 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePINGALA: Prosody-Aware Decoding for Sanskrit Poetry Generation
Mar 25, 2026Poetry generation in Sanskrit typically requires the verse to be semantically coherent and adhere to strict prosodic rules. In Sanskrit prosody, every line of a verse is typically a fixed length sequence of syllables adhering to prescribed binary patterns of syllable weights. We observe that instead of treating a verse as a monolithic sequence, segmenting them as grouped-lines leads to significant improvement in semantic coherence by 10\% with comparable metrical adherence. Specifically, PINGALA, our proposed decoding approach is designed to encourage every line to have well-formed words and our token selection biases the model towards it by preferring longer tokens. Writing in Sanskrit follows phonemic orthography, hence using a phonetically aware transliteration scheme, SLP1, increased the metrical alignment by 46\% with comparable semantic similarity, for a instruction fine-tuned large language models like Phi-4. We also introduce a new approach for reference-free evaluation using cross-encoders which achieved better alignment with true poetry instances.
MorphTok: Morphologically Grounded Tokenization for Indian Languages
Apr 14, 2025



Tokenization is a crucial step in NLP, especially with the rise of large language models (LLMs), impacting downstream performance, computational cost, and efficiency. Existing LLMs rely on the classical Byte-pair Encoding (BPE) algorithm for subword tokenization that greedily merges frequent character bigrams. This often leads to segmentation that does not align with linguistically meaningful units. To address this, we propose morphology-aware segmentation as a pre-tokenization step prior to applying BPE. To facilitate morphology-aware segmentation, we create a novel dataset for Hindi and Marathi, incorporating sandhi splitting to enhance the subword tokenization. Experiments on downstream tasks show that morphologically grounded tokenization improves performance for machine translation and language modeling. Additionally, to handle the ambiguity in the Unicode characters for diacritics, particularly dependent vowels in syllable-based writing systems, we introduce Constrained BPE (CBPE), an extension to the traditional BPE algorithm that incorporates script-specific constraints. Specifically, CBPE handles dependent vowels. Our results show that CBPE achieves a 1.68\% reduction in fertility scores while maintaining comparable or improved downstream performance in machine translation, offering a computationally efficient alternative to standard BPE. Moreover, to evaluate segmentation across different tokenization algorithms, we introduce a new human evaluation metric, \textit{EvalTok}, enabling more human-grounded assessment.
Towards More Relevant Product Search Ranking Via Large Language Models: An Empirical Study
Sep 26, 2024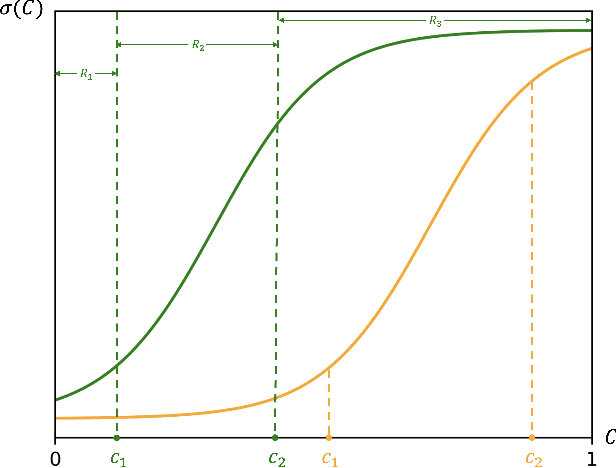

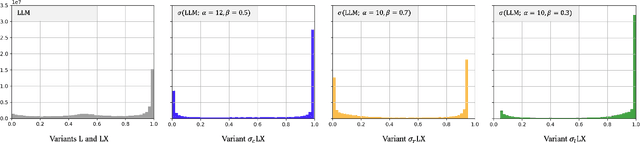
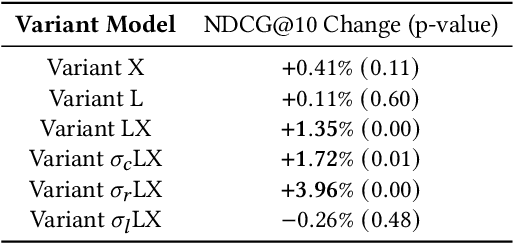
Training Learning-to-Rank models for e-commerce product search ranking can be challenging due to the lack of a gold standard of ranking relevance. In this paper, we decompose ranking relevance into content-based and engagement-based aspects, and we propose to leverage Large Language Models (LLMs) for both label and feature generation in model training, primarily aiming to improve the model's predictive capability for content-based relevance. Additionally, we introduce different sigmoid transformations on the LLM outputs to polarize relevance scores in labeling, enhancing the model's ability to balance content-based and engagement-based relevances and thus prioritize highly relevant items overall. Comprehensive online tests and offline evaluations are also conducted for the proposed design. Our work sheds light on advanced strategies for integrating LLMs into e-commerce product search ranking model training, offering a pathway to more effective and balanced models with improved ranking relevance.
Long or Short or Both? An Exploration on Lookback Time Windows of Behavioral Features in Product Search Ranking
Sep 26, 2024



Customer shopping behavioral features are core to product search ranking models in eCommerce. In this paper, we investigate the effect of lookback time windows when aggregating these features at the (query, product) level over history. By studying the pros and cons of using long and short time windows, we propose a novel approach to integrating these historical behavioral features of different time windows. In particular, we address the criticality of using query-level vertical signals in ranking models to effectively aggregate all information from different behavioral features. Anecdotal evidence for the proposed approach is also provided using live product search traffic on Walmart.com.
SuryaKiran at MEDIQA-Sum 2023: Leveraging LoRA for Clinical Dialogue Summarization
Jul 11, 2023
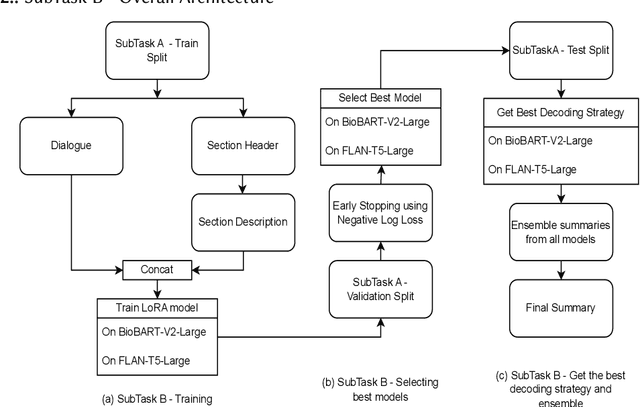
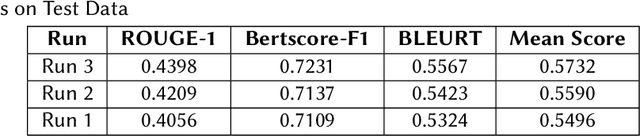
Finetuning Large Language Models helps improve the results for domain-specific use cases. End-to-end finetuning of large language models is time and resource intensive and has high storage requirements to store the finetuned version of the large language model. Parameter Efficient Fine Tuning (PEFT) methods address the time and resource challenges by keeping the large language model as a fixed base and add additional layers, which the PEFT methods finetune. This paper demonstrates the evaluation results for one such PEFT method Low Rank Adaptation (LoRA), for Clinical Dialogue Summarization. The evaluation results show that LoRA works at par with end-to-end finetuning for a large language model. The paper presents the evaluations done for solving both the Subtask A and B from ImageCLEFmedical {https://www.imageclef.org/2023/medical}
Language Models sounds the Death Knell of Knowledge Graphs
Jan 10, 2023



Healthcare domain generates a lot of unstructured and semi-structured text. Natural Language processing (NLP) has been used extensively to process this data. Deep Learning based NLP especially Large Language Models (LLMs) such as BERT have found broad acceptance and are used extensively for many applications. A Language Model is a probability distribution over a word sequence. Self-supervised Learning on a large corpus of data automatically generates deep learning-based language models. BioBERT and Med-BERT are language models pre-trained for the healthcare domain. Healthcare uses typical NLP tasks such as question answering, information extraction, named entity recognition, and search to simplify and improve processes. However, to ensure robust application of the results, NLP practitioners need to normalize and standardize them. One of the main ways of achieving normalization and standardization is the use of Knowledge Graphs. A Knowledge Graph captures concepts and their relationships for a specific domain, but their creation is time-consuming and requires manual intervention from domain experts, which can prove expensive. SNOMED CT (Systematized Nomenclature of Medicine -- Clinical Terms), Unified Medical Language System (UMLS), and Gene Ontology (GO) are popular ontologies from the healthcare domain. SNOMED CT and UMLS capture concepts such as disease, symptoms and diagnosis and GO is the world's largest source of information on the functions of genes. Healthcare has been dealing with an explosion in information about different types of drugs, diseases, and procedures. This paper argues that using Knowledge Graphs is not the best solution for solving problems in this domain. We present experiments using LLMs for the healthcare domain to demonstrate that language models provide the same functionality as knowledge graphs, thereby making knowledge graphs redundant.