in two aspects i) The traffic signs are generally not present in the vicinity of their cues, ii) The traffic signs cues are diverse and unique. Also, MTSVD is the first publicly available missing object dataset. To train the models for identifying missing signs, we complement our dataset with 10K traffic sign tracks, with 40 percent of the traffic signs having cues visible in the scenes. For identifying missing signs, we propose the Cue-driven Contextual Attention units (CueCAn), which we incorporate in our model encoder. We first train the encoder to classify the presence of traffic sign cues and then train the entire segmentation model end-to-end to localize missing traffic signs. Quantitative and qualitative analysis shows that CueCAn significantly improves the performance of base models.
A Fine-Grained Vehicle Detection Dataset for Unconstrained Roads
Dec 30, 2022


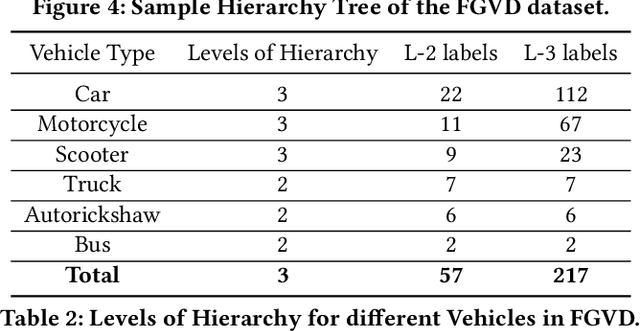
The previous fine-grained datasets mainly focus on classification and are often captured in a controlled setup, with the camera focusing on the objects. We introduce the first Fine-Grained Vehicle Detection (FGVD) dataset in the wild, captured from a moving camera mounted on a car. It contains 5502 scene images with 210 unique fine-grained labels of multiple vehicle types organized in a three-level hierarchy. While previous classification datasets also include makes for different kinds of cars, the FGVD dataset introduces new class labels for categorizing two-wheelers, autorickshaws, and trucks. The FGVD dataset is challenging as it has vehicles in complex traffic scenarios with intra-class and inter-class variations in types, scale, pose, occlusion, and lighting conditions. The current object detectors like yolov5 and faster RCNN perform poorly on our dataset due to a lack of hierarchical modeling. Along with providing baseline results for existing object detectors on FGVD Dataset, we also present the results of a combination of an existing detector and the recent Hierarchical Residual Network (HRN) classifier for the FGVD task. Finally, we show that FGVD vehicle images are the most challenging to classify among the fine-grained datasets.
Detecting, Tracking and Counting Motorcycle Rider Traffic Violations on Unconstrained Roads
Apr 18, 2022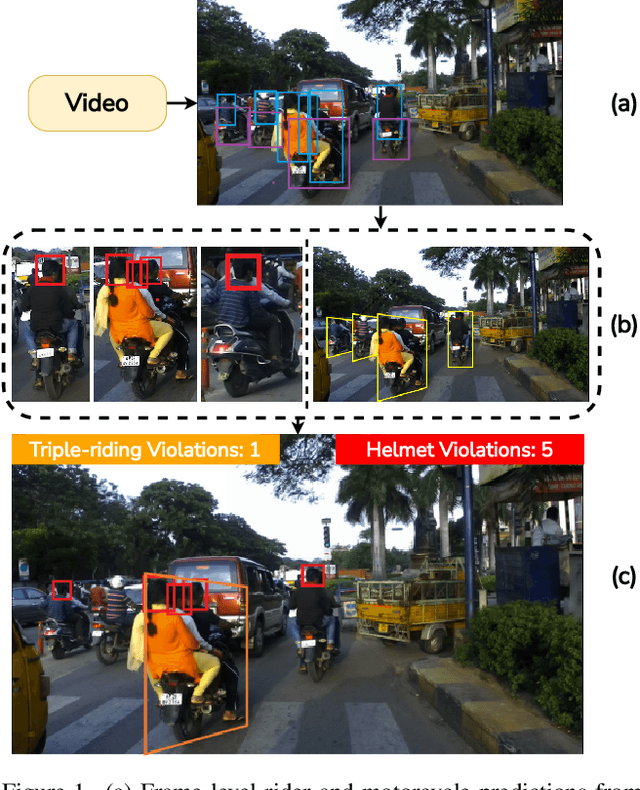
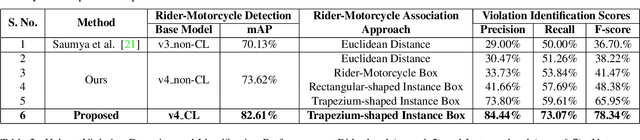
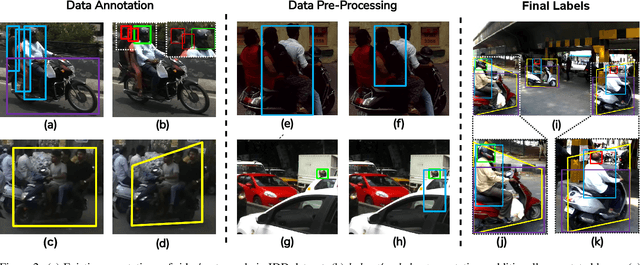
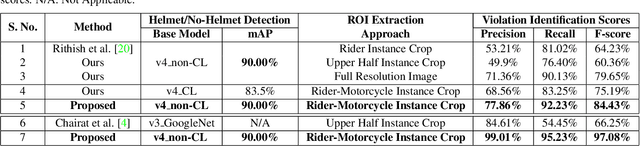
In many Asian countries with unconstrained road traffic conditions, driving violations such as not wearing helmets and triple-riding are a significant source of fatalities involving motorcycles. Identifying and penalizing such riders is vital in curbing road accidents and improving citizens' safety. With this motivation, we propose an approach for detecting, tracking, and counting motorcycle riding violations in videos taken from a vehicle-mounted dashboard camera. We employ a curriculum learning-based object detector to better tackle challenging scenarios such as occlusions. We introduce a novel trapezium-shaped object boundary representation to increase robustness and tackle the rider-motorcycle association. We also introduce an amodal regressor that generates bounding boxes for the occluded riders. Experimental results on a large-scale unconstrained driving dataset demonstrate the superiority of our approach compared to existing approaches and other ablative variants.
Automatic Quantification and Visualization of Street Trees
Jan 17, 2022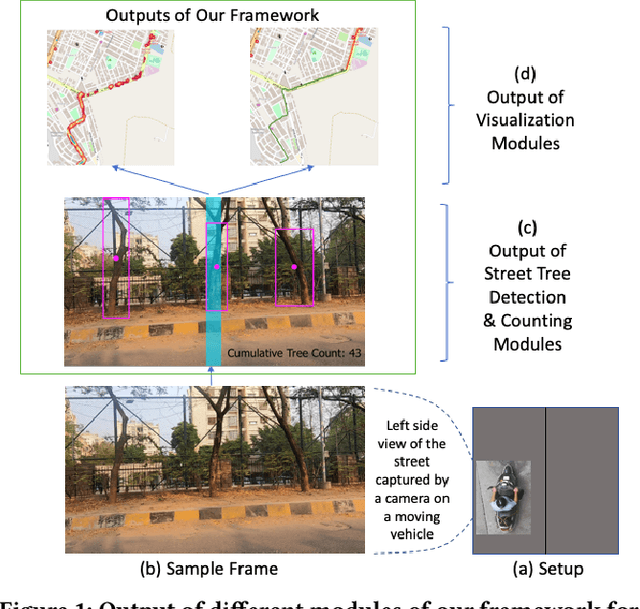

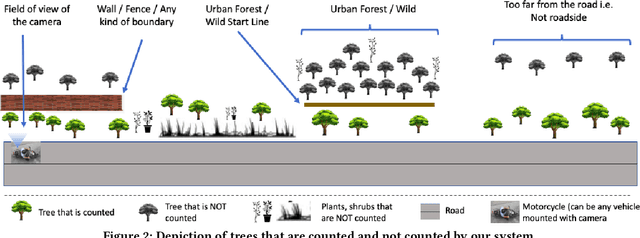
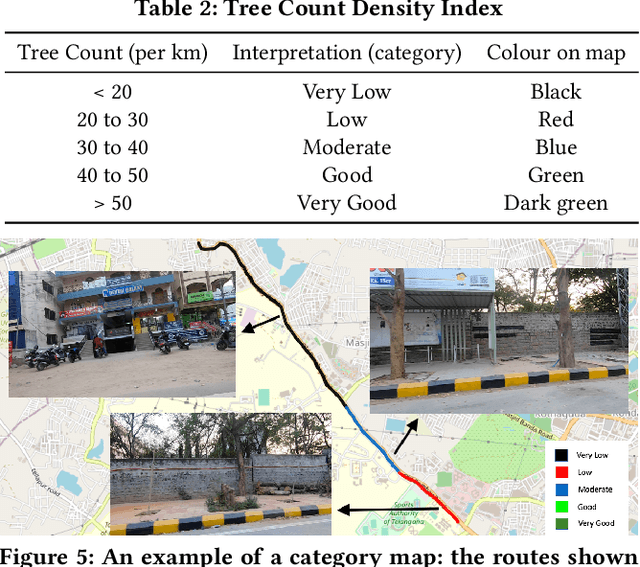
Assessing the number of street trees is essential for evaluating urban greenery and can help municipalities employ solutions to identify tree-starved streets. It can also help identify roads with different levels of deforestation and afforestation over time. Yet, there has been little work in the area of street trees quantification. This work first explains a data collection setup carefully designed for counting roadside trees. We then describe a unique annotation procedure aimed at robustly detecting and quantifying trees. We work on a dataset of around 1300 Indian road scenes annotated with over 2500 street trees. We additionally use the five held-out videos covering 25 km of roads for counting trees. We finally propose a street tree detection, counting, and visualization framework using current object detectors and a novel yet simple counting algorithm owing to the thoughtful collection setup. We find that the high-level visualizations based on the density of trees on the routes and Kernel Density Ranking (KDR) provide a quick, accurate, and inexpensive way to recognize tree-starved streets. We obtain a tree detection mAP of 83.74% on the test images, which is a 2.73% improvement over our baseline. We propose Tree Count Density Classification Accuracy (TCDCA) as an evaluation metric to measure tree density. We obtain TCDCA of 96.77% on the test videos, with a remarkable improvement of 22.58% over baseline, and demonstrate that our counting module's performance is close to human level. Source code: https://github.com/iHubData-Mobility/public-tree-counting.
Towards Boosting the Accuracy of Non-Latin Scene Text Recognition
Jan 10, 2022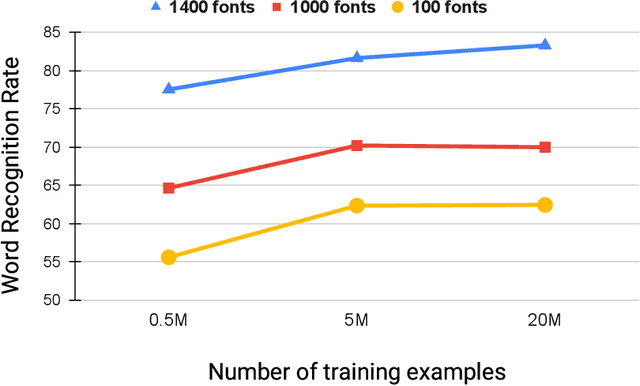

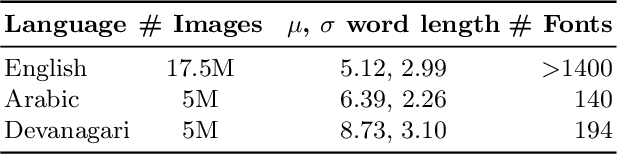

Scene-text recognition is remarkably better in Latin languages than the non-Latin languages due to several factors like multiple fonts, simplistic vocabulary statistics, updated data generation tools, and writing systems. This paper examines the possible reasons for low accuracy by comparing English datasets with non-Latin languages. We compare various features like the size (width and height) of the word images and word length statistics. Over the last decade, generating synthetic datasets with powerful deep learning techniques has tremendously improved scene-text recognition. Several controlled experiments are performed on English, by varying the number of (i) fonts to create the synthetic data and (ii) created word images. We discover that these factors are critical for the scene-text recognition systems. The English synthetic datasets utilize over 1400 fonts while Arabic and other non-Latin datasets utilize less than 100 fonts for data generation. Since some of these languages are a part of different regions, we garner additional fonts through a region-based search to improve the scene-text recognition models in Arabic and Devanagari. We improve the Word Recognition Rates (WRRs) on Arabic MLT-17 and MLT-19 datasets by 24.54% and 2.32% compared to previous works or baselines. We achieve WRR gains of 7.88% and 3.72% for IIIT-ILST and MLT-19 Devanagari datasets.
* 12 pages, 6 figures
Transfer Learning for Scene Text Recognition in Indian Languages
Jan 10, 2022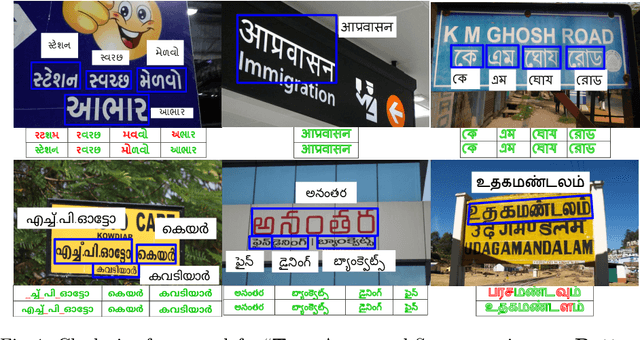
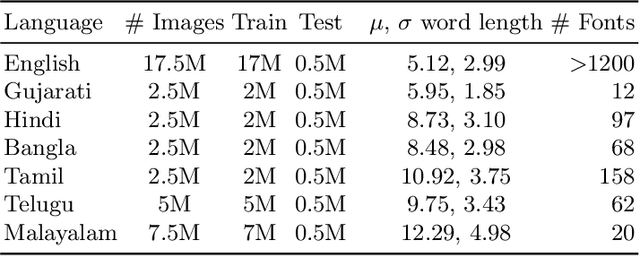

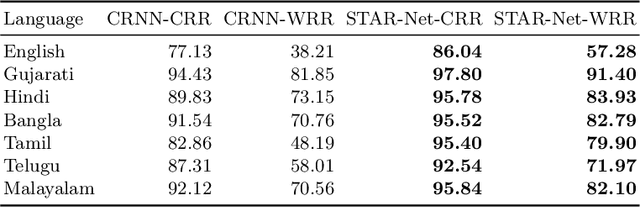
Scene text recognition in low-resource Indian languages is challenging because of complexities like multiple scripts, fonts, text size, and orientations. In this work, we investigate the power of transfer learning for all the layers of deep scene text recognition networks from English to two common Indian languages. We perform experiments on the conventional CRNN model and STAR-Net to ensure generalisability. To study the effect of change in different scripts, we initially run our experiments on synthetic word images rendered using Unicode fonts. We show that the transfer of English models to simple synthetic datasets of Indian languages is not practical. Instead, we propose to apply transfer learning techniques among Indian languages due to similarity in their n-gram distributions and visual features like the vowels and conjunct characters. We then study the transfer learning among six Indian languages with varying complexities in fonts and word length statistics. We also demonstrate that the learned features of the models transferred from other Indian languages are visually closer (and sometimes even better) to the individual model features than those transferred from English. We finally set new benchmarks for scene-text recognition on Hindi, Telugu, and Malayalam datasets from IIIT-ILST and Bangla dataset from MLT-17 by achieving 6%, 5%, 2%, and 23% gains in Word Recognition Rates (WRRs) compared to previous works. We further improve the MLT-17 Bangla results by plugging in a novel correction BiLSTM into our model. We additionally release a dataset of around 440 scene images containing 500 Gujarati and 2535 Tamil words. WRRs improve over the baselines by 8%, 4%, 5%, and 3% on the MLT-19 Hindi and Bangla datasets and the Gujarati and Tamil datasets.
* 16 pages, 5 figures